程序员编程艺术:第三章、寻找最小的k个数
寻找最小的k个数
题目描述:5.查找最小的k个元素
题目:输入n个整数,输出其中最小的k个。
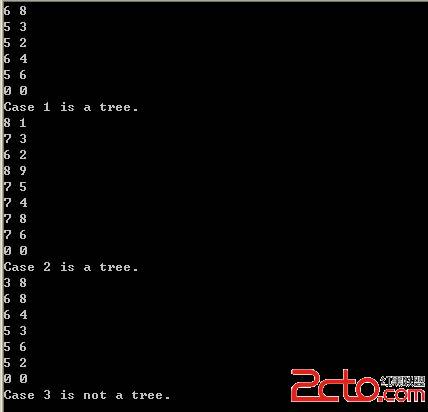
例如输入1,2,3,4,5,6,7和8这8个数字,则最小的4个数字为1,2,3和4。
第一节、各种思路,各种选择0、 咱们先简单的理解,要求一个序列中最小的k个数,按照惯有的思维方式,很简单,先对这个序列从小到大排序,然后输出前面的最小的k个数即可。
1、 至于选取什么的排序方法,我想你可能会第一时间想到快速排序,我们知道,快速排序平均所费时间为n*logn,然后再遍历序列中前k个元素输出,即可,总的时间复杂度为O(n*logn+k)=O(n*logn)。
2、 咱们再进一步想想,题目并没有要求要查找的k个数,甚至后n-k个数是有序的,既然如此,咱们又何必对所有的n个数都进行排序列?
这时,咱们想到了用选择或交换排序,即遍历n个数,先把最先遍历到得k个数存入大小为k的数组之中,对这k个数,利用选择或交换排序,找到k个数中的最大数kmax(kmax设为k个元素的数组中最大元素),用时O(k)(你应该知道,插入或选择排序查找操作需要O(k)的时间),后再继续遍历后n-k个数,x与kmax比较:如果x<kmax,则x代替kmax,并再次重新找出k个元素的数组中最大元素kmax‘(多谢kk791159796 提醒修正);如果x>kmax,则不更新数组。这样,每次更新或不更新数组的所用的时间为O(k)或O(0),整趟下来,总的时间复杂度平均下来为:n*O(k)=O(n*k)。
3、 当然,更好的办法是维护k个元素的最大堆,原理与上述第2个方案一致,即用容量为k的最大堆存储最先遍历到的k个数,并假设它们即是最小的k个数,建堆费时O(k)后,有k1<k2<...<kmax(kmax设为大顶堆中最大元素)。继续遍历数列,每次遍历一个元素x,与堆顶元素比较,x<kmax,更新堆(用时logk),否则不更新堆。这样下来,总费时O(k+(n-k)*logk)=O(n*logk)。此方法得益于在堆中,查找等各项操作时间复杂度均为logk(不然,就如上述思路2所述:直接用数组也可以找出前k个小的元素,用时O(n*k))。
4、 按编程之美第141页上解法二的所述,类似快速排序的划分方法,N个数存储在数组S中,再从数组中随机选取一个数X(随机选取枢纽元,可做到线性期望时间O(N)的复杂度,在第二节论述),把数组划分为Sa和Sb俩部分,Sa<=X<=Sb,如果要查找的k个元素小于Sa的元素个数,则返回Sa中较小的k个元素,否则返回Sa中k个小的元素+Sb中小的k-|Sa|个元素。像上述过程一样,这个运用类似快速排序的partition的快速选择SELECT算法寻找最小的k个元素,在最坏情况下亦能做到O(N)的复杂度。不过值得一提的是,这个快速选择SELECT算法是选取数组中“中位数的中位数”作为枢纽元,而非随机选取枢纽元。
5、 RANDOMIZED-SELECT,每次都是随机选取数列中的一个元素作为主元,在0(n)的时间内找到第k小的元素,然后遍历输出前面的k个小的元素。 如果能的话,那么总的时间复杂度为线性期望时间:O(n+k)=O(n)(当k比较小时)。
Ok,稍后第二节中,我会具体给出RANDOMIZED-SELECT(A, p, r, i)的整体完整伪码。在此之前,要明确一个问题:我们通常所熟知的快速排序是以固定的第一个或最后一个元素作为主元,每次递归划分都是不均等的,最后的平均时间复杂度为:O(n*logn),但RANDOMIZED-SELECT与普通的快速排序不同的是,每次递归都是随机选择序列从第一个到最后一个元素中任一一个作为主元。6、 线性时间的排序,即计数排序,时间复杂度虽能达到O(n),但限制条件太多,不常用。
7、 updated: huaye502在本文的评论下指出:“可以用最小堆初始化数组,然后取这个优先队列前k个值。复杂度O(n)+k*O(log n)”。huaye502的意思是针对整个数组序列建最小堆,建堆所用时间为O(n)(算法导论一书上第6章第6.3节已经论证,在线性时间内,能将一个无序的数组建成一个最小堆),然后取堆中的前k个数,总的时间复杂度即为:O(n+k*logn)。
