BSDsocket
NOTE: 这篇文章假定读者熟悉 UNIX 下的 socket 和网络编程. 对用户级编程知识, 本文不作叙述.socket 机制在系统中的地位
socket 机制是作为一个通用的, 跨机器, 跨平台的进程间通讯机制出现在系统中的. 我们通常把它作为网络通讯之用. 它使用了与文件系统相同的接口, 提供了协议无关的进程间通讯功能.
因此, 我们可以想到. 一个 socket 的机构应该被连接在 file 结构的 f_data 域中, 这样才能与上层的 VFS 相连, 并且应该逐个实现 fileops 中的函数接口 , 连在 file 结构的 f_ops 之中, 这样我们才可以如我们实际所做的那样, 用文件系统的 read(2), write(2) 函数进行 socket 通信. 同时, socket 的机构也应该包含一个域, 它是一个函数跳转表, 以跳转到底层协议, 如 TCP 的实现函数中. 在这个角度上看, socket 的作用也跟 VFS 是类似的. 但它与 VFS 大部分操作直接转接不同, 它还有大量需要自己处理的工作.
数据结构
内核结构
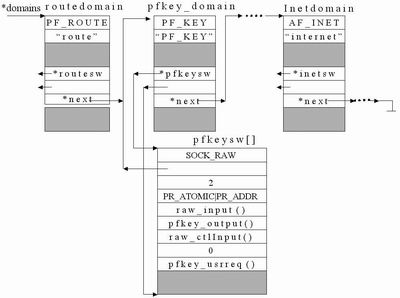
socket 的基本结构在 sys/socketvar.h 中, 包括 struct socket 以及描述 socket 缓冲区的结构 struct sockbuf. 上文所说的 socket 应有的机构都可以得到确认.
在 sys/protosw.h 中, 我们可以看到由 socket 结构 so_proto 域指向的 protosw 结构. 这就是 socket 与底层具体协议实现的接口. 我们需要大概记忆接口函数.
sys/socketvar.h 的 145 行是 socket 的状态, 需牢记.
用户接口数据结构
XXX.
mbuf
在 sockbuf 结构中, 我们可以看到, 一个 socket 的缓冲是一个 mbuf 链 (sb_mb 域). mbuf 是 socket 及以下的协议实现的基本数据封装, 传输和控制单位. 其结构定义在 sys/mbuf.h. 其中 m_hdr 是各种 mbuf 共同的头部信息, 最为重要.
我们首先来看一个注释, 弄明白一些重要的 size 问题. 我们使用 i386 的标准 . 即 MSIZE = 256, MCLBYTES = 2048.
/** Mbufs are of a single size, MSIZE (machine/param.h), which* includes overhead.
An mbuf may add a single "mbuf cluster" of size* MCLBYTES (also in machine/param.h), which has no additional overhead* and is used instead of the internal data area; this is done when* at least MINCLSIZE of data must be stored.*/也就是说, 一个 mbuf 有 256 字节大, 如果它使用扩展空间, 可以用到 2048 个字节. 又, mbuf 携带的数据分两种: 正常数据和报文头部. 那么, 如果不使用扩展空间 (m_ext), mbuf 在携带正常数据的时候应可以使用 256 - sizeof(m_hdr) 的空间, 而携带报文头部时这个大小应该是 256 - sizeof(m_hdr) - sizeof(pkthdr).
定义 MBUF 结构在 269 行, 真正的结构描述在 225 行. 可以看到, 我们最终得出的是, 在不使用扩展空间时. 一个 mbuf 能携带 256 - 30 = 226bytes 的普通数据 和 256 - 30 - 20 = 206 bytes 的协议头.
我们要对 m_hdr 结构很熟悉. 也应该看看 kern/uipc_mbuf.c 的函数接口.
连接建立
socket(2)
sys_socket() 在 uipc_syscalls.c 中. 它要完成两个工作: 建立文件结构和相应的接口; 调用 socreate 完成真正的 socket 建立工作. 其中第一项工作是我们熟悉的, 注意 89 行起三行填写参数的代码, 还要注意 socketops 的内容, 这是我们对 socket 调用 read(2) 等调用时将要进入的地方. 我们现在来看 socreate 是怎么完成第二项工作的.
socreate 在 uipc_socket.c 中. 在这里, 我们首先要利用 pffindproto() /pffindtype() 根据参数找到相应的 protosw 结构, 即到底层协议实现的接口 . 然后申请 socket 结构的内存空间, 填写参数. 上层机构建立完毕后, 我们要通知协议实现加入这个 socket, 并真正创建协议相关的通讯机构. 我们使用其 pr_usrreq 的 PRU_ATTACH 操作完成这一点.
至此, 从顶层的文件接口, 到底层的协议实现机构, 整个 socket 创建完成.
bind(2)
在 sys_bind 中我们可以看到 socket 系统的一种通用的处理模式. 它首先调用 getsock(), 根据 fd 得到相应的 socket 结构. 用 sockargs 把参数按格式复制并封装到一个 mbuf 里, 然后传到底层的 soxxx 函数进行处理. 而 sobind() 的工作非常简单, 只是直接向下调用即可.
listen(2)
listen(2) 的执行过程道理同上. 它只是通知协议实现要进入 listen 状态而已.
accept(2)
accept(2) 的实现比较复杂. 它等待并获取连接队列上的第一个连接, 为它建立 socket 和 fd, 真正建立一条点对点的通信线路. 我们首先要根据 socket 结构描述中的一段注释弄明白连接队列上的连接是怎么来的, 怎么放的.
