超越单CUP:超线程加快了Linux的速度
简介Intel 的超线程技术通过复制、分区和共享 Intel NetBurst 微体系结构管道中的资源,使得一个物理处理器能包含两个逻辑处理器。
被复制的资源为两个线程创建了资源副本:
每个 CPU 的所有体系结构状态
指令指针,重命名逻辑
一些较小的资源(例如返回堆栈预测器、ITLB 等)
已分区的资源划分执行线程之间的资源:
几个缓冲区(Re-Order 缓冲区、Load/Store 缓冲区、队列等)
共享的资源按需在两个正在执行的线程之间使用资源:
乱序执行引擎
高速缓存
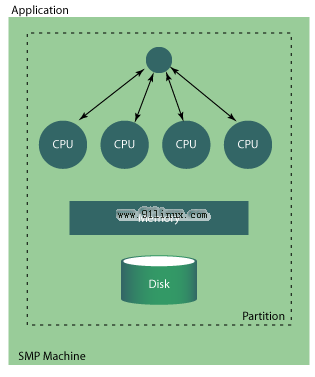
通常,每个物理处理器在一个处理器核心上都有一个体系结构状态,来为线程提供服务。使用了 HT,每个物理处理器在单个核心上就有两个体系结构状态,这使得物理处理器看起来象有两个逻辑处理器在为线程提供服务。系统 BIOS 列举出物理处理器中的每个体系结构状态。由于支持超线程的操作系统利用了逻辑处理器,因此这些操作系统就有两倍的资源可用于为线程提供服务。
Xeon 处理器中的超线程支持
在通用处理器中 Xeon 处理器最先实现同步多线程(SMT)(请参阅参考资料以获取有关 Xeon 处理器系列的更多信息)。为达到在单一物理处理器上执行两个线程的目标,该处理器同时维持多个线程的上下文,这允许调度程序并发分派两个可能无关的线程。
操作系统(OS)将多个线程代码调度和分派给每个逻辑处理器,就如同在 SMP 系统中。没有分派线程时,相关的逻辑处理器保持空闲。
当将一个线程调度和分派给逻辑处理器 LP0 时,超线程技术利用必需的处理器资源来执行该线程。
当将第二个线程调度和分派给第二个逻辑处理器 LP1 时,就要按需为执行该线程而复制、划分或共享资源。每个处理器都在管道各点上进行选择,以控制和处理这些线程。当每个线程完成时,操作系统将未用的处理器置为空闲,释放资源让正在运行的处理器使用。
OS 将线程调度和分派给每个逻辑处理器,就好像是在双处理器或多处理器系统中进行的那样。当系统调度线程并将之引入到管道中时,按需利用资源以处理这两个线程。
Linux 内核 2.4 中的超线程支持
Linux 内核将带有两个虚拟处理器的超线程处理器看成是一对真正的物理处理器。其结果是,处理 SMP 的调度程序也应该能处理超线程。Linux 内核 2.4.x 中的超线程支持始于 2.4.17,它包括了以下增强技术:
128 字节锁对齐
螺旋等待循环优化
基于非执行的延迟循环
检测支持超线程的处理器,并启动逻辑处理器,如同该机器是 SMP
MTRR 和微码更新(Microcode Update)驱动程序中的串行化,因为它们影响共享状态
在逻辑处理器上的调度发生之前,当系统空闲时对物理处理器上的调度进行优先级排序时,对调度程序进行优化
偏移用户堆栈以避免 64K 混叠
内核性能测量
为评定超线程对 Linux 内核性能的影响,我们在包括 Intel Xeon 处理器(具有 HT 功能)的系统上测量了内核基准测试程序的性能。硬件是:支持 SMT 的单 CPU、1.6 GHz Xeon MP 处理器、2.5 GB RAM 和两个 9.2 GB SCSI 硬盘驱动器。测量的内核是配置和构建了支持 SMP 的现有内核 V2.4.19。内核超线程支持通过引导选项 acpismp=force 来指定使用超线程,并通过引导选项 noht 来指定不使用超线程。查看是否支持超线程可以通过使用命令 cat /proc/cpuinfo,来显示处理器 0 和处理器 1 这两个处理器是否存在。请注意清单 1 中用于 CPU 0 和 1 的 ht 标志。在不支持超线程的情况下,将只显示处理器 0 的数据。
清单 1. cat /proc/cpuinfo 的输出,显示超线程支持
processor
: 0
vendor_id
: GenuineIntel
cpu family
: 15
model
: 1
model name
: Intel(R) Genuine CPU 1.60GHz
stepping
: 1
cpu MHz
: 1600.382
cache size
: 256 KB
. . .