关于上述第7点思路的继续阐述:至于思路7的O(n+k*logn)是否小于上述思路3的O(n*logk),即O(n+k*logn)?< O(n*logk)。粗略数学证明可参看如下第一幅图,我们可以这么解决:当k是常数,n趋向于无穷大时,求(n*logk)/(n+k*logn)的极限T,如果T>1,那么可得O(n*logk)>O(n+k*logn),也就是O(n+k*logn)< O(n*logk)。虽然这有违我们惯常的思维,然事实最终证明的确如此,这个极值T=logk>1,即采取建立n个元素的最小堆后取其前k个数的方法的复杂度小于采取常规的建立k个元素最大堆后通过比较寻找最小的k个数的方法的复杂度。但,最重要的是,如果建立n个元素的最小堆的话,那么其空间复杂度势必为O(N),而建立k个元素的最大堆的空间复杂度为O(k)。所以,综合考虑,我们一般还是选择用建立k个元素的最大堆的方法解决此类寻找最小的k个数的问题。也可以如gbb21所述粗略证明:要证原式k+n*logk-n-k*logn>0,等价于证(logk-1)n-k*logn+k>0。当when n -> +inf(n趋向于正无穷大)时,logk-1-0-0>0,即只要满足logk-1>0即可。原式得证。即O(k+n*logk)>O(n+k*logn) => O(n+k*logn)< O(n*logk),与上面得到的结论一致。
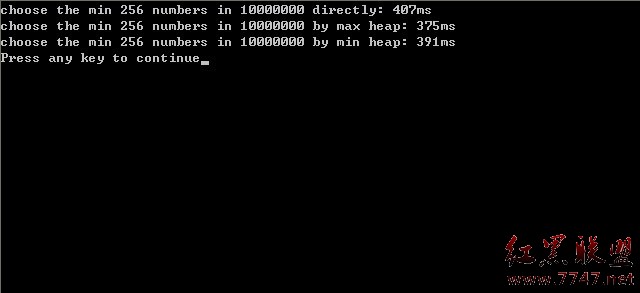
事实上,是建立最大堆还是建立最小堆,其实际的程序运行时间相差并不大,运行时间都在一个数量级上。因为后续,我们还专门写了个程序进行测试,即针对1000w的数据寻找其中最小的k个数的问题,采取两种实现,一是采取常规的建立k个元素最大堆后通过比较寻找最小的k个数的方案,一是采取建立n个元素的最小堆,然后取其前k个数的方法,发现两相比较,运行时间实际上相差无几。结果可看下面的第二幅图。

8、 @lingyun310:与上述思路7类似,不同的是在对元素数组原地建最小堆O(n)后,然后提取K次,但是每次提取时,换到顶部的元素只需要下移顶多k次就足够了,下移次数逐次减少(而上述思路7每次提取都需要logn,所以提取k次,思路7需要k*logn。而本思路8只需要K^2)。此种方法的复杂度为O(n+k^2)。@July:对于这个O(n+k^2)的复杂度,我相当怀疑。因为据我所知,n个元素的堆,堆中任何一项操作的复杂度皆为logn,所以按理说,lingyun310方法的复杂度应该跟下述思路8一样,也为O(n+k*logn),而非O(n+k*k)。ok,先放到这,待时间考证。06.02。
updated:
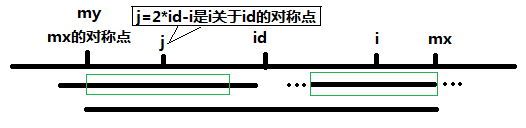
经过和几个朋友的讨论,已经证实,上述思路7lingyun310所述的思路应该是完全可以的。下面,我来具体解释下他的这种方法。我们知道,n个元素的最小堆中,可以先取出堆顶元素得到我们第1小的元素,然后把堆中最后一个元素(较大的元素)上移至堆顶,成为新的堆顶元素(取出堆顶元素之后,把堆中下面的最后一个元素送到堆顶的过程可以参考下面的第一幅图。至于为什么是怎么做,为什么是把最后一个元素送到堆顶成为堆顶元素,而不是把原来堆顶元素的儿子送到堆顶呢?具体原因可参考相关书籍)。
此时,堆的性质已经被破坏了,所以此后要调整堆。怎么调整呢?就是一般人所说的针对新的堆顶元素shiftdown,逐步下移(因为新的堆顶元素由最后一个元素而来,比较大嘛,既然是最小堆,当然大的元素就要下沉到堆的下部了)。下沉多少步呢?即如lingyun310所说的,下沉k次就足够了。
下移k次之后,此时的堆顶元素已经是我们要找的第2小的元素。然后,取出这个第2小的元素(堆顶元素),再次把堆中的最后一个元素送到堆顶,又经过k-1次下移之后(此后下移次数逐步减少,k-2,k-3,...k=0后算法中断)....,如此重复k-1趟操作,不断取出的堆顶元素即是我们要找的最小的k个数。虽然上述算法中断后整个堆已经不是最小堆了,但是求得的k个最小元素已经满足我们题目所要求的了,就是说已经找到了最小的k个数,那么其它的咱们不管了。
我可以再举一个形象易懂的例子。你可以想象在一个水桶中,有很多的气泡,这些气泡从上到下,总体的趋势是逐渐增大的,但却不是严格的逐次大(正好这也符合最小堆的性质)。ok,现在我们取出第一个气泡,那这个气泡一定是水桶中所有气泡中最小的,把它取出来,然后把最下面的那个大气泡(但不一定是最大的气泡)移到最上面去,此时违反了气泡从上到下总体上逐步变大的趋势,所以,要把这个大气泡往下沉,下沉到哪个位置呢?就是下沉k次。下沉k次后,最上面的气泡已经肯定是最小的气泡了,把他再次取出。然后又将最下面最后的那个气泡移至最上面,移到最上面后,再次让它逐次下沉,下沉k-1次...,如此循环往复,最终取到最小
补充:软件开发 , C语言 ,