当前位置:编程学习 > JSP >>
答案:Struts应用的国际化万维网(World Wide Web)的迅猛发展推动了跨国业务的发展,它成为一种在全世界范围内发布产品信息、吸引客户的有效手段。为了使企业Web应用能支持全球客户,软件开发者应该开发出支持多国语言、国际化的Web应用。1 本地化与国际化的概念国际化(简称为I18N)指的是软件设计阶段,就应该使软件具有支持多种语言和地区的功能。这样,当需要在应用中添加对一种新的语言和国家的支持时,不需要对已有的软件返工,无需修改应用的程序代码。本地化意味着针对不同语言的客户,开发出不同的软件版本;国际化意味着同一个软件可以面向使用各种不同语言的客户。如果一个应用支持国际化,它应该具备以下特征:· 当应用需要支持一种新的语言时,无需修改应用程序代码。· 文本、消息和图片从源程序代码中抽取出来,存储在外部。· 应该根据用户的语言和地理位置,对与特定文化相关的数据,如日期、时间和货币,进行正确的格式化。· 支持非标准的字符集。· 可以方便快捷地对应用作出调整,使它适应新的语言和地区。在对一个Web应用进行国际化时,除了应该对网站上的文本、图片和按钮进行国际化外,还应该对数字和货币等根据不同国家的标准进行相关的格式化,这样才能保证各个国家的用户都能顺利地读懂这些数据。Locale(本地)指的是一个具有相同风俗、文化和语言的区域。如果一个应用没有事先把I18N作为那前的功能,那么当这个应用需要支持新的Locale时,开发人员必需对嵌入在源代码中的文本、图片和消息进行修改,然后重新编译源代码。每当这个应用需要支持新的Locale时,就必需重复这些繁琐的步骤,这种做法显然大大降低了软件开发效率。2 Web应用的中文本地化无论时对Web应用的本地化还是国际化,都会涉及字符编码转换问题。当数据流的源与目的地使用不同的字符编码时,就需要对字符编码进行正确的转换。2.1 处理HTTP请求数据编码默认情况下,IE浏览器发送请求时采用“ISO-8859-1”字符编码,如果Web应用程序要正确地读取用户发送的中文数据,则需要进行编码转换。一种方法是在处理请求前,先设置HttpServletRequest对象的字符编码:request.setCharacterEncoding(“gb2312”);还有一种办法是对用户输入的请求数据进行编码转换:String clientData = request.getParameter(“clientData”);if(clientData != null)clientData = new String(clientData.getBytes(“ISO-8859-1”), “GB2312”);2.2 处理数据库数据编码如果数据库系统的字符编码为“GB2312”,那么可以直接读取数据库中的中文数据,而无需进行编码转换。如果数据库字符编码为“ISO-8859-1”,那么必需先对来自数据库的数据进行编码转换,然后才能使用。2.3 处理XML配置文件编码如果在XML文件中包含中文,可以将XML文件的字符编码为“GB2312”。这样,当Java程序加载和解析XML文件时无需再进行编码转换。<?xml version=’1.0’ encoding=”GB2312”?>2.4 处理响应结果的编码可以通过以下方式来设置响应结果的编码:· 在Servlet中response.setContentType(“text/html;charset=GB2312”);· 在JSP中<%@ page contentType=”text/html;charset=GB2312” %>· 在HTML中<head><META HTTP-EQUIV=”Content-Type” CONTENT=”text/html; charset=GB2312”></head>3 Java对I18N的支持Java在其核心库中提供了支持I18N的类和接口。Struts框架依赖于这些Java I18N组件来实现对I18N的支持,因此,掌握Java I18N组件的使用方法有助于理解Struts应用的国际化机制。3.1 Locale类java.util.Locale类时最重要的Java I18N类,在Java语言中,几乎所有对国际化和本地化的支持都依赖于这个类。Locale类的实例代表一种特定的语言和地区。如果Java类库中的某个类在运行时需要根据Locale对象来调整其功能,那么就称这个类是本地敏感的(Locale-Sensitive)。例如,java.text.DateFormat类就是本地敏感的,因为它需要依照特定的Locale对象来对日期进行相关的格式化。Locale对象本身病不执行和I18N相关的格式化或解析工作。Locale对象仅仅负责向本地敏感的类提供本地化信息。