fpu
: yes
fpu_exception: yes
cpuid level
: 2
wp
: yes
flags
: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr
pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht
tm
bogomips
: 3191.60
processor
: 1
vendor_id
: GenuineIntel
cpu family
: 15
model
: 1
model name
: Intel(R) Genuine CPU 1.60GHz
stepping
: 1
cpu MHz
: 1600.382
cache size
: 256 KB
. . .
fpu
: yes
fpu_exception: yes
cpuid level
: 2
wp
: yes
flags
: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr
pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht
tm
bogomips
: 3198.15
Linux 内核基准测试程序
为测量 Linux 内核性能,使用了 5 个基准测试程序:LMbench、AIM Benchmark Suite IX(AIM9)、chat、dbench 和 tbench。LMbench 基准测试程序对各种 Linux 应用程序编程接口(API)(例如,基本系统调用、上下文切换延迟和内存带宽)进行计时。AIM9 基准测试程序提供对用户应用程序工作负载的测量。chat 基准测试程序是模仿聊天室的客户机/服务器工作负载。dbench 基准测试程序是文件服务器工作负载,tbench 是 TCP 工作负载。chat、dbench 和 tbench 是多线程基准测试程序,而其它的则是单线程基准测试程序。
超线程对 Linux API 的影响
超线程对 Linux API 的影响通过 LMbench 来测量,LMbench 是包含一套带宽和延迟测量方法的微基准测试程序。这些影响中涉及了高速缓存文件读取、内存复制(bcopy)、内存读/写(和延迟)、管道、上下文切换、联网、文件系统的创建和删除、进程的创建、信号处理以及处理器时钟延迟。LMbench 着重测量以下内核组件:调度程序、进程管理、通信、联网、内存映射和文件系统。低级内核原语提供一个很好的、底层硬件能力和性能的指示器。
为研究超线程的效果,我们着重于延迟的测量,它测量消息控制的时间(换句话说,系统执行某个操作能有多快)。延迟的数量用“微秒/操作”进行记录。
表 1 显示了用 LMbench 进行测试的部分内核功能列表。每个数据点是三次运行的平均值,而且该数据已经作过收敛测试,以保证在相同的测试环境条件下它们是可再现的。通常,对于那些作为单线程运行的功能来说,有超线程和无超线程之间没有什么性能差别。然而,对于那些需要运行两个线程的测试(例如,管道延迟测试和三个进程延迟测试)来说,超线程似乎延长了它们的延迟时间。已配置的现有的 SMP 内核被标为 2419s。如果配置的内核不支持超线程,则将其标为 2419s-noht。若有超线程支持,则该内核被列为 2419s-ht。

管道延迟的测试使用了两个通过 UNIX 管道进行通信的进程来测量经由套接字的进程间通信延迟。基准测试程序在这两个进程之间来回传送标记。性能下降幅度为 1%,小得可以忽略不计。
这三个进程测试包括了在 Linux 中进行的进程创建和执行。目的是测量创建基本控制线程所花去的时间。对于进程 fork+exit 测试来说,该数据表示将一个进程分成两个(几乎)相同的副本并退出其中一个所花的延迟时间。新进程就是这么创建的 - 但这不是非常有用,因为两个进程执行相同的操作。在这个测试中,超线程造成的性能下降幅度为 4%。
在进程 fork+execve 中,数据表示创建新进程并让该新进程运行新程序所花的时间。这是所有 shell(命令解释器)的内循环。由于超线程,可以看到这个测试性能下降幅度为 6%。
在进程 fork+/bin/sh -c 测试中,数据表示创建新进程并使该新进程运行新程序(通过让系统 shell 查找该程序并运行它)所要花去的时间。C 库接口就是这样实现对系统的调用。这个调用最常见,也最费时。在使用超线程的情况下,相对不用超线程而言,运行本测试慢了 2%。
超线程对 Linux 单用户应用程序工作负载的影响
AIM9 基准测试程序是单用户工作负载,旨在测量硬件和操作系统的性能。结果如表 2 所示。该基准测试程序中的大多数测试在使用超线程和不用超线程情况下执行性能都相同,只是同步文件操作和整数过滤(Integer Sieve)有所不同。同步随机磁盘写操作(Sync Random Disk Writes)、同步顺序磁盘写操作(Sync Sequential Disk Writes)和同步磁盘复制(Sync Disk