Big Table and Small Table Join strategy in Oracle
Big Table and Small Table Join strategy in Oracle
The optimizer usesnested loop joins when joining small number of rows, with a good drivingcondition between the two tables. You drive from the outer loop to the innerloop, so the order of tables in the execution plan is important.
The outer loop isthe driving row source. It produces a set of rows for driving the joincondition. The row source can be a table accessed using an index scan or a fulltable scan. Also, the rows can be produced from any other operation. Forexample, the output from a nested loop join can be used as a row source for anothernested loop join.
The inner loop isiterated for every row returned from the outer loop, ideally by an index scan.If the access path for the inner loop is not dependent on the outer loop, thenyou can end up with a Cartesian product; for every iteration of the outer loop,the inner loop produces the same set of rows. Therefore, you should use other joinmethods when two independent row sources are joined together.
The following noworkload system statistics will be used:
SELECT
PNAME,
PVAL1
FROM
SYS.AUX_STATS$
ORDER BY
PNAME;
PNAME PVAL1
--------------- ----------
CPUSPEED
CPUSPEEDNW 2116.57559
DSTART
DSTOP
FLAGS 1
IOSEEKTIM 10
IOTFRSPEED 4096
MAXTHR
MBRC
MREADTIM
SLAVETHR
SREADTIM
STATUS
First the tables. We will start simple, with one table(T3) having 100 rows and another table (T4) having 10 rows:
CREATE TABLE T3 (
C1 NUMBER,
C2 NUMBER,
C3 NUMBER,
C4 VARCHAR2(20),
PADDING VARCHAR2(200));
CREATE TABLE T4 (
C1 NUMBER,
C2 NUMBER,
C3 NUMBER,
C4 VARCHAR2(20),
PADDING VARCHAR2(200));
INSERT INTO
T3
SELECT
ROWNUM C1,
1000000-ROWNUM C2,
MOD(ROWNUM-1,1000) C3,
TO_CHAR(SYSDATE+MOD(ROWNUM-1,10000),'DAY') C4,
LPAD(' ',200,'A') PADDING
FROM
DUAL
CONNECT BY
LEVEL<=100;
INSERT INTO
T4
SELECT
ROWNUM C1,
1000000-ROWNUM C2,
MOD(ROWNUM-1,1000) C3,
TO_CHAR(SYSDATE+MOD(ROWNUM-1,10000),'DAY') C4,
LPAD(' ',200,'A') PADDING
FROM
DUAL
CONNECT BY
LEVEL<=10;
COMMIT;
CREATE INDEX IND_T3_C1 ON T3(C1);
CREATE INDEX IND_T3_C2 ON T3(C2);
CREATE INDEX IND_T3_C3 ON T3(C3);
CREATE INDEX IND_T4_C1 ON T4(C1);
CREATE INDEX IND_T4_C2 ON T4(C2);
CREATE INDEX IND_T4_C3 ON T4(C3);
EXEC DBMS_STATS.GATHER_TABLE_STATS(OWNNAME=>USER,TABNAME=>'T3',CASCADE=>TRUE,ESTIMATE_PERCENT=>NULL)
EXEC DBMS_STATS.GATHER_TABLE_STATS(OWNNAME=>USER,TABNAME=>'T4',CASCADE=>TRUE,ESTIMATE_PERCENT=>NULL)
We are able to easily produce an example where the “smallest”table is selected as the driving table (note that I had to add a hint tospecify a nested loop join in several of these examples):
SET AUTOTRACE TRACEONLY EXPLAIN
SELECT /*+ USE_NL(T3 T4) */
T3.C1,
T3.C2,
T3.C3,
T3.C4,
T4.C1,
T4.C2,
T4.C3,
T4.C4
FROM
T3,
T4
WHERE
T3.C1=T4.C1;
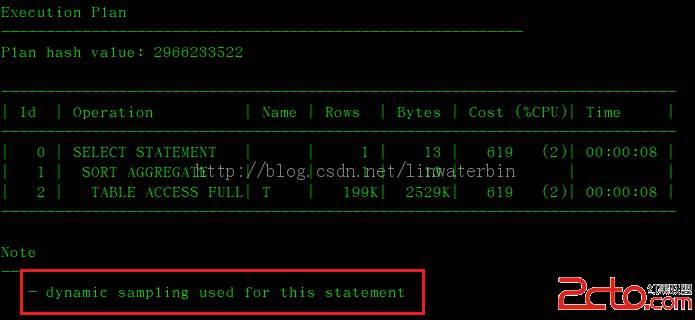
Execution Plan
----------------------------------------------------------
Plan hash value: 567778651
------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 10 | 420 | 13 (0)| 00:00:01 |
| 1 | NESTED LOOPS | | | | | |
| 2 | NESTED LOOPS | | 10 | 420 | 13 (0)| 00:00:01 |
| 3 | TABLE ACCESS FULL | T4 | 10 | 210 | 3 (0)| 00:00:01 |
|* 4 | INDEX RANGE SCAN | IND_T3_C1 | 1 | | 0 (0)| 00:00:01 |
| 5 | TABLE ACCESS BY INDEX ROWID| T3 | 1 | 21 | 1 (0)| 00:00:01 |
------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
4 - access("T3"."C1"="T4"."C1")
If we stop at that point, we could declare quite simply that theoptimizer selects the smaller table as the driving table. But wait aminute, take a look at this example where the optimizer selected the largesttable as the driving table:
SELECT /*+ USE_NL(T3 T4) */
T3.C1,
T3.C2,
T3.C3,
T3.C4,
T4.C1,
T4.C2,
T4.C3,
T4.C4
FROM
T3,
T4
WHERE
T3.C1=T4.C1
AND T3.C2=1;
Execution Plan
----------------------------------------------------------
Plan hash value: 4214127300
-------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 |