NoSQL–Theory–CAP和BASE
NoSQL–Theory–CAP和BASE
一个成功的网络服务依赖于数据是正确、一致并且是可用的。对于一个简单的应用而言,它采用数据服务器加应用服务器构成。应用服务器相当于访问代理,并且处理应用的逻辑部分;数据服务器依靠数据库自身提高的功能来满足应用的需要,保证数据的正确、一致性和可用性。
网络服务的一个特点就是并发。随着用户的增加,并发成为应该系统最主要的瓶颈。在使用用户量不多的情况下,单服务器完全可以承受,随着使用用户的增加,我们可以采用各种优化技术,改良架构来解决部分用户增加导致的问题。但随着应用的进一步发展,业务需求和用户服务需求促使必须向分布式系统过渡。过渡带来一个棘手的问题需要解决:如何保证分散的数据在不稳定的网络环境中保持一致。
在进一步分析之前,我们先看看数据操作本身的特性。用一个学校的学生系统为例,当一个新生被录取时,我们需要在系统里添加一条关于该学生的信息记录。作为系统的设计人员,我们肯定不会在一张表中包含学生的所有信息,常用的做法是维护一个学生的基础信息库,然后后勤系统、教务系统、财务系统等都通过外键引用到学生的基础信息库。在初始化一条学生基础信息时,不可避免的需要在其他关联表中做初始化工作。添加学生信息的流程如下:
Step 1: 在基础信息库中添加一条该生的基础信息,比如生源地、性别等。
Step 2:在财务系统中建立该生的财务信息,缴费信息,贷款信息等。
Step 3:在教务系统中初始化一条该生的的教务相关的信息,比如专业、班级等。
Step 4:在后勤系统中初始化该生的信息,比如住宿、餐卡等。
我们期望的结果是,添加学生的操作如果被提交,系统就应该完成所有的4步操作,如果有一部操作失败,整个操作都应该回滚。对于单表的写操作而言,数据库会通过各种级别的锁保证所有的写操作都是顺序正确完成的。如果没有这部分机制,数据可能会丢失修改,用户可能脏读,不可重复读,幽灵数据。因此单表的写操作只会成功或失败(数据库不可用的时候会失败),产后的效果是:如果成功,表中肯定有一条正确的记录,如果失败,表中肯定没有一条错误的记录。但如果要保证几个连续的写操作,要么一起成功要么一起失败,我们就需要引入事务的概念。
数据库一般都是支持事务的,它具有ACID特性:
原子性( Atomicity ) 事务中的所有操作,要么全部完成,要么全部不完成,不可能停滞在中间某个环节。事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。
一致性(Consistency)在事务开始之前和事务结束以后,数据库的完整性约束没有被破坏。
隔离性(Isolation)两个事务的执行是互不干扰的,一个事务不可能看到其他事务运行时,中间某一时刻的数据。
持久性(Durability)在事务完成以后,该事务所对数据库所作的更改便持久的保存在数据库之中,并不会被回滚。
来整理一下事务的概念,首先不同的事务是相互隔离的,不会彼此影响;再次事务是有时间开销的,这意味着大事务将导致其他事务等不到及时的处理,对服务的可用性是有影响的。可以看到,ACID强调数据的一致性,而且是严格的强一致性。在保证一致性的背后,牺牲了并发和可用性。
但用户并不会为牺牲的并发和可用性买单,我们需要在一致性的前提下提高并发。基于数据库的改进有两个方向,一是垂直扩展;而是水平扩展。垂直扩展主要通过分库分表来实现,水平扩展主要通过主从库,读写分离来实现。也可以通过应用来软化事务,保证可用性和一致性。但这些改进效果是有限的,随着用户数量的进一步上升,数据库已经到了其使用的极限。我们需要探索新的数据存储使用方式,Google和Amazon等互联网企业最早做出了尝试,他们宣告NoSQL时代的到来。
现在我们跳出数据库的思维方式[注1],回到分布式系统中来,眼前面对的是分散在各个物理机器,不同地域的数据。眼前的数据并不一定是结构化的数据(数据库要求数据是结构化的并且遵循一定的Schema),还可能是半结构化和无结构的数据。这进一步让我们确信,现在是应该否认数据库的时候了。
