[每日一题]OCP1z0-047 :2013-08-20 GROUP BY扩展――GROUPING、ROLLUP
[每日一题]OCP1z0-047 :2013-08-20 GROUP BY扩展――GROUPING、ROLLUP

正确答案:BD
在Oracle 8i中引入GROUPING(<列引用>)函数,被用来做为GROUPING()函数参数的表达式必须与出现在GROUPBY 子句中的表达式相匹配。包含了CUBE、ROLLUP或GROUPING SET关键字的组查询时,该函数对<列引用>相关列的聚合结果中的NULL值进行检查。例如通过写出decode(grouping(id),1,’ALLID’,id) id来检测id是否有一行由ROLLUP产生的空值,或着是否其在数据库中本身就是空值。如果这些NULL值是由本次ROLLUP查询生成的,那么返回1,否则返回0.
ROLLUP,该分组操作将生成一个结果集,此结果集除了包含正常分组之外,还包含小计(subtotal row)。ROLLUP操作字,对group by子句的各字段从右到左进行再聚合,逐个减少字段典型的总计和子计。如果是ROLLUP(A, B, C)的话,首先会对(A、B、C)进行GROUP BY,然后对(A、B)进行GROUP BY,然后是(A)进行GROUP BY,最后对全表进行GROUP BY操作(即GROUP BY())
rollup(a,b,c)
相当于
group by a,b,c union all group by a,b union all group by a union all group by ()
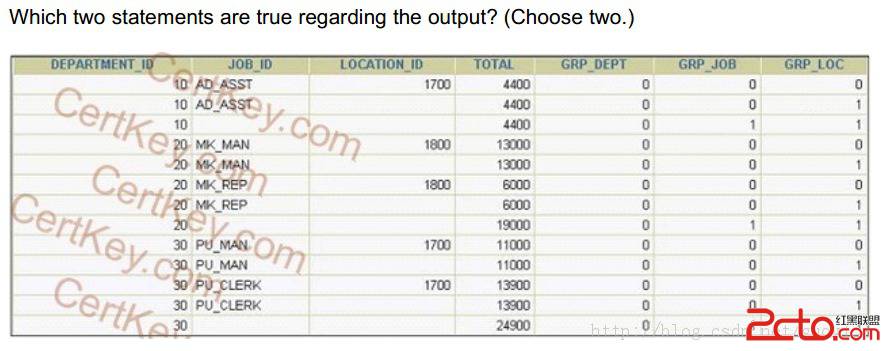
根据题意,执行以上SQL返回如下结果:
[html]
hr@MYDB> SELECT e.department_id,e.job_id,d.location_id,sum(e.salary) total,
2 GROUPING(e.department_id) GRP_DEPT,
3 GROUPING(e.job_id) GRP_JOB,
4 GROUPING(d.location_id) GRP_LOC
5 FROM employees e JOIN departments d
6 ON e.department_id=d.department_id
7 GROUP BY ROLLUP(e.department_id,e.job_id,d.location_id);
DEPARTMENT_ID JOB_ID LOCATION_ID TOTAL GRP_DEPT GRP_JOB GRP_LOC
------------- ---------- ----------- ---------- ---------- ---------- ----------
10 AD_ASST 1700 4400 0 0 0
10 AD_ASST 4400 0 0 1
10 4400 0 1 1
20 MK_MAN 1800 13000 0 0 0
20 MK_MAN 13000 0 0 1
20 MK_REP 1800 6000 0 0 0
20 MK_REP 6000 0 0 1
20 19000 0 1 1
30 PU_MAN 1700 11000 0 0 0
30 PU_MAN 11000 0 0 1
30 PU_CLERK 1700 13900 0 0 0
30 PU_CLERK 13900 0 0 1
30 24900 0 1 1
40 HR_REP 2400 6500 0 0 0
40 HR_REP 6500 0 0 1
40 6500 0 1 1
50 ST_MAN 1500 36400 0 0 0
50 ST_MAN 36400 0 0 1
50 SH_CLERK 1500 64300 0 0 0
50 SH_CLERK 64300 0 0 1
50 ST_CLERK 1500 55700 0 0 0
50 ST_CLERK 55700 0 0 1
50 156400 0 1 1
60 IT_PROG 1400 28800 0 0 0
60 IT_PROG 28800 0 0 1
60 28800 0 1 1
70 PR_REP 2700 10000 0 0 0
70 PR_REP 10000 0 0 1
70 10000 0 1 1
80 SA_MAN 2500 61000 0 0 0
80 SA_MAN 61000 0 0 1
80 SA_REP 2500 243500 0 0 0
80 SA_REP 243500 0 0 1
80 304500 0 1 1
90 AD_VP 1700 34000 0 0 0
90 AD_VP 34000 0 0 1
90 AD_PRES 1700 24000 0 0 0
90 AD_PRES 24000 0 0 1
90 58000 0 1 1
100 FI_MGR 1700 12008 0 0 0
100 FI_MGR 12008 0 0 1
100 FI_ACCOUNT 1700 39600 0 0 0
100 FI_ACCOUNT 39600 0 0 1
100 51608 0 1 1
110 AC_MGR 1700 12008 0 0 0
110 AC_MGR 12008 0 0 1
110 AC_ACCOUNT 1700 8300 0 0 0
110 AC_ACCOUNT 8300 0 0 1
110 20308 0 1 1
684416 1 1 1
50 rows selected.
把上面的SQL改写成如下这条SQL,结果一样:
[html]
hr@MYDB> SELECT e.department_id,e.job_id,d.location_id,sum(e.salary) total,
2 GROUPING(e.department_id) GRP_DEPT,
3 GROUPING(e.job_id) GRP_JOB,
4 GROUPING(d.location_id) GRP_LOC
5 FROM employees e JOIN departments d
6 ON e.department_id=d.department_id
7 GROUP BY e.department_id,e.job_id,d.location_id
8 UNION ALL
9 SELECT e.department_id,e.job_id,null location_id,sum(e.salary) total,
10 GROUPING(e.department_id) GRP_DEPT,
11 GROUPING(e.job_id) GRP_JOB,
12 1 GRP_LOC
13 FROM employees e JOIN departments d
14 ON e.department_id=d.department_id
15 GROUP BY e.department_id,e.job_id
16 UNION ALL
17 SELECT e.department_id,null job_id,null location_id,sum(e.salary) total,
18 GROUPING(e.department_id) GRP_DEPT,
19 1 GRP_JOB,
20 1 GRP_LOC
21 FROM employees e JOIN departments d
22 ON e.department_id=d.department_id
23 GROUP BY e.department_id
24 UNION ALL
25 SELECT null department_id,null job_id,null location_id,sum(e.salary) total,
26 1 GRP_DEPT,
27 1 GRP_JOB,
28 1 GRP_LOC
29 FROM employees e JOIN departments d
30 ON e.department_id=d.department_id
31 order by 1,2;
DEPARTMENT_ID JOB_ID LOCATION_ID TOTAL GRP_DEPT GRP_JOB GRP_LOC
------------- ---------- ----------- ---------- ---------- ---------- ----------
10 AD_ASST 1700 4400 0 0 0
10 AD_ASST 4400 0 0 1
10 4400 0 1 1
20 MK_MAN 1800 13000 0 0 0
20 MK_MAN 13000