当前位置:编程学习 > php >>
答案: 一、 基础知识
本章简要介绍一些Zend引擎的内部机制,这些知识和Extensions密切相关,同时也可以帮助我们写出更加高效的PHP代码。
1.1 PHP变量的存储
1.1.1 zval结构
Zend使用zval结构来存储PHP变量的值,该结构如下所示:复制代码 代码如下:
typedef union _zvalue_value {
long lval; /* long value */
double dval; /* double value */
struct {
char *val;
int len;
} str;
HashTable *ht; /* hash table value */
zend_object_value obj;
} zvalue_value;
struct _zval_struct {
/* Variable information */
zvalue_value value; /* value */
zend_uint refcount;
zend_uchar type; /* active type */
zend_uchar is_ref;
};
typedef struct _zval_struct zval;
<span id="more-597"></span>Zend根据type值来决定访问value的哪个成员,可用值如下:
IS_NULLN/A
IS_LONG对应value.lval
IS_DOUBLE对应value.dval
IS_STRING对应value.str
IS_ARRAY对应value.ht
IS_OBJECT对应value.obj
IS_BOOL对应value.lval.
IS_RESOURCE对应value.lval
根据这个表格可以发现两个有意思的地方:首先是PHP的数组其实就是一个HashTable,这就解释了为什么PHP能够支持关联数组了;其次,Resource就是一个long值,它里面存放的通常是个指针、一个内部数组的index或者其它什么只有创建者自己才知道的东西,可以将其视作一个handle
1.1.1 引用计数
引用计数在垃圾收集、内存池以及字符串等地方应用广泛,Zend就实现了典型的引用计数。多个PHP变量可以通过引用计数机制来共享同一份zval,zval中剩余的两个成员is_ref和refcount就用来支持这种共享。
很明显,refcount用于计数,当增减引用时,这个值也相应的递增和递减,一旦减到零,Zend就会回收该zval。
那么is_ref呢?
1.1.2 zval状态
在PHP中,变量有两种——引用和非引用的,它们在Zend中都是采用引用计数的方式存储的。对于非引用型变量,要求变量间互不相干,修改一个变量时,不能影响到其他变量,采用Copy-On-Write机制即可解决这种冲突——当试图写入一个变量时,Zend若发现该变量指向的zval被多个变量共享,则为其复制一份refcount为1的zval,并递减原zval的refcount,这个过程称为“zval分离”。然而,对于引用型变量,其要求和非引用型相反,引用赋值的变量间必须是捆绑的,修改一个变量就修改了所有捆绑变量。
可见,有必要指出当前zval的状态,以分别应对这两种情况,is_ref就是这个目的,它指出了当前所有指向该zval的变量是否是采用引用赋值的——要么全是引用,要么全不是。此时再修改一个变量,只有当发现其zval的is_ref为0,即非引用时,Zend才会执行Copy-On-Write。
1.1.3 zval状态切换
当在一个zval上进行的所有赋值操作都是引用或者都是非引用时,一个is_ref就足够应付了。然而,世界总不会那么美好,PHP无法对用户进行这种限制,当我们混合使用引用和非引用赋值时,就必须要进行特别处理了。
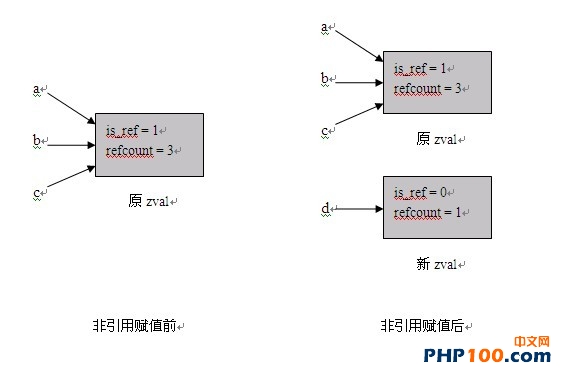
情况I、看如下PHP代码:
<!--p $a = 1; $b = &$a; $c = &$b; $d = $c; // 在一堆引用赋值中,插入一个非引用-->
全过程如下所示:
这段代码的前三句将把a、b和c指向一个zval,其is_ref=1, refcount=3;第四句是个非引用赋值,通常情况下只需要增加引用计数即可,然而目标zval属于引用变量,单纯的增加引用计数显然是错误的, Zend的解决办法是为d单独生成一份zval副本。
全过程如下所示:
1.1.1 参数传递
PHP函数参数的传递和变量赋值是一样的,非引用传递相当于非引用赋值,引用传递相当于引用赋值,并且也有可能会导致执行zval状态切换。这在后面还将提到。
1.2 HashTable结构
HashTable是Zend引擎中最重要、使用最广泛的数据结构,它被用来存储几乎所有的东西。
1.1.1 数据结构
HashTable数据结构定义如下:复制代码 代码如下:
typedef struct bucket {
ulong h; // 存放hash
uint nKeyLength;
void *pData; // 指向value,是用户数据的副本
void *pDataPtr;
struct bucket *pListNext; // pListNext和pListLast组成
struct bucket *pListLast; // 整个HashTable的双链表
struct bucket *pNext; // pNext和pLast用于组成某个hash对应
struct bucket *pLast; // 的双链表
char arKey[1]; // key
} Bucket;
typedef struct _hashtable {
uint nTableSize;
uint nTableMask;
uint nNumOfElements;
ulong nNextFreeElement;
Bucket *pInternalPointer; /* Used for element traversal */
Bucket *pListHead;
Bucket *pListTail;
Bucket **arBuckets; // hash数组
dtor_func_t pDestructor; // HashTable初始化时指定,销毁Bucket时调用
zend_bool persistent; // 是否采用C的内存分配例程
unsigned char nApplyCount;
zend_bool bApplyProtection;
#if ZEND_DEBUG
int inconsistent;
#endif
} HashTable;
总的来说,Zend的HashTable是一种链表散列,同时也为线性遍历进行了优化,图示如下:
HashTable中包含两种数据结构,一个链表散列和一个双向链表,前者用于进行快速键-值查询,后者方便线性遍历和排序,一个Bucket同时存在于这两个数据结构中。
关于该数据结构的几点解释:
l 链表散列中为什么使用双向链表?
