pdfbox读取pdf文件问题出错
我的需求是能用java读取pdf的内容,根据网上的方法下载了PDFBox-0.7.3.zip导入了需要的包然后贴入了网上流行的代码:package pack;
import java.io.File;
import java.io.FileOutputStream;
import java.io.OutputStreamWriter;
import java.io.Writer;
import java.net.MalformedURLException;
import java.net.URL;
import org.pdfbox.pdmodel.PDDocument;
import org.pdfbox.util.PDFTextStripper;
public class PdfReader {
public void readFdf(String file) throws Exception {
// 是否排序
boolean sort = false;
// pdf文件名
String pdfFile = file;
// 输入文本文件名称
String textFile = null;
// 编码方式
String encoding = "UTF-8";
// 开始提取页数
int startPage = 1;
// 结束提取页数
int endPage = Integer.MAX_VALUE;
// 文件输入流,生成文本文件
Writer output = null;
// 内存中存储的PDF Document
PDDocument document = null;
try {
try {
// 首先当作一个URL来装载文件,如果得到异常再从本地文件系统//去装载文件
URL url = new URL(pdfFile);
//注意参数已不是以前版本中的URL.而是File。
document = PDDocument.load(pdfFile);
// 获取PDF的文件名
String fileName = url.getFile();
// 以原来PDF的名称来命名新产生的txt文件
if (fileName.length() > 4) {
File outputFile = new File(fileName.substring(0, fileName
.length() - 4)
+ ".txt");
textFile = outputFile.getName();
}
} catch (MalformedURLException e) {
// 如果作为URL装载得到异常则从文件系统装载
//注意参数已不是以前版本中的URL.而是File。
document = PDDocument.load(pdfFile);
if (pdfFile.length() > 4) {
textFile = pdfFile.substring(0, pdfFile.length() - 4)
+ ".txt";
}
}
// 文件输入流,写入文件倒textFile
output = new OutputStreamWriter(new FileOutputStream(textFile),
encoding);
// PDFTextStripper来提取文本
PDFTextStripper stripper = null;
stripper = new PDFTextStripper();
// 设置是否排序
stripper.setSortByPosition(sort);
// 设置起始页
stripper.setStartPage(startPage);
// 设置结束页
stripper.setEndPage(endPage);
// 调用PDFTextStripper的writeText提取并输出文本
stripper.writeText(document, output);
}
finally {
if (output != null) {
// 关闭输出流
output.close();
}
if (document != null) {
// 关闭PDF Document
document.close();
}
}
}
/**
* @param args
*/
public static void main(String[] args) {
// TODO Auto-generated method stub
PdfReader pdfReader = new PdfReader();
try {
// 取得E盘下的SpringGuide.pdf的内容
pdfReader.readFdf("E:\\电子科技大学复试计算机专业课面试问题锦集答案.pdf");
} catch (Exception e) {
e.printStackTrace();
}
}
}
但是始终运行不了,错误如下:
java.lang.NullPointerException
at org.pdfbox.pdmodel.PDPageNode.getAllKids(PDPageNode.java:194)
at org.pdfbox.pdmodel.PDPageNode.getAllKids(PDPageNode.java:182)
at org.pdfbox.pdmodel.PDDocumentCatalog.getAllPages(PDDocumentCatalog.java:226)
at org.pdfbox.util.PDFTextStripper.writeText(PDFTextStripper.java:216)
at pack.PdfReader.readFdf(PdfReader.java:65)
at pack.PdfReader.main(PdfReader.java:86)
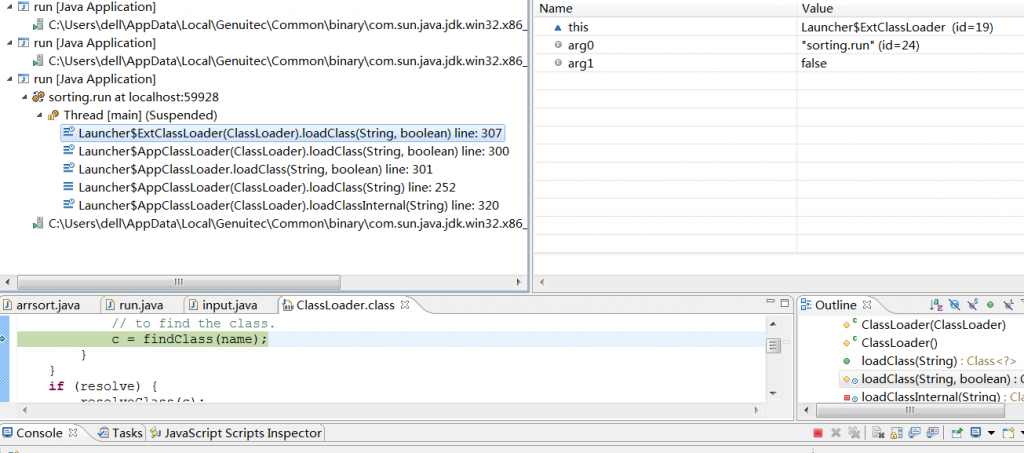
求高手帮忙解决,毕业设计,迫在眉睫!!! --------------------编程问答-------------------- 高手怎么还不现身? --------------------编程问答-------------------- 不是高手的看看,
报的是空指针异常,你没有贴具体是好多行。 有一点要注意,PDF文档,有的是扫描的,也就是说,pdf中可能是图片并不是文字,还有,文件名用英文试试吧,虽然不是中文的问题。 --------------------编程问答-------------------- 你一行一行的跟踪,应该很快就能跟踪到问题所在了, --------------------编程问答-------------------- 我已经一行行DEBUG了,每个变量都是有值的。只是pdfsmart包里面的东西是看不到的。。
错误提示就是这行:stripper.writeText(document, output); --------------------编程问答-------------------- 我也遇到一样的问题啊 --------------------编程问答-------------------- public String nextPage(int startPage, int endPage) throws IOException {
if (document.isEncrypted()) {
log.error("文件[" + path + "]已加密,未能打开");
return "";
}
stripper.setStartPage(startPage);
stripper.setEndPage(endPage);
return stripper.getText(document);
}
1)写入的数据方式 不对 stripper.getText(document);
2)你必段确保你的文件不是扫描版
--------------------编程问答-------------------- 你的主类最好另外新建一个函数写main(),这样子执行就不会错了,至于为什么,你自己去想想。
补充:Java , Java SE