在引入分布式系统的基本原理CAP之前,我们还是看看用户怎么使用分布式系统服务的。分布式系统使用的场合不同,对系统本身的要求也不相同。互联网是NoSQL的发源地。其他行业也有大数据的需求,但数据量没有互联网大,也没有同时为全球用户同时提供不同服务的需要。一般不会同时出现每秒数亿次的银行交易请求,但每秒数亿次的网络请求对互联网来说是一件常事。而且互联网上的请求背后隐藏的处理逻辑也是非常复杂的。正是互联网的快速发展,让我们有了足够的数据,足够的能力去分析理解这些数据,进而预测未来。大数据的到来,使互联网成为研究NoSQL的阵地。
我们拿售票系统为例,用户的大部分操作可能在浏览行车安排,余票信息上,真正发生购票操作的几率相对较小。在余票信息上我们可以舍去一致性,在用户真正购票时才保证余票信息的一致性。对于某些可预见有稳定退票发生的行业,即使多发售票也是可以接受的。由于放松了对读操作的一致性要求,我们可以使用缓存来减少对数据中心的访问。让数据中心专心解决购票操作,让有限的负荷放到真正产生商业收益的事情上。
在互联网的其他应用上面,也有类似的用户行为。对于大部分处于浏览、查询的请求,不要求数据完全正确一致的。我们只需要在关键交易行为中保证一致即可。
CAP原本是一个猜想,2000年PODC大会的时候大牛Brewer提出的,他认为在设计一个大规模可扩展的网络服务时候会遇到三个特性:一致性(consistency)、可用性(Availability)、分区容错(partition-tolerance)。这三个特性对于网络服务都需要,然而这是不可能都实现的。之后在2002年的时候,麻省理工(MIT)的Seth Gilbert 和Nancy Lynch ,理论上证明 了Brewer猜想是正确的,就此Brewer定理(Theorem)诞生了。
1. 一致性(consistency)与ACID中的C是一样的,指数据违反了某些预设的约束。直观点讲,就是数据的多个副本/备份存在不一致的情景。
2. 可用性(Availability)意味着服务可用,用户的所有操作都有及时的响应。
3. 分区容错(partition-tolerance)是应用或数据在多台机器上时,允许节点失效,系统仍能正常响应用户的请求。分区容错在整个网络瘫痪时肯定不能响应用户请求,但这种事件发生的概率微乎其微。
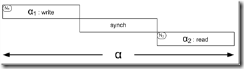
我们现在来分析为什么CAP不能同时满足。假定网络中的两个节点N1,N2。他们共享同一数据V,其值为V0。N1上有一个算法A,我们可以认为A是安全,无bug,可预测和可靠的。N2上有一个类似的算法B。在这个例子中,A写入V的新值而B读取V的值。

正常情况下,A写数据的过程如下:
(1)A写入新的V值,我们称作v1。
(2)N1发送信息M给N2,更新V的值。
(3)现在B读取的V值将会是V1。

如果N1和N2之间的网络断开,N2上的数据与N1就不一致了。如果M是一个异步消息,那么N1无法知道N2是否收到了消息。即使M是保证能发送的,N1也无法知道是否消息由于网络分区事件的发生而延迟,或N2上的其他故障而延迟。即使将M是同步信息也不能解决问题,因为那将会使得N1上A的写操作和N1到N2的更新事件成为一个原子操作,这将导致同样的等待问题,使得B的读操作不被允许,B的服务得不到满足。
如果我们想A和B的服务是高度可用的,我们就不得不允许A和B读到的数据不一致发生。

用事务的观点来看一下N1和N2的数据持久化问题,a1是写操作,a2是读操作。在一个本地系统中,可以利用数据库中的锁的机制方便地处理,隔离a2中的读操作,直到a1的写成功完成。然而,在分布式的模型中,需要考虑到N1和N2节点,中间的消息同步也要完成才行。除非我们可以控制a2何时发生,我们永远无法保证a2可以读到a1写入的数据。所有加入控制的方法(阻塞,隔离,中央化的管理,等等)会要么影响分区容错性,要么影响A和B的可用性。
我们必须做一些取舍:
