JAVA中的编码问题,这个问题让我疑惑好长时间了!
--------------------编程问答-------------------- 第二个问题可以回答第一个问题:the platform's default charset指的是操作系统的默认编码方式,一个汉字在GBK里占2个字节。
public static void main(String[] args) {
Properties p = System.getProperties();
System.out.println(p.getProperty("file.encoding"));
}第三个问题,记事本都可以保存为不同的编码方式:
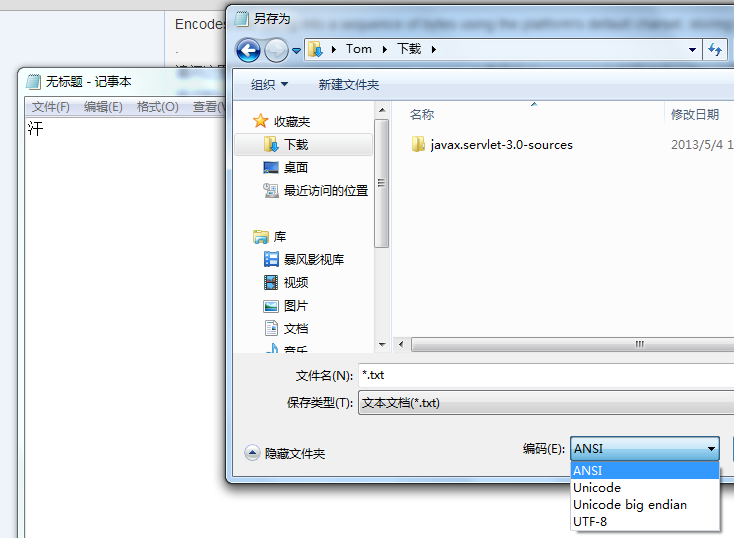
如图,你可以选择ANSI(在windows中文系统就是GBK)和UTF-8分别保存。
然后使用ue打开这个文件,使用ctrl和h键看它的二进制格式:
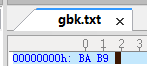
GBK:
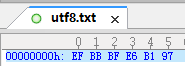
UTF-8:
 --------------------编程问答--------------------
你可以看到,GBK是2个字节,BA和B9;
--------------------编程问答--------------------
你可以看到,GBK是2个字节,BA和B9;UTF-8是6个字节,其中开头的EF BB BF是UTF-8文件的标志,最后的E6 B1 97才是这个字的编码。
那么你可以知道,其实UTF-8文件是有文件头EF BB BF的,只是这个是给编辑工具用的,不会展示个用户。
那么你的第四个问题就好回答了,如果你不设置编码方式,就是用系统的,windows中文就是GBK。
如果你设置UTF-8,就会在输出文件的头部加上EF BB BF,供编辑工具识别它是一个UTF-8文件。 --------------------编程问答-------------------- 随便给你一个a.txt文件,你怎么判断它的编码方式呢?
先用记事本打开,然后"另存为"看到的编码方式就是这个文件的编码方式。
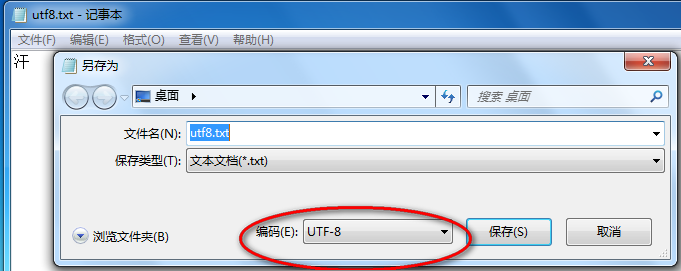
操作系统或者编辑工具只能根据文件是不是有UTF-8头,进行对应的展示(可以理解为解码);
它们并不保证正确,所有常常我们会打开文件乱码。
--------------------编程问答--------------------
那在文件头部加上编码标识符 这个事,是我们JDK做的呢,还是我们的操作系统完成的呢? --------------------编程问答--------------------
追问如下:
问题一: 我们常常在我们的myeclipse下设置页面格式为“UTF-8”,我想问的设置这个格式的目的到底是干什么?是为了让平台对于页面的编码和解码方式都是按照“UTF-8”么?是不是假如一个按照GBK格式编码并且含有汉字的文件,在以“UTF-8”为编码的myeclipse下,一定会出现乱码呢?
