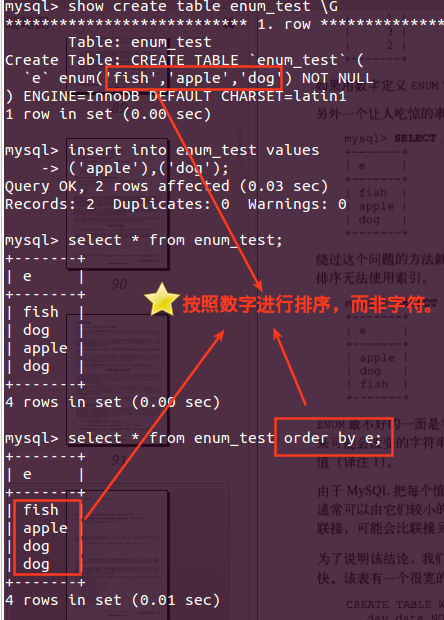
mysql index索引使用方法
MYSQL如果使用索引(from mysql reference)
索引用于快速找出在某个列中有一特定值的行。不使用索引,MySQL必须从第1条记录开始然后读完整个表直到找出相关的行。表越大,花费的时间越多。如果表中查询的列有一个索引,MySQL能快速到达一个位置去搜寻到数据文件的中间,没有必要看所有数据。如果一个表有1000行,这比顺序读取至少快100倍。注意如果你需要访问大部分行,顺序读取要快得多,因为此时我们避免磁盘搜索。大多数MySQL索引(PRIMARY KEY、UNIQUE、INDEX和FULLTEXT)在B树中存储。只是空间列类型的索引使用R-树,并且MEMORY表还支持hash索引。字符串自动地压缩前缀和结尾空格。总的来说,按后面的讨论使用索引。本节最后描述hash索引(用于MEMORY表)的特征。索引用于下面的操作:? 快速找出匹配一个WHERE子句的行。? 删除行。如果可以在多个索引中进行选择,MySQL通常使用找到最少行的索引。? 当执行联接时,从其它表检索行。? 对具体有索引的列key_col找出MAX()或MIN()值。由预处理器进行优化,检查是否对索引中在key_col之前发生所有关键字元素使用了WHERE key_part_# = constant。在这种情况下,MySQL为每个MIN()或MAX()表达式执行一次关键字查找,并用常数替换它。如果所有表达式替换为常量,查询立即返回。例如:? SELECT MIN(key_part2),MAX(key_part2) FROM tbl_name WHERE key_part1=10;? 如果对一个可用关键字的最左面的前缀进行了排序或分组(例如,ORDER BY key_part_1,key_part_2),排序或分组一个表。如果所有关键字元素后面有DESC,关键字以倒序被读取。参见7.2.12节,“MySQL如何优化ORDER BY”。? 在一些情况中,可以对一个查询进行优化以便不用查询数据行即可以检索值。如果查询只使用来自某个表的数字型并且构成某些关键字的最左面前缀的列,为了更快,可以从索引树检索出值。? SELECT key_part3 FROM tbl_name? WHERE key_part1=1假定你执行下面的SELECT语句:mysql> SELECT * FROM tbl_name WHERE col1=val1 AND col2=val2;如果col1和col2上存在一个多列索引,可以直接取出相应行。如果col1和col2上存在单列索引,优化器试图通过决定哪个索引将找到更少的行来找出更具限制性的索引并且使用该索引取行。如果表有一个多列索引,优化器可以使用最左面的索引前缀来找出行。例如,如果有一个3列索引(col1,col2,col3),则已经对(col1)、(col1,col2)和(col1,col2,col3)上的搜索进行了索引。如果列不构成索引最左面的前缀,MySQL不能使用局部索引。假定有下面显示的SELECT语句:
SELECT * FROM tbl_name WHERE col1=val1;SELECT * FROM tbl_name WHERE col1=val1 AND col2=val2; SELECT * FROM tbl_name WHERE col2=val2;SELECT * FROM tbl_name WHERE col2=val2 AND col3=val3;如果 (col1,col2,col3)有一个索引,只有前2个查询使用索引。第3个和第4个查询确实包括索引的列,但(col2)和(col2,col3)不是 (col1,col2,col3)的最左边的前缀。也可以在表达式通过=、>、>=、<、<=或者BETWEEN操作符使用B-树索引进行列比较。如果LIKE的参数是一个不以通配符开头的常量字符串,索引也可以用于LIKE比较。例如,下面的SELECT语句使用索引:
SELECT * FROM tbl_name WHERE key_col LIKE 'Patrick%';SELECT * FROM tbl_name WHERE key_col LIKE 'Pat%_ck%';在第1个语句中,只考虑带'Patrick' <=key_col < 'Patricl'的行。在第2个语句中,只考虑带'Pat' <=key_col < 'Pau'的行。下面的SELECT语句不使用索引:SELECT * FROM tbl_name WHERE key_col LIKE '%Patrick%'; SELECT * FROM tbl_name WHERE key_col LIKE other_col;在第一条语句中,LIKE值以一个通配符字符开始。在第二条语句中,LIKE值不是一个常数。如果使用... LIKE '%string%'并且string超过3个字符,MySQL使用Turbo Boyer-Moore算法初始化字符串的模式然后使用该模式来更快地进行搜索。如果col_name被索引,使用col_name IS NULL的搜索将使用索引。任何不跨越WHERE子句中的所有AND级的索引不用于优化查询。换句话说,为了能够使用索引,必须在每个AND组中使用索引前缀。