一般的链表散列只需要按key进行操作,只需要单链表就够了。但是,Zend有时需要从链表散列中删除给定的Bucket,使用双链表可以非常高效的实现。
l nTableMask是干什么的?
这个值用于hash值到arBuckets数组下标的转换。当初始化一个HashTable,Zend首先为arBuckets数组分配nTableSize大小的内存,nTableSize取不小于用户指定大小的最小的2^n,即二进制的10*。nTableMask = nTableSize – 1,即二进制的01*,此时h & nTableMask就恰好落在 [0, nTableSize – 1] 里,Zend就以其为index来访问arBuckets数组。
l pDataPtr是干什么的?
通常情况下,当用户插入一个键值对时,Zend会将value复制一份,并将pData指向value副本。复制操作需要调用Zend内部例程 emalloc来分配内存,这是个非常耗时的操作,并且会消耗比value大的一块内存(多出的内存用于存放cookie),如果value很小的话,将会造成较大的浪费。考虑到HashTable多用于存放指针值,于是Zend引入pDataPtr,当value小到和指针一样长时,Zend就直接将其复制到pDataPtr里,并且将pData指向pDataPtr。这就避免了emalloc操作,同时也有利于提高Cache命中率。
arKey大小为什么只有1?为什么不使用指针管理key?
arKey是存放key的数组,但其大小却只有1,并不足以放下key。在HashTable的初始化函数里可以找到如下代码:
1p = (Bucket *) pemalloc(sizeof(Bucket) - 1 + nKeyLength, ht->persistent);
可见,Zend为一个Bucket分配了一块足够放下自己和key的内存,
l 上半部分是Bucket,下半部分是key,而arKey“恰好”是Bucket的最后一个元素,于是就可以使用arKey来访问key了。这种手法在内存管理例程中最为常见,当分配内存时,实际上是分配了比指定大小要大的内存,多出的上半部分通常被称为cookie,它存储了这块内存的信息,比如块大小、上一块指针、下一块指针等,baidu的Transmit程序就使用了这种方法。
不用指针管理key,是为了减少一次emalloc操作,同时也可以提高Cache命中率。另一个必需的理由是,key绝大部分情况下是固定不变的,不会因为key变长了而导致重新分配整个Bucket。这同时也解释了为什么不把value也一起作为数组分配了——因为value是可变的。
1.2.2 PHP数组
关于HashTable还有一个疑问没有回答,就是nNextFreeElement是干什么的?
不同于一般的散列,Zend的HashTable允许用户直接指定hash值,而忽略key,甚至可以不指定key(此时,nKeyLength为0)。同时,HashTable也支持append操作,用户连hash值也不用指定,只需要提供value,此时,Zend就用nNextFreeElement作为hash,之后将nNextFreeElement递增。
HashTable的这种行为看起来很奇怪,因为这将无法按key访问value,已经完全不是个散列了。理解问题的关键在于,PHP数组就是使用HashTable实现的——关联数组使用正常的k-v映射将元素加入HashTable,其key为用户指定的字符串;非关联数组则直接使用数组下标作为hash值,不存在key;而当在一个数组中混合使用关联和非关联时,或者使用array_push操作时,就需要用nNextFreeElement了。
再来看value,PHP数组的value直接使用了zval这个通用结构,pData指向的是zval*,按照上一节的介绍,这个zval*将直接存储在pDataPtr里。由于直接使

上一个:php中防止伪造跨站请求的小招式
下一个:php将时间差转换为字符串提示




- 更多php疑问解答:
- wordpress问题<?php if(have_posts()) : ?>
- 建设一个搜索类网站php还是jsp,数据库那个好
- 我是一个学PHP的,我现在已经学会了PHP,HTML,CSS,JS,JQ,AJAX,XML,thinkPHP,smarty模板
- 没理由啊 php代码无法执行,貌似有语法错误。。。
- 关于PHP 和API 的一段代码不懂啊不懂,请高手指点! 这是淘宝API的
- php语言中,序列化到底在那里使用?它的优势是什么?劣势是什么?
- PHP函数等于或等于应该怎么表达
- 请教php高手,解决basename函数和mb_substr函数处理中文文件名称的解决方法,在上传文件时,总是出现乱码
- .NET,PHP,JAVA,JS优秀点分别是?
- 织梦cms 在环境监测的时候 wamp5 gd不支持 是为什么。;extension=php_gd2.dll这一句我删除了还是不显示?
- 我想学PHP。1.应安装什么编程工具? 2. 装LIUNX系统是装简易的还是?什么版本的?3.还应安装什么?
- <?php 和 <? 有什么区别
- PHP网页如何接收按钮的值?请问
- 买来书的代码运行好是错误。。帮帮忙啊。php
- 求,一个php代码,用来修改 mysql数据库中的商品名字的大小写