第二:我建立了两个文档,分别为utf-8.txt和GBK.txt,在每个文档中都保存了三个汉字“我爱你”,在以文本方式打开时候都正常显示,但是在以十六进制格式查看两个文档中,前者出现乱码,后者正常显示,这是否表明,UltraEditor对于中文的支持仍然存在一些问题呢,以至于在16进制查看汉字的时候,出现乱码?
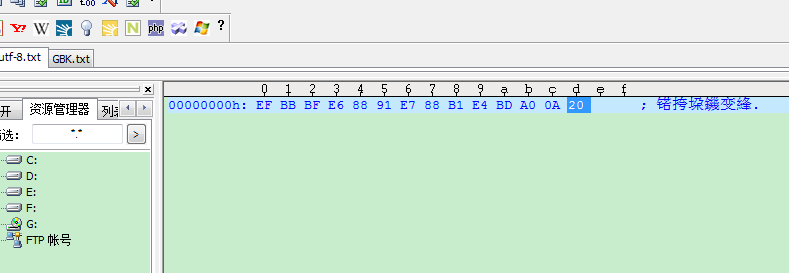
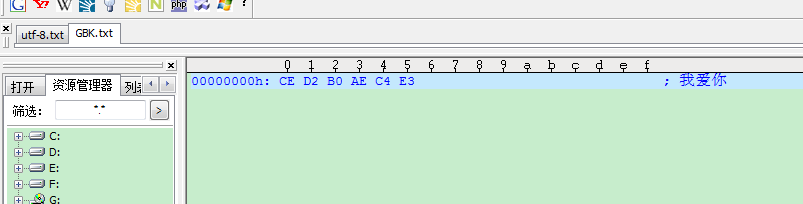
第三:在用Ultra,以16进制查看文档的时候,左侧的00000000h,00000010h这些标志的作用是什么呢,我很疑惑,在网上也没有查到,只是为了每一行的位置么,还是另有用意?我对Ultra不太熟悉,敬请赐教。
第三:在
--------------------编程问答-------------------- 兄弟,你的问的太多了,哥疲于应付了。就先说点我知道的吧:
文件头部加上编码标识符这个事,是我们JDK做的呢,还是我们的操作系统完成的呢?
// 是JDK做的。你想象一下记事本保存为不同编码的文件,就是增不增加这个文件头不一样罢了。
那么JDK的输出流,也和记事本做同样的事情就行了。操作系统并不关心你写什么到文件里。
GBK的文件,用UTF-8方式打开一定是乱码,同样UTF-8文件用GBK方式打开也是乱码。
myeclipse下设置页面格式为“UTF-8”,这个具体做了什么?我谈谈我的理解:
1、你保存java或者jsp文件的时候,会在文件增加UTF-8头。
2、编译的时候,会使用这个参数。你看javac命令有一个参数-encoding。myeclipse自动编译的时候,应该会使用这个参数的,只是咱们没注意过。你可以控制这个参数手动编译你的2个不同编码java的文件,然后运行,会对乱码有新的认识。
C:\Users\Tom>javac -help
用法:javac <选项> <源文件>
其中,可能的选项包括:
......
-encoding <编码> 指定源文件使用的字符编码
UE的乱码问题:
只要在文本格式查看不存在问题,就说明它支持的很好。
UTF-8文件二进制方式查看出现乱码,看样子是UE用GBK的编码方式去解码UTF-8的文件了。
你的UTF-8文件是14个字节,其中最后一个20是一个空格。那么前面13个自己,按照GBK一个汉字2个字节计算,应该解析出来是6个半汉字,你的乱码恰巧是6个汉字。其实你可以在这个文件里只保存一个汉字,你会看到乱码的第一个汉字始终是一样的,这个就是UTF-8的头的前2个字节用GBK去解码的缘故,这其实也是乱码的产生的一般原因。
补充:Java , Java EE




