用蜘蛛抓卓越亚马逊碰到的问题。困惑中
HttpWebRequest request;
HttpWebResponse response;
TextReader tr;
string url = textBox1.Text.ToString();
request = (HttpWebRequest)WebRequest.Create(url);
response = (HttpWebResponse)request.GetResponse();
tr = new StreamReader(response.GetResponseStream(), Encoding.GetEncoding("UTF-8"));
textBox2.Text = tr.ReadToEnd();
response.Close();
WebExpress(textBox2.Text.ToString());
很简单的一段抓取程序
抓取的url为:http://www.amazon.cn/b/ref=sa_menu_office_l3_b106200071?ie=UTF8&node=106200071
关于笔记本的
抓到的结果:
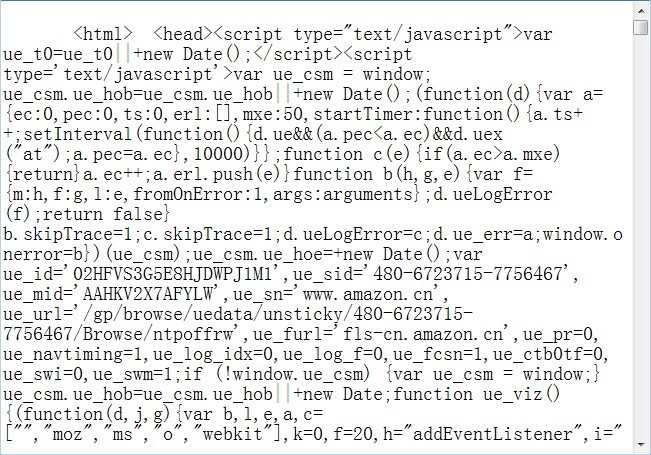
原始源:
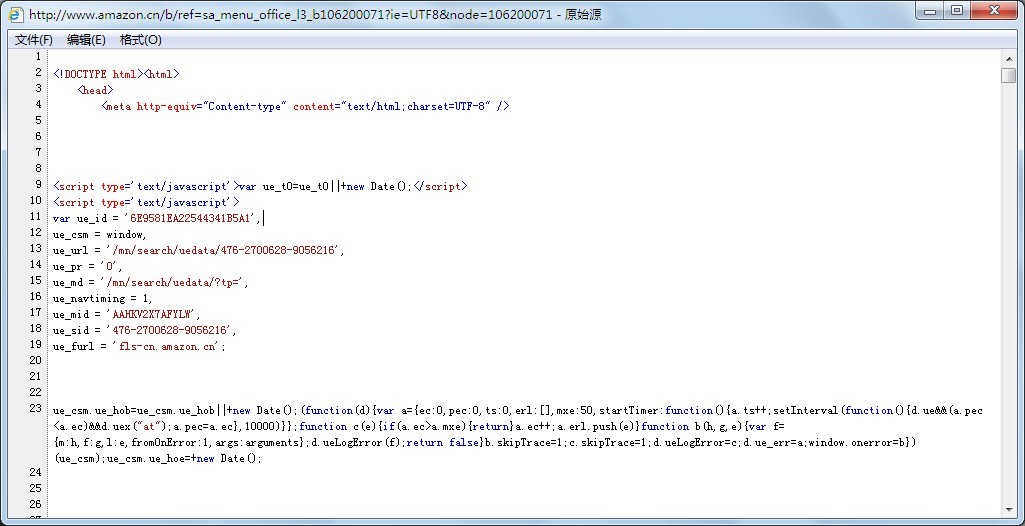
前部分比较一下,一看就少了些什么:
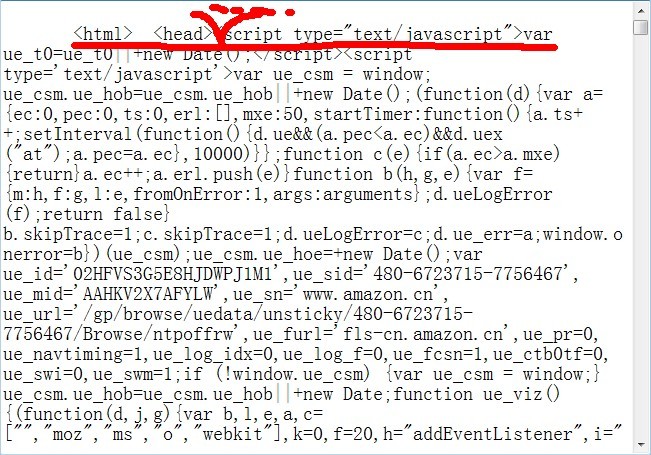
同时找寻字符串:"newp"
结果返回找不到了
源代码中有的:
 Amazon
URL
--------------------编程问答--------------------
Amazon
URL
--------------------编程问答--------------------
 --------------------编程问答--------------------
--------------------编程问答--------------------
 --------------------编程问答--------------------
--------------------编程问答--------------------
 --------------------编程问答--------------------
这个可不叫什么“少了”东西。
--------------------编程问答--------------------
这个可不叫什么“少了”东西。web服务器(不管是中间层次系统的还是人家业务处理用的程序)针对不同的浏览器客户端,本来就就可能自动产生不完全一样的html的。同时中间代理服务器也会修改html。同时浏览器也会修改html。
但是一般来说,得到的html在语法结构上、那些对业务有意义的部分,是相同的。
例如这类<meta ......>,比如说人家人家输出的时候ContentEncoding是gb2312的,但是你在浏览器上设置了“要使用utf8编码”,那么我估计类似chrome这种浏览器就会自动转换html内容并且自动在html中插入这个<meta ......>。也就是说这是浏览器给你改了html。
但是各个环节都可能修改html。web应用程序也完全可能根据客户端的不同,或者cookie不同,或者当时业务处理是数据不同,或者也许恰好更新了web应用程序,而输出不同的html。不要抠html的字眼,你只要注意需要采集的语法元素是否存在就可以了。
例如你需要采集 <xxx yyy="...." zzz="...." /> 这样一个东西,所写出的采集程序如果纠结于“到底是yyy属性在前还是zzz属性在前”这就很扯淡了。如果你发现有人给你写的采集程序“范例”连这个先后次序调转都应付不了,那我就劝你扔掉这种程序。因为此程序显然不是针对html语法来设计采集流程的,而是死抠低级的单词的匹配,必定非常非常地庞大、繁琐、逻辑混乱、无厘头般地复杂10倍。 --------------------编程问答-------------------- 如果你学习写采集程序时,有个正确的指导,就不会纠结于低级的问题了。
补充:.NET技术 , C#