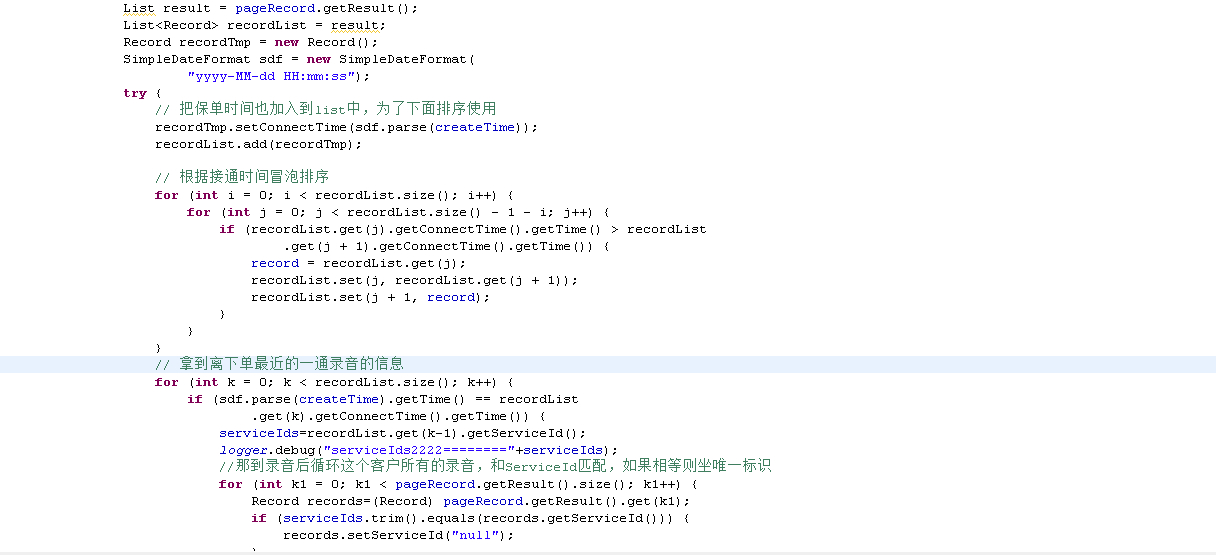
Java中创建对象的常规方式有如下5种:
1. 通过new调用构造器创建Java对象;
2. 通过Class对象的newInstance()方法调用构造器创建对象;
3. 通过Java的反序列化机制从IO流中恢复对象;
4. 通过Java对象提供的clone方法复制一个对象;
5. 基本类型及String类型,可以直接赋予直接量。
对于Java中的字符串直接量,JVM会使用一个字符串池来保存它们:当第一次使用某个直接量时,JVM会将它放入字符串池中缓存,在一般情况下,字符串池中的字符串不会被Java回收器回收,当程序再次使用该直接量时,无需重新创建一个新的字符串,而是直接让引用变量指向字符串池中已经存在的字符串。
字符串池中的字符串是不会被回收的,这是Java内存泄漏的一个原因。
如果程序需要一个字符序列会改变的字符串,那么应该考虑使用StringBuilder或StringBuffer,当然,最好还是使用StringBuilder,因为对于线程安全的StringBuffer,StringBuilder是线程不安全的,也就是说,StringBuffer中的绝大部分代码都加了synchronized修饰符。
如果你的代码所在的程序或进程是多个线程同时运行的,而这些线程会同时运行这段代码,如果每次运行结果和单线程运行结果一样,而且其他变量的值也和预期的一样,就是线程安全的,或者说,多个线程的切换不会导致该接口的执行结果存在二义性,我们就说该接口是线程安全的。
Java是强类型语言,所谓强类型语言,通常具有两个基本特征:
1. 所有变更必须先声明才能使用,声明变量时必须指定该变量的数据类型;
2. 一量某个变量的数据类型确定下来,那么该变量永远只能接受该类型的数据,不能接受其他类型的数据。
当一个算术表达式中包含多个基本类型时,整个算术表达式的数据类型会自动提升,这是我们已经知道的规定。在此之外有个特例,请看以下代码:
[java]
<span style="font-size:18px">short sv = 5;
sv = sv - 2;</span>
我们通常不能理解的一个问题是:这段代码会报错。但结合数据类型的自动提升,我们可以这样理解:sv - 2中,2是int型,所以sv - 2的结果是一个int型,所以不能赋值给sv。
再看以下代码:
[java]
<span style="font-size:18px">short sv = 5;
sv -= 2;</span>
如果你再用自动类型提升来理解的话,你会解释为这一段代码结果也会报错,可惜,Java中还有另一规定:复合赋值运算符包含了一个隐式的类型转换,sv -= 2其实等价于sv = (short)(sv - 2)。
显然这里又出现了另外一个问题:将巨大的int转化为short会出什么问题吗?且看如下代码:
[java]
<span style="font-size:18px">short sv = 5;
sv += 9000;</span>
我们已知,short类型的数值范围在-32768~32767之间,所以当把9005赋值给sv时,就会出现高位截断,sv的最终结果为24471。
由此可见,复合赋值运算符简单、方便,而且具有性能上的优势,但复合赋值运算符可能有一定的危险:它潜在的隐式类型转换可能会不知不觉中导致计算结果的高位截断。
且看以下代码:
[java]
<span style="font-size:18px">List list = new ArrayList();
