详解Java规则引擎与其API
本文对Java规则引擎与其API(JSR-94)及相关实现做了较详细的介绍,对其体系结构和API应用有较详尽的描述,并指出Java规则引擎,规则语言,JSR-94的相互关系,以及JSR-94的不足之处和展望复杂企业级项目的开发以及其中随外部条件不断变化的业务规则(business logic),迫切需要分离商业决策者的商业决策逻辑和应用开发者的技术决策,并把这些商业决策放在中心数据库或其他统一的地方,让它们能在运行时(即商务时间)可以动态地管理和修改从而提供软件系统的柔性和适应性。规则引擎正是应用于上述动态环境中的一种解决方法。
本文第一部分简要介绍了规则引擎的产生背景和基于规则的专家系统,第二部分介绍了什么是规则引擎及其架构和算法,第三部分介绍了商业产品和开源项目实现等各种Java规则引擎,第四部分对Java规则引擎API(JSR-94)作了详细介绍,讲解了其体系结构,管理API和运行时API及相关安全问题,第五部分则对规则语言及其标准化作了探讨,第六部分给出了一个使用Java规则引擎API的简单示例,第七部分给予小结和展望。
1、 介绍
1.1 规则引擎产生背景
企业管理者对企业级IT系统的开发有着如下的要求:(1)为提高效率,管理流程必须自动化,即使现代商业规则异常复杂(2)市场要求业务规则经常变化,IT系统必须依据业务规则的变化快速、低成本的更新(3)为了快速、低成本的更新,业务人员应能直接管理IT系统中的规则,不需要程序开发人员参与。而项目开发人员则碰到了以下问题:(1)程序=算法+数据结构,有些复杂的商业规则很难推导出算法和抽象出数据模型(2)软件工程要求从需求->设计->编码,然而业务规则常常在需求阶段可能还没有明确,在设计和编码后还在变化,业务规则往往嵌在系统各处代码中(3)对程序员来说,系统已经维护、更新困难,更不可能让业务人员来管理。
基于规则的专家系统的出现给开发人员以解决问题的契机。规则引擎由基于规则的专家系统中的推理引擎发展而来。下面简要介绍一下基于规则的专家系统。
1.2 基于规则的专家系统(RBES)
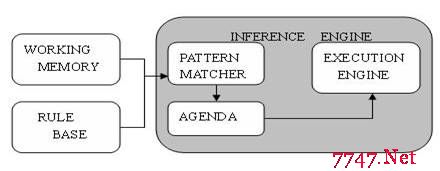
专家系统是人工智能的一个分支,它模仿人类的推理方式,使用试探性的方法进行推理,并使用人类能理解的术语解释和证明它的推理结论。专家系统有很多分类:神经网络、基于案例推理和基于规则系统等。RBES包括三部分:Rule Base(knowledge base)、Working Memory(fact base)和Inference Engine(推理引擎)。它们的结构如下所示:
图1.基于规则的专家系统组成
如上图所示,推理引擎包括三部分:Pattern Matcher、Agenda和Execution Engine。Pattern Matcher何时执行哪个规则;Agenda管理PatternMatcher挑选出来的规则的执行次序;Execution Engine负责执行规则和其他动作。
推理引擎通过决定哪些规则满足事实或目标,并授予规则优先级,满足事实或目标的规则被加入议程。存在两者推理方式:演绎法(Forward-Chaining正向链)和归纳法(Backward-Chaining反向链)。演绎法从一个初始的事实出发,不断地应用规则得出结论(或执行指定的动作)。而归纳法则是从假设出发,不断地寻找符合假设的事实。
2、 规则引擎
2.1 业务规则
一个业务规则包含一组条件和在此条件下执行的操作,它们表示业务规则应用程序的一段业务逻辑。业务规则通常应该由业务分析人员和策略管理者开发和修改,但有些复杂的业务规则也可以由技术人员使用面向对象的技术语言或脚本来定制。业务规则的理论基础是:设置一个或多个条件,当满足这些条件时会触发一个或多个操作。2.2 规则引擎
什么是规则引擎?规则引擎是如何执行规则的?这可以称之为"什么"与"如何"的问题。到底规则引擎是什么还是目前业界一个比较有争议的问题,在JSR-94种也几乎没有定义。可以这样认为充分定义和解决了"如何"的问题,"什么"问题本质上也迎刃而解。也许这又是一种"先有蛋还是先有鸡"哲学争论。今后标准规则语言的定义和推出及相关标准的制定应该可以给这样的问题和争论划上一个句号。本文中,暂且这样述说什么是规则引擎:规则引擎由推理引擎发展而来,是一种嵌入在应用程序中的组件,实现了将业务决策从应用程序代码中分离出来,并使用预定义的语义模块编写业务决策。接受数据输入,解释业务规则,并根据规则做出业务决策。2.3 规则引擎的使用方式
