正则问题,100分送上,非常感谢!!!!!
http://news.baidu.com/ns?from=news&cl=2&bt=0&y0=2013&m0=11&d0=6&y1=2013&m1=11&d1=6&et=0&q1=%B1%B1%BE%A9&submit=%B0%D9%B6%C8%D2%BB%CF%C2&q3=&q4=&s=1&mt=0&lm=0&begin_date=2013-11-6&end_date=2013-11-6&tn=newsdy&ct1=1&ct=1&rn=20&q6=这是一个baidu新闻的搜索结果页,循环分别得到搜索结果的前10条新闻标题链接来源等数据。
如
标题 玛歌中法文化艺术交流会在北京举行
链接 http://news.163.com/13/1111/20/9DE5FJM300014JB6.html
来源 网易新闻 2013-11-11 20:00:00
--------------------编程问答--------------------
--------------------编程问答-------------------- (?is)<h3\\sclass=\"c-title\"><a\\shref=\"([^\"]*)[^>]*>(.*?)</a>.*?<span\\sclass=\"c-author\"> ([^<]+) --------------------编程问答-------------------- HtmlAgilityPack
System.Net.WebClient wc = new System.Net.WebClient();
string html = Encoding.UTF8.GetString(wc.DownloadData("http://news.baidu.com/ns?from=news&cl=2&bt=0&y0=2013&m0=11&d0=6&y1=2013&m1=11&d1=6&et=0&q1=%B1%B1%BE%A9&submit=%B0%D9%B6%C8%D2%BB%CF%C2&q3=&q4=&s=1&mt=0&lm=0&begin_date=2013-11-6&end_date=2013-11-6&tn=newsdy&ct1=1&ct=1&rn=20&q6="));
MatchCollection mc = Regex.Matches(html, "(?is)<h3\\sclass=\"c-title\"><a\\shref=\"([^\"]*)[^>]*>(.*?)</a>.*?<span\\sclass=\"c-author\">([^>]*)", RegexOptions.Singleline);
int i = 0;
foreach (Match match in mc)
{
i++;
if (i > 10) break;
Console.WriteLine("链接:" + match.Groups[1].Value);
Console.WriteLine("标题:" + match.Groups[2].Value);
Console.WriteLine("来源:" + match.Groups[3].Value);
}
把html 当XML来用! --------------------编程问答-------------------- <h3\s*class="c-title"\s*>\s*<a (?:(?!href).)*?href="(?<链接>[^"]*)"[^>]*>(?<标题>(?:(?!</a>).|\s)*)</a>\s*</h3>\s*<span\s*class="c-author"\s*>(?<来源>[^<]*),有点粗糙,你可以在匹配之前先过滤掉不必要的,或者匹配后再单独处理
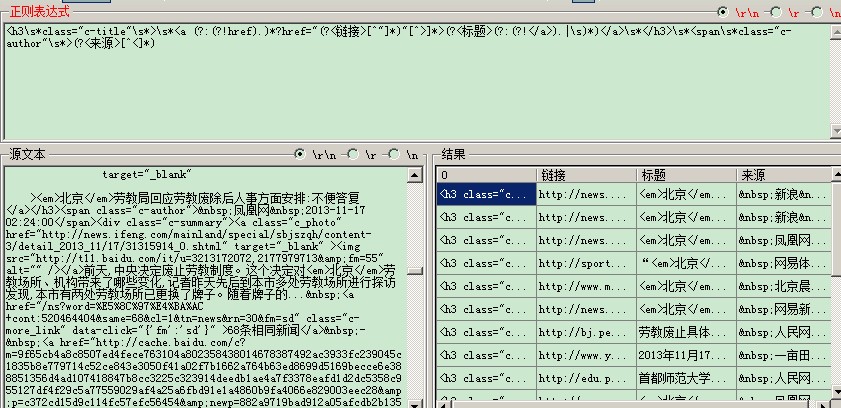 --------------------编程问答--------------------
比如说你写
--------------------编程问答--------------------
比如说你写<h3\\sclass=\"c-title\">
那要是人家在class前边加了一个别的属性,或者是class后边=号前边多写了一个空格,或者把h3改成H3了,你就不认识这个东西其实就是原来的东西了?
这就是正则的毛病。太低级了!
进行网页分析,要使用html语法分析工具,而不是只会简单地匹配几个词儿。
补充:.NET技术 , ASP.NET




