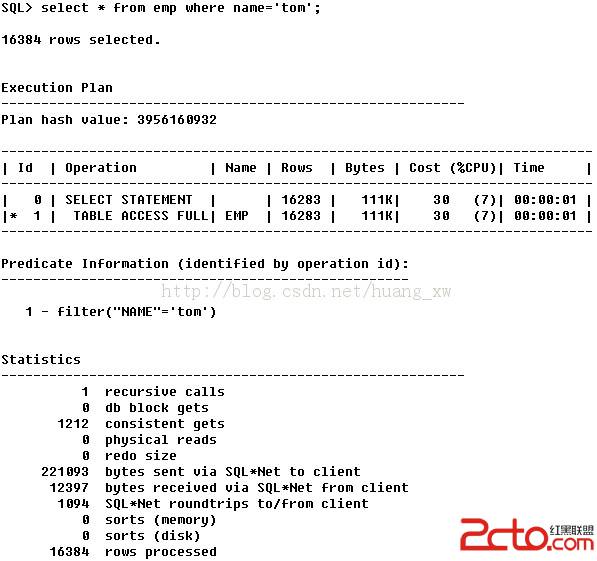
oracle sql select语句的使用方法
select格式:
SELECT [ ALL | DISTINCT ] <字段表达式1[,<字段表达式2[,…]
FROM <表名1>,<表名2>[,…]
[WHERE <筛选择条件表达式>]
[GROUP BY <分组表达式> [HAVING<分组条件表达式>]]
[ORDER BY <字段>[ASC | DESC]]
语句说明:
[]方括号为可选项
[GROUP BY <分组表达式> [HAVING<分组条件表达式>]]
指将结果按<分组表达式>的值进行分组,该值相等的记录为一组,带【HAVING】
短语则只有满足指定条件的组才会输出。
[ORDER BY <字段>[ASC | DESC]]
显示结果要按<字段>值升序或降序进行排序
练习:
1:表hkb_test_sore取出成绩sore前5名的记录,
2:取第5名的记录
1,答案select a.sore_id, a.sore
from (select * from hkb_test_sore order by sore desc) a
where rownum <=52,答案select a.sore_id, a.sore
from (select * from hkb_test_sore order by sore desc) a
where rownum <=5
minus
select a.sore_id, a.sore
from (select * from hkb_test_sore order by sore desc) a
where rownum <=4;
3:查询两个分数一样的记录
select *
from hkb_test_sore a
where a.sore = (select sore
from hkb_test_sore a
group by a.sore
having count(a.sore) = 2);union,union all,intersect,minus的区别:
SQL> select * from hkb_test2;
X Y
---- -----
a 1
b 2
c 3
g 4SQL> select * from hkb_test3;
X Y
---- -----
a 1
b 2
e 3
f 4
SQL> select * from hkb_test2;
X Y
---- -----
a 1
b 2
c 3
g 4
SQL> select * from hkb_test3;
X Y
---- -----
a 1
b 2
e 3
f 4
SQL> select * from hkb_test2
2 union
3 select * from hkb_test3;
X Y
---- -----
a 1
b 2
c 3
e 3
f 4
g 4
6 rows selected
SQL> select * from hkb_test2
2 union all
3 select * from hkb_test3;
X Y
---- -----
a 1
b 2
c 3
g 4
a 1
b 2
e 3
f 4
8 rows selectedSQL> select * from hkb_test2
2 intersect
3 select * from hkb_test3;
X Y
---- -----
a 1
b 2
SQL> select * from hkb_test2
2 minus
3 select * from hkb_test3;
X Y
---- -----
c 3
g 4
综合上面实例看个完整的实例
SQL>
SQL>
SQL> -- create demo table
SQL> create table Employee(
2 ID VARCHAR2(4 BYTE) NOT NULL primary key,
3 First_Name VARCHAR2(10 BYTE),
4 Last_Name VARCHAR2(10 BYTE),
5 Start_Date DATE,
6 End_Date DATE,
7 Salary Number(8,2),
8 City VARCHAR2(10 BYTE),
9 Description VARCHAR2(15 BYTE)
10 )
11 /Table created.
SQL>
SQL> -- prepare data
SQL> insert into Employee(ID, First_Name, Last_Name, Start_Date, End_Date, Salary, City, Description)
2 values ('01','Jason', 'Martin', to_date('19960725','YYYYMMDD'), to_date('20060725','YYYYMMDD'), 1234.56, 'Toronto', 'Programmer')
3 /1 row created.
SQL> insert into Employee(ID, First_Name, Last_Name, Start_Date, End_Date, Salary, City, Description)
2 values('02','Alison', 'Mathews', to_date('19760321','YYYYMMDD'), to_date('19860221','YYYYMMDD'), 6661.78, 'Vancouver','Tester')
3 /1 row created.