由于规则引擎是软件组件,所以只有开发人员才能够通过程序接口的方式来使用和控制它,规则引擎的程序接口至少包含以下几种API:加载和卸载规则集的API;数据操作的API;引擎执行的API。开发人员在程序中使用规则引擎基本遵循以下5个典型的步骤:创建规则引擎对象;向引擎中加载规则集或更换规则集;向引擎提交需要被规则集处理的数据对象集合;命令引擎执行;导出引擎执行结果,从引擎中撤出处理过的数据。使用了规则引擎之后,许多涉及业务逻辑的程序代码基本被这五个典型步骤所取代。一个开放的业务规则引擎应该可以"嵌入"在应用程序的任何位置,不同位置的规则引擎可以使用不同的规则集,用于处理不同的数据对象。此外,对使用引擎的数量没有限制。
2.4 规则引擎架构与推理
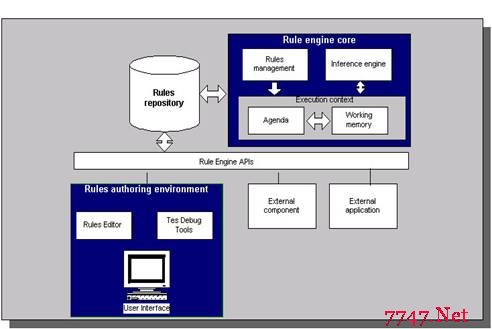
规则引擎的架构如下图所示:图2. 业务规则引擎架构
规则引擎的推理步骤如下:a. 将初始数据(fact)输入至工作内存(Working Memory)。b. 使用Pattern Matcher将规则库(Rules repository)中的规则(rule)和数据(fact)比较。c. 如果执行规则存在冲突(conflict),即同时激活了多个规则,将冲突的规则放入冲突集合。d. 解决冲突,将激活的规则按顺序放入Agenda。e. 执行Agenda中的规则。重复步骤b至e,直到执行完毕Agenda中的所有规则。
任何一个规则引擎都需要很好地解决规则的推理机制和规则条件匹配的效率问题。
当引擎执行时,会根据规则执行队列中的优先顺序逐条执行规则执行实例,由于规则的执行部分可能会改变工作区的数据对象,从而会使队列中的某些规则执行实例因为条件改变而失效,必须从队列中撤销,也可能会激活原来不满足条件的规则,生成新的规则执行实例进入队列。于是就产生了一种"动态"的规则执行链,形成规则的推理机制。这种规则的"链式"反应完全是由工作区中的数据驱动的。
规则条件匹配的效率决定了引擎的性能,引擎需要迅速测试工作区中的数据对象,从加载的规则集中发现符合条件的规则,生成规则执行实例。1982年美国卡耐基·梅隆大学的Charles L. Forgy发明了一种叫Rete算法,很好地解决了这方面的问题。目前世界顶尖的商用业务规则引擎产品基本上都使用Rete算法。
2.5 规则引擎的算法
大部分规则引擎产品的算法,基本上都来自于Dr. Charles Forgy在1979年提出的RETE算法及其变体,Rete算法是目前效率最高的一个Forward-Chaining推理算法,Drools项目是Rete算法的一个面向对象的Java实现,Rete算法其核心思想是将分离的匹配项根据内容动态构造匹配树,以达到显著降低计算量的效果。详情请见CIS587:The RETE Algorithm,The Rete Algorithm,RETE演算法,《专家系统原理与编程》中第11章等。3、 Java规则引擎
目前主流的规则引擎组件多是基于Java和C++程序语言环境,已经有多种Java规则引擎商业产品与开源项目的实现,其中有的已经支持JSR94,有的正朝这个方向做出努力,列出如下:3.1 Java规则引擎商业产品
Java规则引擎商业产品主要有(Jess不是开源项目,它可以免费用于学术研究,但用于商业用途则要收费):
3.2 Java规则引擎开源项目
开源项目的实现主要包括:Drools - Drools规则引擎应用Rete算法的改进形式Rete-II算法。从内部机制上讲,它使用了和Forgy的算法相同的概念和方法,但是增加了可与面向对象语言无缝连接的节点类型。
Mandarax 基于反向推理(归纳法)。能够较容易地实现多个数据源的集成。例如,数据库记录能方便地集成为事实集(facts sets),reflection用来集成对象模型中的功能。目前不支持JSR 94
OFBiz Rule Engine - 支持归纳法(Backward chaining).最初代码基于Steven John Metsker的"Building Parsers in Java",不支持JSR 94

补充:软件开发 , Java ,




