数据库学习-对数据的操作
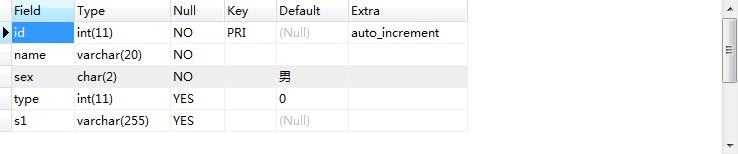
数据库学习-对数据的操作一、插入数据Insert语法如下:INSERT [LOW_PRIORITY | DELAYED | HIGH_PRIORITY] [IGNORE][INTO] tbl_name [(col_name,...)]VALUES ({expr | DEFAULT},...),(...),...[ ON DUPLICATE KEY UPDATE col_name=expr, ... ]或:INSERT [LOW_PRIORITY | DELAYED | HIGH_PRIORITY] [IGNORE][INTO] tbl_nameSET col_name={expr | DEFAULT}, ...[ ON DUPLICATE KEY UPDATE col_name=expr, ... ]或:INSERT [LOW_PRIORITY | HIGH_PRIORITY] [IGNORE][INTO] tbl_name [(col_name,...)]SELECT ...[ ON DUPLICATE KEY UPDATE col_name=expr, ... ]INSERT...VALUES和INSERT...SET形式的语句根据明确指定的值插入行。INSERT...SELECT形式的语句插入从其它表中选出的行。以下操作根据a1表,下是a1表的结构1、插入单行#方式一:INSERT into a1 VALUES(1,'Jack','男',0,'py');这种存在很大的危险,因为它高度依赖表中列的定义次序,就是说以上的数据必须对应要存放的字段,一旦表结构改变了就会插入出错。#方式2 安全方式,但是比较繁琐INSERT into a1(id,name,易做图,type,s1) VALUES(2,'Lama','女',1,'json');表名后的括号明确的指出了列名,这样就能对号入座了。#方式三:与方式二异曲同工之妙,这是使用setINSERT a1 SET id=3,name='Tom',易做图='男',type=0,s1='C#';#INTO 在Insert语法中可选根据表结构可知,Insert有些可以省略列的操作,省略的条件如下:(1)、该列的定义运行Null(无值或空值)(2)、该列定义了默认值则上面的可写如下:INSERT a1 (name,s1) VALUES('Gsxj','Python');INSERT a1 set name='Zhangsan';2、插入多行#方式一:(比较繁琐)多条用分号隔开INSERT into a1 (name,易做图,type,s1) VALUES('Lisi','男',1,'Python');INSERT into a1 (name,易做图,type,s1) VALUES('Wangwu','男',3,'Java');#方式二:多条数据用逗号隔开INSERT into a1 (name,易做图,type,s1) VALUES('Lili','女',3,'java'),('Zen','男',2,'C#');3、插入检索出的数据使用 insert select 进行操作,语法如下:INSERT [LOW_PRIORITY | HIGH_PRIORITY] [IGNORE][INTO] tbl_name [(col_name,...)]SELECT ...[ ON DUPLICATE KEY UPDATE col_name=expr, ... ]使用INSERT...SELECT,您可以快速地从一个或多个表中向一个表中插入多个行。实例:INSERT into a1 (name,type)SELECT name,type FROM person;二、更新数据Update语法如下:Single-table语法:UPDATE [LOW_PRIORITY] [IGNORE] tbl_nameSET col_name1=expr1 [, col_name2=expr2 ...][WHERE where_definition][ORDER BY ...][LIMIT row_count]Multiple-table语法:UPDATE [LOW_PRIORITY] [IGNORE] table_referencesSET col_name1=expr1 [, col_name2=expr2 ...][WHERE where_definition]UPDATE语法可以用新值更新原有表行中的各列。SET子句:指示要修改哪些列和要给予哪些值。WHERE子句:指定应更新哪些行。如果没有WHERE子句,则更新所有的行。ORDER BY子句:按照被指定的顺序对行进行更新。LIMIT子句:用于给定一个限值,限制可以被更新的行的数目。UPDATE语句支持以下修饰符:如果使用LOW_PRIORITY关键词,则UPDATE的执行被延迟了,直到没有其它的客户端从表中读取为止。如果使用IGNORE关键词,则即使在更新过程中出现错误,更新语句也不会中断。如果出现了重复关键字冲突,则这些行不会被更新。如果列被更新后,新值会导致数据转化错误,则这些行被更新为最接近的合法的值。如果在一个表达式中通过tbl_name访问一列,则UPDATE使用列中的当前值。例如,以下语句把年龄列设置为比当前值多一:mysql> UPDATE person SET age=age+1;UPDATE赋值被从左到右评估。例如,以下语句对年龄列加倍,然后再进行增加:mysql> UPDATE person SET age=age*2, age=age+1;如果把一列设置为其当前含有的值,则MySQL会注意到这一点,但不会更新。如果把被已定义为NOT NULL的列更新为NULL,则该列被设置到与列类型对应的默认值,并且累加警告数。对于数字类型,默认值为0;对于字符串类型,默认值为空字符串('');对于日期和时间类型,默认值为“zero”值。UPDATE会返回实际被改变的行的数目。Mysql_info() C API函数可以返回被匹配和被更新的行的数目,以及在UPDATE过程中产生的警告的数量。您可以使用LIMIT row_count来限定UPDATE的范围。LIMIT子句是一个与行匹配的限定。只要发现可以满足WHERE子句的row_count行,则该语句中止,不论这些行是否被改变。如果一个UPDATE语句包括一个ORDER BY子句,则按照由子句指定的顺序更新行。您也可以执行包括多个表的UPDATE操作。table_references子句列出了在联合中包含的表。以下是一个例子:UPDATE items,month SET items.price=month.priceWHERE items.id=month.id;以上的例子显示出了使用逗号操作符的内部联合,但是multiple-table UPDATE语句可以使用在SELECT语句中允许的任何类型的联合,比如LEFT JOIN。注释:您不能把ORDER BY或LIMIT与multiple-table UPDATE同时使用。在一个被更改的multiple-table UPDATE中,有些列被引用。您只需要这些列的UPDATE权限。有些列被读取了,但是没被修改。您只需要这些列的SELECT权限。1、更新表易做图定行更新特定的行就需要where了,否则会更新了所有行。update person set name = 'Kimi' WHERE id =2;update person set type = 0 WHERE age>21;update person set type = 0 WHERE age>21 LIMIT 1;update person set type = 4 WHERE age>21 ORDER BY name limit 1;#使用ignore关键字update ignore person set type = '3' WHERE id = 3; #注意type类型为整型使用ignore会忽略一些类型错误,尽可能转换相近的类型。UPDATE person,a1 set person.type=a1.type WHERE person.id=a1.id;2、更新表中所有行见上三、删除数据delete语法:单表语法:DELETE [LOW_PRIORITY] [QUICK] [IGNORE] FROM tbl_name[WHERE wh上一个:数据库完整性和约束
下一个:读写文件与读写数据库的效率比较