1. 放弃Partition Tolerance 。如果你想避免分区问题发生,你就必须要阻止其发生。一种做法是将所有的东西(与事务相关的)都放到一台机器上。或者放在像机柜这类的统一管理的单元上。但100%不出现分区是不可能的,而且放弃分区容错代价昂贵。Haddoop的必然失效假设,Google和Facebook采用自己的硬件网络设备就是一个很好的证明。
2. 放弃Availability 。相对于放弃分区容错性来说,其反面就是放弃可用性。一旦遇到分区事件,受影响的服务需要等待数据一致,因此在等待期间就无法对外提供服务。在多个节点上控制这一点会相当复杂,而且恢复的节点需要处理逻辑,以便平滑地返回服务状态。
3. 放弃Consistency, 或者如同Werner Vogels所提倡的,接受事情会变得“最终一致 (Eventually Consistent)”。许多的不一致性并不比你想的需要更多的工作(意味着持续的一致性或许并不是我们所需要的)。比如网络购书,如果一本库存的书,接到了2个订单,第二个就会成为备份订单。只要告知客户这种情况(请记住这是一种罕见的情况),也许每个人都会高兴的。
4. 引入BASE 。有一种架构的方法称作BASE(Basically Available, Soft-state, Eventually consistent)支持最终一致概念的接受。BASE如其名字所示,是ACID的反面,但如果认为任何架构应该完全基于一种(BASE)或完全基于另一种(ACID),就大错特错了。应该结合自身的使用场景,合理平衡BASE和ACID。
放弃分区容错是不现实的[注2],我们需要在可用性和一致性中做些
一个成功的网络服务依赖于数据是正确、一致并且是可用的。对于一个简单的应用而言,它采用数据服务器加应用服务器构成。应用服务器相当于访问代理,并且处理应用的逻辑部分;数据服务器依靠数据库自身提高的功能来满足应用的需要,保证数据的正确、一致性和可用性。
网络服务的一个特点就是并发。随着用户的增加,并发成为应该系统最主要的瓶颈。在使用用户量不多的情况下,单服务器完全可以承受,随着使用用户的增加,我们可以采用各种优化技术,改良架构来解决部分用户增加导致的问题。但随着应用的进一步发展,业务需求和用户服务需求促使必须向分布式系统过渡。过渡带来一个棘手的问题需要解决:如何保证分散的数据在不稳定的网络环境中保持一致。
在进一步分析之前,我们先看看数据操作本身的特性。用一个学校的学生系统为例,当一个新生被录取时,我们需要在系统里添加一条关于该学生的信息记录。作为系统的设计人员,我们肯定不会在一张表中包含学生的所有信息,常用的做法是维护一个学生的基础信息库,然后后勤系统、教务系统、财务系统等都通过外键引用到学生的基础信息库。在初始化一条学生基础信息时,不可避免的需要在其他关联表中做初始化工作。添加学生信息的流程如下:
Step 1: 在基础信息库中添加一条该生的基础信息,比如生源地、性别等。
Step 2:在财务系统中建立该生的财务信息,缴费信息,贷款信息等。
Step 3:在教务系统中初始化一条该生的的教务相关的信息,比如专业、班级等。
Step 4:在后勤系统中初始化该生的信息,比如住宿、餐卡等。
我们期望的结果是,添加学生的操作如果被提交,系统就应该完成所有的4步操作,如果有一部操作失败,整个操作都应该回滚。对于单表的写操作而言,数据库会通过各种级别的锁保证所有的写操作都是顺序正确完成的。如果没有这部分机制,数据可能会丢失修改,用户可能脏读,不可重复读,幽灵数据。因此单表的写操作只会成功或失败(数据库不可用的时候会失败),产后的效果是:如果成功,表中肯定有一条正确的记录,如果失败,表中肯定没有一条错误的记录。但如果要保证几个连续的写操作,要么一起成功要么一起失败,我们就需要引入事务的概念。
数据库一般都是支持事务的,它具有ACID特性:
原子性( Atomicity ) 事务中的所有操作,要么全部完成,要么全部不完成,不可能停滞在中间某个环节。事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。
