汇编语言教程学习之第五节
3.4 串操作
我们前面已经提到,内存可以和寄存器交换数据,也可以被赋予立即数。问题是,如果我们需要把内存的某部分内容复制到另一个地址,又怎么做呢?
设想将DS:SI处的连续512字节内容复制到ES:DI(先不考虑可能的重叠)。也许会有人写出这样的代码:
NextByte: | mov cx,512 mov al,ds:[si] mov es:[di],al inc si inc di loop NextByte | ; 循环次数 |
我不喜欢上面的代码。它的确能达到作用,但是,效率不好。如果你是在做优化,那么写出这样的代码意味着赔了夫人又折兵。
Intel的CPU的强项是串操作。所谓串操作就是由CPU去完成某一数量的、重复的内存操作。需要说明的是,我们常用的KMP算法(用于匹配字符串中的模式)的改进——Boyer算法,由于没有利用串操作,因此在Intel的CPU上的效率并非最优。好的编译器往往可以利用IntelCPU的这一特性优化代码,然而,并非所有的时候它都能产生最好的代码。
某些指令可以加上REP前缀(repeat, 反复之意),这些指令通常被叫做串操作指令。
举例来说,STOSD指令将EAX的内容保存到ES:DI,同时在DI上加或减四。类似的,STOSB和STOSW分别作1字节或1字的上述操作,在DI上加或减的数是1或2。
计算机语言通常是不允许二义性的。为什么我要说“加或减”呢?没错,孤立地看STOS?指令,并不能知道到底是加还是减,因为这取决于“方向”标志(DF, Direction Flag)。如果DF被复位,则加;反之则减。
置位、复位的指令分别是STD和CLD。
当然,REP只是几种可用前缀之一。常用的还包括REPNE,这个前缀通常被用来比较两个串,或搜索某个特定字符(字、双字)。REPZ、REPE、REPNZ也是非常常用的指令前缀,分别代表ZF(Zero Flag )在 不同状态时重复执行。
下面说三个可以复制数据的指令:
| 助记符 | 意义 |
| movsb | 将DS:SI的一字节复制到ES:DI,之后SI++、DI++ |
| movsw | 将DS:SI的一字节复制到ES:DI,之后SI+=2、DI+=2 |
| movsd | 将DS:SI的一字节复制到ES:DI,之后SI+=4、DI+=4 |
于是上面的程序改写为
| cld mov cx, 128 rep movsd | ; 复位DF ; 512/4 = 128,共128个双字 ; 行动! |
第一句cld很多时候是多余的,因为实际写程序时,很少会出现置DF的情况。不过在正式决定删掉它之前,建议你仔细地调试自己的程序,并确认每一个能够走到这里的路径中都不会将DF置位。
错误(非预期的)的DF是危险的。它很可能断送掉你的程序,因为这直接造成缓冲区溢出问题。
什么是缓冲区溢出呢?缓冲区溢出分为两类,一类是写入缓冲区以外的内容,一类是读取缓冲区以外的内容。后一种往往更隐蔽,但随便哪一个都有可能断送掉你的程序。
缓冲区溢出对于一个网络服务来说很可能更加危险。怀有恶意的用户能够利用它执行自己希望的指令。服务通常拥有更高的特权,而这很可能会造成特权提升;即使不能提升攻击者拥有的特权,他也可以利用这种问题使服务崩溃,从而形成一次成功的DoS(拒绝服务)攻击。每年CERT的安全公告中,都有6成左右的问题是由于缓冲区溢出造成的。
在使用汇编语言,或C语言编写程序时,很容易在无意中引入缓冲区溢出。然而并不是所有的语言都会引入缓冲区溢出问题,Java和C#,由于没有指针,并且缓冲区采取动态分配的方式,有效地消除了造成缓冲区溢出的土壤。
汇编语言中,由于REP*前缀都用CX作为计数器,因此情况会好一些(当然,有时也会更糟糕,因为由于CX的限制,很可能使原本可能改变程序行为的缓冲区溢出的范围缩小,从而更为隐蔽)。避免缓冲区溢出的一个主要方法就是仔细检查,这包括两方面:设置合理的缓冲区大小,和根据大小编写程序。除此之外,非常重要的一点就是,在汇编语言这个级别写程序,你肯定希望去掉所有的无用指令,然而再去掉之前,一定要进行严格的测试;更进一步,如果能加上注释,并通过善用宏来做调试模式检查,往往能够达到更好的效果。
3.5 关于保护模式中内存操作的一点说明
