Twisted服务器开发技巧(2)
第二种优化的方法,可以只用下图来解释。即,使用轻量级的线程池(PreProcess)对所有请求进行预处理,所有不需要I/O执行时间很短的请求直接执行,如果是需要磁盘I/O的则放入下一级阻塞队列,有单独的线程池来处理这些请求。详见下图:
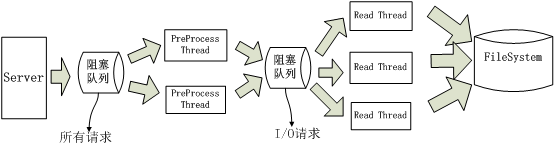
第一级请求使用自己已有的线程池,不再多说。I/O请求+二级线程池可以使用twisted提供的ThreadPool机制来实现。而我所说的优化正是使用此方法,代码很简单,如下:
deferred = threads.deferToThread(data_loader.get, sn)
deferred.addCallback(self.loader_callback, (req, other_data))
解释一下:
threads.deferToThread将会将data_loader.get放入reactor线程池的队列,并返回一个defer对象。data_loader.get由reactor的线程池进行执行,执行完成后放入reactor的队列,然后由reactor主线程来调用deferred.addCallback中注册的回调函数。所以回调函数是不会跨线程调用的,如果在回调函数中调用一些不可跨线程的应用(如,memcached客户端)也可放心使用,这也正是选择reactor的线程池作为二级线程池的原因之一。
选择reactor的线程池作为二级线程池的原因二:回调函数。因为Read Thread将自己负责恢复请求,所以回调函数必不可少。
接下来深入twisted源码探究此方法的原理,以下代码均是节选自twisted2.0.0源码,其他版本大致相同:
[python]
def deferToThread(f, *args, **kwargs):
d = defer.Deferred()
from twisted.internet import reactor
reactor.callInThread(_putResultInDeferred, d, f, args, kwargs)
return d
def _putResultInDeferred(deferred, f, args, kwargs):
from twisted.internet import reactor
try:
result = f(*args, **kwargs)
except:
f = failure.Failure()
reactor.callFromThread(deferred.errback, f)
else:
reactor.callFromThread(deferred.callback, result)
-----摘自threads.py
[python] view plaincopy
def callInThread(self, _callable, *args, **kwargs):
if not self.threadpool:
self._initThreadPool()
self.threadpool.callInThread(_callable, *args, **kwargs) //由线程池执行具体的读取操作
def callFromThread(self, f, *args, **kw):
...
self.threadCallQueue.append((f, args, kw)) //放入主线程队列,由主线程执行回调函数
self.wakeUp()
...
-----摘自base.py
注:callInThread/allFromThread,前者是放入线程池执行,后者是reactor的队列里,由reactor的主线程来执行。
至于threadpool的代码在twisted/python/threadpool是一个线程池
补充:Web开发 , Python ,