一致性(Consistency)在事务开始之前和事务结束以后,数据库的完整性约束没有被破坏。
隔离性(Isolation)两个事务的执行是互不干扰的,一个事务不可能看到其他事务运行时,中间某一时刻的数据。
持久性(Durability)在事务完成以后,该事务所对数据库所作的更改便持久的保存在数据库之中,并不会被回滚。
来整理一下事务的概念,首先不同的事务是相互隔离的,不会彼此影响;再次事务是有时间开销的,这意味着大事务将导致其他事务等不到及时的处理,对服务的可用性是有影响的。可以看到,ACID强调数据的一致性,而且是严格的强一致性。在保证一致性的背后,牺牲了并发和可用性。
但用户并不会为牺牲的并发和可用性买单,我们需要在一致性的前提下提高并发。基于数据库的改进有两个方向,一是垂直扩展;而是水平扩展。垂直扩展主要通过分库分表来实现,水平扩展主要通过主从库,读写分离来实现。也可以通过应用来软化事务,保证可用性和一致性。但这些改进效果是有限的,随着用户数量的进一步上升,数据库已经到了其使用的极限。我们需要探索新的数据存储使用方式,Google和Amazon等互联网企业最早做出了尝试,他们宣告NoSQL时代的到来。
现在我们跳出数据库的思维方式[注1],回到分布式系统中来,眼前面对的是分散在各个物理机器,不同地域的数据。眼前的数据并不一定是结构化的数据(数据库要求数据是结构化的并且遵循一定的Schema),还可能是半结构化和无结构的数据。这进一步让我们确信,现在是应该否认数据库的时候了。
在引入分布式系统的基本原理CAP之前,我们还是看看用户怎么使用分布式系统服务的。分布式系统使用的场合不同,对系统本身的要求也不相同。互联网是NoSQL的发源地。其他行业也有大数据的需求,但数据量没有互联网大,也没有同时为全球用户同时提供不同服务的需要。一般不会同时出现每秒数亿次的银行交易请求,但每秒数亿次的网络请求对互联网来说是一件常事。而且互联网上的请求背后隐藏的处理逻辑也是非常复杂的。正是互联网的快速发展,让我们有了足够的数据,足够的能力去分析理解这些数据,进而预测未来。大数据的到来,使互联网成为研究NoSQL的阵地。
我们拿售票系统为例,用户的大部分操作可能在浏览行车安排,余票信息上,真正发生购票操作的几率相对较小。在余票信息上我们可以舍去一致性,在用户真正购票时才保证余票信息的一致性。对于某些可预见有稳定退票发生的行业,即使多发售票也是可以接受的。由于放松了对读操作的一致性要求,我们可以使用缓存来减少对数据中心的访问。让数据中心专心解决购票操作,让有限的负荷放到真正产生商业收益的事情上。
在互联网的其他应用上面,也有类似的用户行为。对于大部分处于浏览、查询的请求,不要求数据完全正确一致的。我们只需要在关键交易行为中保证一致即可。
CAP原本是一个猜想,2000年PODC大会的时候大牛Brewer提出的,他认为在设计一个大规模可扩展的网络服务时候会遇到三个特性:一致性(consistency)、可用性(Availability)、分区容错(partition-tolerance)。这三个特性对于网络服务都需要,然而这是不可能都实现的。之后在2002年的时候,麻省理工(MIT)的Seth Gilbert 和Nancy Lynch ,理论上证明 了Brewer猜想是正确的,就此Brewer定理(Theorem)诞生了。
1. 一致性(consistency)与ACID中的C是一样的,指数据违反了某些预设的约束。直观点讲,就是数据的多个副本/备份存在不一致的情景。
2. 可用性(Availability)意味着服务可用,用户的所有操作都有及时的响应。
3. 分区容错(partition-tolerance)是应用或数据在多台机器上时,允许节点失效,系统仍能正常响应用户的请求。分区容错在整个网络瘫痪时肯定不能响应用户请求,但这种事件发生的概率微乎其微。
我们现在来分析为什么CAP不能同时满足。假定网络中的两个节点N1,N2。他们共享同一数据V,其值为V0。N1上有一个算法A,我们可以认为A是安全,无bug,可预测和可靠的。N2上有一个类似的算法B。在这个例子中,A写入V的新值而B读取V的值。