正如3.2节提到到的那样,保护模式中,你可以使用32位的线性地址,这意味着直接访问4GB的内存。由于这个原因,选择器不用像实模式中段寄存器那样频繁地修改。顺便提一句,这份教程中所说的保护模式指的是386以上的保护模式,或者,Microsoft通常称为“增强模式”的那种。
在为选择器装入数值的时候一定要非常小心。错误的数值往往会导致无效页面错误(在Windows中经常出现:)。同时,也不要忘记你的地址是32位的,这也是保护模式的主要优势之一。
现在假设存在一个描述符描述从物理的0:0开始的全部内存,并已经加载进DS(数据选择器),则我们可以通过下面的程序来操作VGA的VRAM:
| mov edi,0a0000h mov byte ptr [edi],0fh | ; VGA显存的偏移量 ; 将第一字节改为0fh |
很明显,这比实模式下的程序
| mov ax,0a000h mov ds,ax mov di,0 mov [di],0fh | ; AX -> VGA段地址 ; 将AX值载入DS ; DI清零 ; 修改第一字节 |
看上去要舒服一些。
3.6 堆栈
到目前为止,您已经了解了基本的寄存器以及内存的操作知识。事实上,您现在已经可以写出很多的底层数据处理程序了。
下面我来说说堆栈。堆栈实在不是一个让人陌生的数据结构,它是一个先进后出(FILO)的线性表,能够帮助你完成很多很好的工作。
先进后出(FILO)是这样一个概念:最后放进表中
的数据在取出时最先出来。先进后出(FILO)和先
进先出(FIFO, 和先进后出的规则相反),以及随
机存取是最主要的三种存储器访问方式。
对于堆栈而言,最后放入的数据在取出时最先出
现。对于子程序调用,特别是递归调用来说,这
是一个非常有用的特性。
一个铁杆的汇编语言程序员有时会发现系统提供的寄存器不够。很显然,你可以使用普通的内存操作来完成这个工作,就像C/C++中所做的那样。
没错,没错,可是,如果数据段(数据选择器)以及偏移量发生变化怎么办?更进一步,如果希望保存某些在这种操作中可能受到影响的寄存器的时候怎么办?确实,你可以把他们也存到自己的那片内存中,自己实现堆栈。
太麻烦了……
既然系统提供了堆栈,并且性能比自己写一份更好,那么为什么不直接加以利用呢?
系统堆栈不仅仅是一段内存。由于CPU对它实施管理,因此你不需要考虑堆栈指针的修正问题。可以把寄存器内容,甚至一个立即数直接放到堆栈里,并在需要的时候将其取出。同时,系统并不要求取出的数据仍然回到原来的位置。
除了显式地操作堆栈(使用PUSH和POP指令)之外,很多指令也需要使用堆栈,如INT、CALL、LEAVE、RET、RETF、IRET等等。配对使用上述指令并不会造成什么问题,然而,如果你打算使用LEAVE、RET、RETF、IRET这样的指令实现跳转(比JMP更为麻烦,然而有时,例如在加密软件中,或者需要修改调用者状态时,这是必要的)的话,那么我的建议是,先搞清楚它们做的到底是什么,并且,精确地了解自己要做什么。
正如前面所说的,有两个显式地操作堆栈的指令:
| 助记符 | 功能 |
| PUSH | 将操作数存入堆栈,同时修正堆栈指针 |
| POP | 将栈顶内容取出并存到目的操作数中,同时修正堆栈指针 |
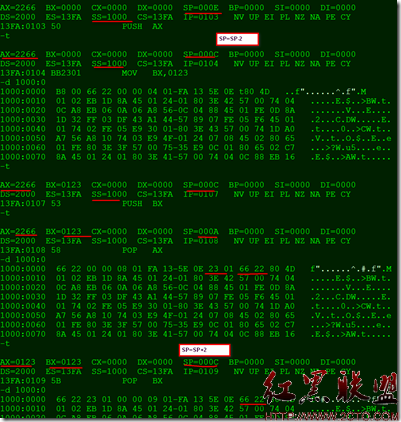
我们现在来看看堆栈的操作。
执行之前

执行代码
| mov ax,1234h mov bx,10 push ax push bx |
之后,堆栈的状态为

之后,再执行
| pop dx pop cx |
堆栈的状态成为

当然,dx、cx中的内容将分别是000ah和1234h。
注意,最后这张图中,我没有抹去1234h和000ah,因为POP指令并不从内存中抹去数值。不过尽管如此,我个人仍然非常反对继续使用这两个数(你可以通过修改SP来再次POP它们),然而这很容易导致错误。
一定要保证堆栈段有足够的空间来执行中断,以及其他一些隐式的堆栈操作。仅仅统计PUSH的数量并据此计算堆栈所需的大小很可能造成问题。
CALL指令将返回地址放到堆栈中。绝大多数C/C++编译器提供了“堆栈检查”这个编译选项,其作用在于保证C程序段中没有忘记对堆栈中多余的数据进行清理,从而保证返回地址有效。
本章小结
本章中介绍了内存的操作的一些入门知识。限于篇幅,我不打算展开细讲指令,如cmps*,lods*,stos*,等等。这些指令的用法和前面介绍的movs*基本一样,只是有不同的作用而已。