例如,DateFormat类依据Locale对象来确定日期的格式,然后对日期进行语法分析和格式化。创建Locale对象时,需要明确地指定其语言和国家代码。如:Locale usLocale = new Locale(“en”, “US”);Locale chLocale = new Locale(“ch”, “CH”);构造方法的第一个参数是语言代码。语言代码由两个小写字母组成,遵从ISO-639规范。可以从http://www.unicode.org/unicode/onlinedat/languages.html中获得完整的语言代码列表。构造方法的第二个参数是国家代码,它由两个大写字母组成,遵从ISO-3166规范。可以从http://www.unicode.org/unicode/onlinedat/countries.html中获得完整的国家代码列表。Locale类提供了几个静态常量,他们代表一些常用的Locale实例。例如,如果要获得Japanese Locale实例,可以使用如下两种方法之一:Locale locale1 = Locale.JAPAN;Locale locale2 = new Locale(“ja”, “JP”);3.1.1 Web容器中Locale对象的来源Java虚拟机在启动时会查询操作系统,为运行环境设置默认的Locale。Java程序可以调用java.util.Locale类的静态方法getLocale()来获得默认的Locale:Locale defaultLocale = Locale.getDefault();Web容器在其本地环境中通常会使用以上默认的Locale;而对于特定的中断用户,Web容器会从HTTP请求中获取Locale信息。3.1.2 在Web应用中访问Locale对象在创建Locale对象时应该把语言和国家代码两个参数传递给构造方法。对于Web应用程序,通常不必创建自己的Locale实例,因为Web容器会负责创建所需的Locale实例。在应用程序中,可以调用HttpServletRequest对象的以下两个方法,来取得包含Web客户的Locale信息的Locale实例:public java.util.Locale getLocale();public java.util.Enumeration getLocales();着两个方法都会访问HTTP请求中的Accept-Language头信息。getLocale()方法返回客户优先使用的Locale,而getLocales()方法返回一个Enumeration集合对象,它包含了按优先级降序排列的所有Locale对象。如果客户没有配置任何Locale,getLocale()方法将会返回默认的Locale。3.1.3 在Struts应用中访问Locale对象有序Web服务器并不和客户浏览器保持长期的连接,因此每个发送到Web容器的HTTP请求中都包含了Locale信息。Struts配置文件的<controller>元素的locale属性指定是否把Locale对象保存在session范围中,默认值为true,表示会把Locale对象保存在session范围中。在处理每一个用户请求时,RequestProcessor类都会调用它的processLocale()方法。尽管每次发送的HTTP请求都包含Locale信息,processLocale()方法把Locale对象存储在session范围中必需满足以下条件:
上一个:设置开发、运行环境
下一个:连连看的代码(基本算法)加了部分注释


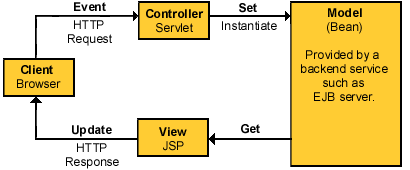


- 更多JSP疑问解答:
- jsp新手求指导,不要笑!
- 如何让一个form提取的值传递给多个jsp?
- DW中,新建的html页面能否有jsp或php代码?
- jsp 如何限制表单,实现只能填写特定的数据。
- jsp 和javabean结合的程序有问题
- 从数据库里取出的数据如何传递到另外的jsp页面中
- 你好,ext嵌入那个jsp页面,是不是还需要加上一些插件啊,不太懂,麻烦你了。
- JSP不能处理所有问题吗?还要来一大堆的TLD,TAG,XML。为JSP 非要 Servlet 不可吗?
- 光标离开时全角转半角在jsp中怎么实现
- jsp 页面 打开 pdf 文件 控制大小 和 工具栏 能发份源码么 谢啦
- jsp页面点保存按钮,运行缓慢,弹出对话框提示
- jsp刷新页面如何不闪屏
- jsp 与html 的交互问题?
- jsp小数显示问题 例如 我在oracle 数据库中查询出来的是 0.01 但是在jsp页面上就显示成 .01 没有前面的0
- jsp中日历控件