/** Variables for connection queueing.* Socket where accepts occur is so_head in all subsidiary sockets.* If so_head is 0, socket is not related to an accept.* For head socket so_q0 queues partially completed connections,* while so_q is a queue of connections ready to be accepted.* If a connection is aborted and it has so_head set, then* it has to be pulled out of either so_q0 or so_q.* We allow connections to queue up based on current queue lengths* and limit on number of queued connections for this socket.*/sys_accept() 照样使用 getsock 取回 socket, 至 199 行为止, 都是检查参数的过程. 200 行 的 while scope 完成了最重要的等待连接到来的过程. 为新的 socket 申请文件描述符后, 我们要使用 soqremque 将头部的连接 socket 从队列中取下, 然后才能安全正确地组建好新 socket 的上层结构.
接着, 我们要调用 soaccept(). 这里, 我们要通过底层协议实现, 取得对端地址返回给用户, 以备后用.
connect(2)
sys_connect() 的工作是明显的. 取得 socket 后, 它首先要判断这个 socket 是否已经连接上了以防止重复连接; 接着, 它调用 soconnect() 使自己进入请求连接状态; 现在, 它就可以安心地等待 connect 的完成, 因为这时候已经是 connect 的对端的事了. 最后, 我们处理错误, 退出.
soconnect 直接调用底层协议实现. 忽略.
数据传输
sosend()
无论是 send(2), 还是对 socket fd 的 write(2), 最终都是调用 uipc_socket.c: sosend() 来完成.
在函数开头至 757 行止, 我们获取了一些重要参数, 如是否允许分段发送 (atomic), 要传送的字节数 (resid), 是否使用路由选择 (dontroute) 等.
接着, 我们首先对缓冲区加锁. 然后在 while 循环中试图发送所有数据. 我们每次发送之前都应该先检查状态, 比如端口是否关闭, socket 是否还在连接等, 这就是 line 764 - 779 的代码. 接着, 直到 799 行, 我们要检查 socket 的发送缓存的空间是否足够, 有条件时等待空间 (下层协议实现正使用部分空间, 他们完成释放后就能凑够空间). 如果是 atomic 而空间不够的话, 我们在这里就要挂了.
接下来的 do 循环, 我们要将数据装入 mbuf 然后发送出去. line 801 - 868 是将 (一部分) 待发数据装入 mbuf 的过程, 如果 uio == NULL, 则数据已经分块装好在 top 中, 我们就什么都不用干, 否则, 我们就把数据装进一个 mbuf 链中, 每次填充的 mbuf 是 m, 然后通过 mp 将每个 mbuf 的 next 域连成一条链, 然后, 我们在 879 行, 把数据交给协议实现去传送.
从函数整体来看, 函数有三重 do 循环, 第一层要解决把一个大于 sockbuf 容量的消息分块发送 (分成不同的报文) 的问题, 第二层是要解决把读到的数据分成一个个 mbuf 存放的问题, 最里一层是要处理从 uio 多次读数据才能填充好一个 mbuf 问题. 通过这种方法解决了各层机构容量不匹配的问题.
soreceive()
无论是 recv(2), 还是对 socket fd 的 read(2), 最终都是调用 uipc_socket.c: soreceive() 来完成.
首先读读前面的注释, 我们再来看它的实现. 我们首先要以 PEEK 方式 (读数据而不取下 mbuf) 读取带外数据, 然后, 若缓冲区中的数据不够我们所要求的, 我们将等待 (line 989 - 1036).
运行到达 dontblock 标记处时, 我们要开始真正的读缓冲过程. 这是 m 指向我们要读取的 mbuf 链. 注意现在缓冲区中的 mbuf 可能分数几个不同的 packet, 这由 mbuf 头部的 m_nextpkt 提供, 在这里开始由 nextrecord 指向. 根据协议要求, 在真正读数据之前, 我们可能首先要读出地址信息 (line 1051 - 1074), 和控制信息 (1075 - 1101). 如果除此以外我们还有数据, 我们把数据的起始作为报头, 提取信息, 然后在 line 1137 的 while 处开始真正的读数据过程.
获取本次需要读取的长度后, 我们在 1165 真正把数据从 mbuf 中读出, 在 1187 处, 如果我们已经把一个 mbuf 中的数据读完, 就删掉这个 mbuf, 并专向下一个 --- 此时, 如果我们已经把一个 packet 读完, 我们会转向下一个 packet, 即下一个 mbuf 链. 接下来, 如果还没读够数据, 我们可能要通知底层实现读入更多数据 (line 1269) 并等待数据的到来 (line 1277) 数据读取的过程便这样循环完成.
最后是收尾工作. XXX. 其实没设呢么好注意的.
连接关闭
soclose()
当对一个连向 socket 的 fd 进行 close(2) 操作时, 会调用 soclose() 例程, 关闭与撤消 socket 相关的机制.
首先, 如果这是一个 server 端的 socket, 它就会有等待 accept 的 socket,