下面的WHERE子句使用索引:... WHERE index_part1=1 AND index_part2=2 AND other_column=3 /* index = 1 OR index = 2 */ ... WHERE index=1 OR A=10 AND index=2 /* optimized like "index_part1='hello'" */ ... WHERE index_part1='hello' AND index_part3=5 /* Can use index on index1 but not on index2 or index3 */ ... WHERE index1=1 AND index2=2 OR index1=3 AND index3=3;下面的WHERE子句不使用索引:/* index_part1 is not used */ ... WHERE index_part2=1 AND index_part3=2 /* Index is not used in both parts of the WHERE clause */ ... WHERE index=1 OR A=10 /* No index spans all rows */ ... WHERE index_part1=1 OR index_part2=10有时MySQL不使用索引,即使有可用的索引。一种情形是当优化器估计到使用索引将需要MySQL访问表中的大部分行时。(在这种情况下,表扫描可能会更快些,因为需要的搜索要少)。然而,如果此类查询使用LIMIT只搜索部分行,MySQL则使用索引,因为它可以更快地找到几行并在结果中返回。Hash索引还有一些其它特征:? 它们只用于使用=或<=>操作符的等式比较(但很快)。它们用于比较 操作符,例如发现范围值的<。? 优化器不能使用hash索引来加速ORDER BY操作。(该类索引不能用来按顺序搜索下一个条目)。? MySQL不能确定在两个值之间大约有多少行(这被范围优化器用来确定使用哪个索引)。如果你将一个MyISAM表改为hash-索引的MEMORY表,会影响一些查询。? 只能使用整个关键字来搜索一行。(用B-树索引,任何关键字的最左面的前缀可用来找到行)。EXPLAIN使用方法EXPLAIN tbl_name或:EXPLAIN [EXTENDED] SELECT select_optionsEXPLAIN语句可以用作DESCRIBE的一个同义词,或获得关于MySQL如何执行SELECT语句的信息:? EXPLAIN tbl_name是DESCRIBE tbl_name或SHOW COLUMNS FROM tbl_name的一个同义词。? 如果在SELECT语句前放上关键词EXPLAIN,MySQL将解释它如何处理SELECT,提供有关表如何联接和联接的次序。该节解释EXPLAIN的第2个用法。借助于EXPLAIN,可以知道什么时候必须为表加入索引以得到一个使用索引来寻找记录的更快的SELECT。如果由于使用不正确的索引出现了问题,应运行ANALYZE TABLE更新表的统计(例如关键字集的势),这样会影响优化器进行的选择。还可以知道优化器是否以一个最佳次序联接表。为了强制优化器让一个SELECT语句按照表命名顺序的联接次序,语句应以STRAIGHT_JOIN而不只是SELECT开头。EXPLAIN为用于SELECT语句中的每个表返回一行信息。表以它们在处理查询过程中将被MySQL读入的顺序被列出。MySQL用一遍扫描多次联接(single-sweep multi-join)的方式解决所有联接。这意味着MySQL从第一个表中读一行,然后找到在第二个表中的一个匹配行,然后在第3个表中等等。当所有的表处理完后,它输出选中的列并且返回表清单直到找到一个有更多的匹配行的表。从该表读入下一行并继续处理下一个表。当使用EXTENDED关键字时,EXPLAIN产生附加信息,可以用SHOW WARNINGS浏览。该信息显示优化器限定SELECT语句中的表和列名,重写并且执行优化规则后SELECT语句是什么样子,并且还可能包括优化过程的其它注解。EXPLAIN的每个输出行提供一个表的相关信息,并且每个行包括下面的列:? idSELECT识别符。这是SELECT的查询序列号。? select_typeSELECT类型,可以为以下任何一种:o SIMPLE简单SELECT(不使用UNION或子查询)o PRIMARY最外面的SELECTo UNIONUNION中的第二个或后面的SELECT语句o DEPENDENT UNIONUNION中的第二个或后面的SELECT语句,取决于外面的查询o UNION RESULTUNION的结果。o SUBQUERY子查询中的第一个SELECTo DEPENDENT SUBQUERY子查询中的第一个SELECT,取决于外面的查询o DERIVED导出表的SELECT(FROM子句的子查询)? table输出的行所引用的表。? type联接类型。下面给出各种联接类型,按照从最佳类型到最坏类型进行排序:o system表仅有一行(=系统表)。这是const联接类型的一个特例。o const表最多有一个匹配行,它将在查询开始时被读取。因为仅有一行,在这行的列值可被优化器剩余部分认为是常数。const表很快,因为它们只读取一次!const用于用常数值比较PRIMARY KEY或UNIQUE索引的所有部分时。在下面的查询中,tbl_name可以用于const表:SELECT * from tbl_name WHERE primary_key=1; SELECT * from tbl_name WHERE primary_key_part1=1 and primary_key_part2=2;o eq_ref对于每个来自于前面的表的行组合,从该表中读取一行。这可能是最好的联接类型,除了const类型。它用在一个索引的所有部分被联接使用并且索引是UNIQUE或PRIMARY KEY。eq_ref可以用于使用= 操作符比较的带索引的列。比较值可以为常量或一个使用在该表前面所读取的表的列的表达式。在下面的例子中,MySQL可以使用eq_ref联接来处理ref_tables:
o ref对于每个来自于前面的表的行组合,所有有匹配索引值的行将从这张表中读取。如果联接只使用键的最左边的前缀,或如果键不是UNIQUE或PRIMARY KEY(换句话说,如果联接不能基于关键字选择单个行的话),则使用ref。如果使用的键仅仅匹配少量行,该联接类型是不错的。ref可以用于使用=或<=>操作符的带索引的列。在下面的例子中,MySQL可以使用ref联接来处理ref_tables:
补充:数据库,mysql教程