list.add("a");
list.add("b");
list.add("c");
List<Integer> intList = list;
for (int i = 0; i < list.size(); i++) {
System.out.println(intList.get(i));
}</span>
当我看到这段代码的时候,我理所当然的认为这段代码是错误的,因为list里面包含的是String,不能赋值给List<Integer>,而在Eclipse里面运行这段代码后,你会发现这段代码没有任何错误,可以编译,也可以运行,这就是泛型里面的陷阱。在使用泛型时,要注意以下几点:
1. 当程序把一个原始类型的变量赋值给一个带泛型信息的变量时,总是可以通过编译,只是会提出一些警告,如上述代码中,List<Integer> intList = list并不会报错;
2. 当程序试图访问带泛型声明的集合的集合元素时,编译器总是把集合元素当成泛型类型处理——它并不关心集合里集合元素的实际类型,如上述代码中,intList.get(i)的结果是一个Integer类型;
3. 当程序试图访问带泛型声明的集合的集合元素时,JVM会遍历每个集合元素自动执行强制类型转换,如果集合元素的实际类型与集合所带的泛型信息不匹配,运行时将引发ClassCastException异常,假设在上述代码的for循环中加上Integer in = intList.get(i),就会报此异常。
上面讲的是把原始类型赋值给泛型类型,假如反过来呢?且看以下代码:
[java]
List<String> list = new ArrayList<String>();
list.add("a");
list.add("b");
list.add("c");
List li = list;
for (int i = 0; i < list.size(); i++) {
System.out.println(li.get(i));
System.out.println(li.get(i).length()); // 1)
}
你会发现1)处的代码编译错误,这是因为——把一个带泛型类型的Java变量赋值给一个不带泛型类型的变量时,Java程序会发生擦除,这种擦除不仅仅会擦除实际类型实参,还会擦除所有泛型信息,如上述代码,li.get(i)是终被当成一个Object对象使用。
Java泛型设计原则:如果一段代码在编译时系统没有产生“[unchecked]未经检查的转换”警告,则程序在运行时不会引发ClassCastException异常。
从JDK1.5开始,Java提供了三种方式来创建、启动多线程:
1. 继承Thread类来创建线程类,重写run()方法作为线程执行体;
2. 实现Runnable接口来创建线程类,重写run()方法作为线程执行体;
3. 实现Callable接口来创建线程类,重写run()方法作为线程执行体;
其中,第一种方式效果最差,它有两点坏处:
1. 线程类继承了Thread类,无法再继承其他父类;
2. 因为每条线程都是一个Thread子类的实例,因此多个线程之间共享数据比较麻烦。
对于第二种和第三种,它们的本质是一样的,只是Callable接口里面包含的call()方法既可以声明抛出异常,也可以拥有返回值。
无论使用哪种方式,都不要调用run()方法来启动线程:启动线程应该使用start()方法,如果程序从未调用线程对象的start()方法来启动它,那么这个线程对象将一直处于新建状态。