granfna展示mysql数据源 time series查询编辑器
示例:Time series查询
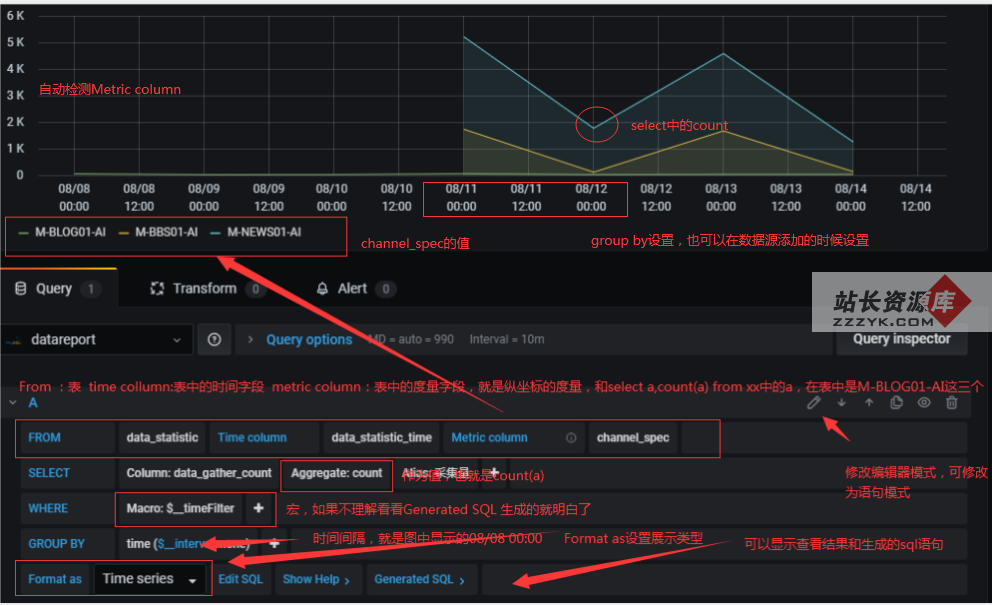

time series在编辑查询的时候有很多grafana默认的设置:
- 查询必须返回一列time,该列返回SQL日期时间或表示Unix纪元的任何数字数据类型。也就是示例中的time column设置。
- 除time和metric以外的任何列均被视为值列。也就是示例中select。
- 返回一个名为metricvalue的列,该列用作度量标准名称。也就是示例中的metric column设置。
- 如果返回多个值列和名为的列,metric则此列将用作系列名称的前缀(仅在Grafana 5.3+中可用)。
1.Format as
format as 可选择两种:table和Time series。table比较简单,sql的约束也少,基本上就是mysql的查询结果,按表格展示出来。
time series有一些麻烦,本文也重点讲time series
2.宏
| 宏示例 | 描述 |
|---|---|
$__time(dateColumn)
|
将被表达式替换以转换为UNIX时间戳并将列重命名为time_sec。例如,UNIX_TIMESTAMP(dateColumn)为time_sec
|
$__timeEpoch(dateColumn)
|
将被表达式替换以转换为UNIX时间戳并将列重命名为time_sec。例如,UNIX_TIMESTAMP(dateColumn)为time_sec
|
$__timeFilter(dateColumn)
|
将使用指定的列名替换为时间范围过滤器。例如,dateColumn BETWEEN FROM_UNIXTIME(1494410783)和FROM_UNIXTIME(1494410983) |
$__timeFrom()
|
将由当前活动时间选择的开始代替。例如,FROM_UNIXTIME(1494410783) |
$__timeTo()
|
将被当前活动时间选择的结尾替换。例如,FROM_UNIXTIME(1494410983) |
$__timeGroup(dateColumn,'5m')
|
将由GROUP BY子句中可用的表达式替换。例如,* cast(cast(cast(UNIX_TIMESTAMP(dateColumn)/(300)签名)300签名)), |
$__timeGroup(dateColumn,'5m', 0)
|
与上述相同,但具有填充参数,因此该系列中的缺失点将由grafana添加,并将0用作值。 |
$__timeGroup(dateColumn,'5m', NULL)
|
与上述相同,但将NULL用作缺失点的值。 |
$__timeGroup(dateColumn,'5m', previous)
|
与上面相同,但是如果未看到任何值但将使用NULL,则该系列中的先前值将用作填充值(仅在Grafana 5.3+中可用)。 |
$__timeGroupAlias(dateColumn,'5m')
|
将替换为与$ __ timeGroup相同,但添加的列别名(仅在Grafana 5.3+中可用)。 |
$__unixEpochFilter(dateColumn)
|
将使用指定列名的时间范围过滤器替换,时间以Unix时间戳表示。例如,dateColumn> 1494410783和dateColumn <1494497183 |
$__unixEpochFrom()
|
将被当前活动时间选择的开始替换为Unix时间戳。例如1494410783 |
$__unixEpochTo()
|
当前活动时间选择的结尾将被替换为Unix时间戳。例如1494497183 |
$__unixEpochNanoFilter(dateColumn)
|
将被使用指定列名的时间范围过滤器替换,时间以纳秒时间戳表示。例如,dateColumn> 1494410783152415214和dateColumn <1494497183142514872 |
$__unixEpochNanoFrom()
|
将被当前活动时间选择的开始替换为纳秒时间戳。例如1494410783152415214 |
$__unixEpochNanoTo()
|
当前活动时间选择的结尾将被替换为纳秒级时间戳。例如1494497183142514872 |
$__unixEpochGroup(dateColumn,'5m', [fillmode])
|
与$ __ timeGroup相同,但时间存储为Unix时间戳(仅在Grafana 5.3+中可用)。 |
$__unixEpochGroupAlias(dateColumn,'5m', [fillmode])
|
与上述相同,但还添加了列别名(仅在Grafana 5.3+中可用)。 |
3.Generated Sql
SELECT UNIX_TIMESTAMP(data_statistic_time) DIV 600 * 600 AS "time",
channel_spec AS metric,
count(data_gather_count) AS "采集量" FROM data_statistic WHERE data_statistic_time BETWEEN FROM_UNIXTIME(1596791926) AND FROM_UNIXTIME(1597396726) GROUP BY 1,2 ORDER BY UNIX_TIMESTAMP(data_statistic_time) DIV 600 * 600