正常情况下,A写数据的过程如下:
(1)A写入新的V值,我们称作v1。
(2)N1发送信息M给N2,更新V的值。
(3)现在B读取的V值将会是V1。
如果N1和N2之间的网络断开,N2上的数据与N1就不一致了。如果M是一个异步消息,那么N1无法知道N2是否收到了消息。即使M是保证能发送的,N1也无法知道是否消息由于网络分区事件的发生而延迟,或N2上的其他故障而延迟。即使将M是同步信息也不能解决问题,因为那将会使得N1上A的写操作和N1到N2的更新事件成为一个原子操作,这将导致同样的等待问题,使得B的读操作不被允许,B的服务得不到满足。
如果我们想A和B的服务是高度可用的,我们就不得不允许A和B读到的数据不一致发生。
用事务的观点来看一下N1和N2的数据持久化问题,a1是写操作,a2是读操作。在一个本地系统中,可以利用数据库中的锁的机制方便地处理,隔离a2中的读操作,直到a1的写成功完成。然而,在分布式的模型中,需要考虑到N1和N2节点,中间的消息同步也要完成才行。除非我们可以控制a2何时发生,我们永远无法保证a2可以读到a1写入的数据。所有加入控制的方法(阻塞,隔离,中央化的管理,等等)会要么影响分区容错性,要么影响A和B的可用性。
我们必须做一些取舍:
1. 放弃Partition Tolerance 。如果你想避免分区问题发生,你就必须要阻止其发生。一种做法是将所有的东西(与事务相关的)都放到一台机器上。或者放在像机柜这类的统一管理的单元上。但100%不出现分区是不可能的,而且放弃分区容错代价昂贵。Haddoop的必然失效假设,Google和Facebook采用自己的硬件网络设备就是一个很好的证明。
2. 放弃Availability 。相对于放弃分区容错性来说,其反面就是放弃可用性。一旦遇到分区事件,受影响的服务需要等待数据一致,因此在等待期间就无法对外提供服务。在多个节点上控制这一点会相当复杂,而且恢复的节点需要处理逻辑,以便平滑地返回服务状态。
3. 放弃Consistency, 或者如同Werner Vogels所提倡的,接受事情会变得“最终一致 (Eventually Consistent)”。许多的不一致性并不比你想的需要更多的工作(意味着持续的一致性或许并不是我们所需要的)。比如网络购书,如果一本库存的书,接到了2个订单,第二个就会成为备份订单。只要告知客户这种情况(请记住这是一种罕见的情况),也许每个人都会高兴的。
4. 引入BASE 。有一种架构的方法称作BASE(Basically Available, Soft-state, Eventually consistent)支持最终一致概念的接受。BASE如其名字所示,是ACID的反面,但如果认为任何架构应该完全基于一种(BASE)或完全基于另一种(ACID),就大错特错了。应该结合自身的使用场景,合理平衡BASE和ACID。
放弃分区容错是不现实的[注2],我们需要在可用性和一致性中做些



- 更多SQLServer疑问解答:
- 配置MSSQL复制指定快照文件夹提示:不是有效的路径或文件名
- 详细解读varchar和Nvarchar区别
- SQL SERVER 2005 同步复制技术
- 进程未能大容量复制到表 解决方法
- MSSql实例教程:MSSql数据库同步
- SQLServer2000同步复制技术实现(分发和订阅)
- sqlserver
- SQLSERVER
- 测试 sqlserver 最大用户数连接
- 写出一条Sql语句:取出表A中第31到第40记录(SQLServer,以自动增长的ID作为主键,注意:ID可能不是连续的
- sqlserver2008的安装问题。
- 为什么安装的SQL server 2008我的没有MSSQLSERVER协议啊?
- 怎样把exel表里的数据复制到sqlserver表里
- sqlserver数据库主键和外键问题
- sqlserver 中的左表连接查询和右表连接查询有啥不同?有什么用?