SQL> insert into Employee(ID, First_Name, Last_Name, Start_Date, End_Date, Salary, City, Description)
2 values('03','James', 'Smith', to_date('19781212','YYYYMMDD'), to_date('19900315','YYYYMMDD'), 6544.78, 'Vancouver','Tester')
3 /1 row created.
SQL> insert into Employee(ID, First_Name, Last_Name, Start_Date, End_Date, Salary, City, Description)
2 values('04','Celia', 'Rice', to_date('19821024','YYYYMMDD'), to_date('19990421','YYYYMMDD'), 2344.78, 'Vancouver','Manager')
3 /1 row created.
SQL> insert into Employee(ID, First_Name, Last_Name, Start_Date, End_Date, Salary, City, Description)
2 values('05','Robert', 'Black', to_date('19840115','YYYYMMDD'), to_date('19980808','YYYYMMDD'), 2334.78, 'Vancouver','Tester')
3 /1 row created.
SQL> insert into Employee(ID, First_Name, Last_Name, Start_Date, End_Date, Salary, City, Description)
2 values('06','Linda', 'Green', to_date('19870730','YYYYMMDD'), to_date('19960104','YYYYMMDD'), 4322.78,'New York', 'Tester')
3 /1 row created.
SQL> insert into Employee(ID, First_Name, Last_Name, Start_Date, End_Date, Salary, City, Description)
2 values('07','David', 'Larry', to_date('19901231','YYYYMMDD'), to_date('19980212','YYYYMMDD'), 7897.78,'New York', 'Manager')
3 /1 row created.
SQL> insert into Employee(ID, First_Name, Last_Name, Start_Date, End_Date, Salary, City, Description)
2 values('08','James', 'Cat', to_date('19960917','YYYYMMDD'), to_date('20020415','YYYYMMDD'), 1232.78,'Vancouver', 'Tester')
3 /1 row created.
SQL>
SQL>
SQL>
SQL> -- display data in the table
SQL> select * from Employee
2 /ID FIRST_NAME LAST_NAME START_DAT END_DATE SALARY CITY DESCRIPTION
---- -------------------- -------------------- --------- --------- ---------- ---------- ---------------
01 Jason Martin 25-JUL-96 25-JUL-06 1234.56 Toronto Programmer
02 Alison Mathews 21-MAR-76 21-FEB-86 6661.78 Vancouver Tester
03 James Smith 12-DEC-78 15-MAR-90 6544.78 Vancouver Tester
04 Celia Rice 24-OCT-82 21-APR-99 2344.78 Vancouver Manager
05 Robert Black 15-JAN-84 08-AUG-98 2334.78 Vancouver Tester
06 Linda Green 30-JUL-87 04-JAN-96 4322.78 New York Tester
07 David Larry 31-DEC-90 12-FEB-98 7897.78 New York Manager
08 James Cat 17-SEP-96 15-APR-02 1232.78 Vancouver Tester8 rows selected.
SQL>
SQL>
SQL> SELECT id, first_name, last_name FROM employee
2 /ID FIRST_NAME LAST_NAME
---- -------------------- --------------------
01 Jason Martin
02 Alison Mathews
03 James Smith
04 Celia Rice
05 Robert Black
06 Linda Green
07 David Larry
08 James Cat8 rows selected.
在ORACLE中实现SELECT TOP N的方法
1.在ORACLE中实现SELECT TOP N
由于ORACLE不支持SELECT TOP语句,所以在ORACLE中经常是用ORDER BY跟ROWNUM的组合来实现SELECT TOP N的查询。
简单地说,实现方法如下所示:
SELECT 列名1...列名n FROM
(SELECT 列名1...列名n FROM 表名 ORDER BY 列名1...列名n)
WHERE ROWNUM <= N(抽出记录数)
ORDER BY ROWNUM ASC
下面举个例子简单说明一下。
顾客表customer(id,name)有如下数据:
ID NAME
01 first
02 Second
03 third
04 forth
05 fifth
06 sixth
07 seventh
08 eighth
09 ninth
10 tenth
11 last
则按NAME的字母顺抽出前三个顾客的SQL语句如下所示:
SELECT * FROM
(SELECT * FROM CUSTOMER ORDER BY NAME)
WHERE ROWNUM <= 3
ORDER BY ROWNUM ASC
输出结果为:
ID NAME
08 eighth
05 fifth
01 first
2.在TOP N纪录中抽出第M(M <= N)条记录
在得到了TOP N的数据之后,为了抽出这N条记录中的第M条记录,我们可以考虑从ROWNUM着手。我们知道,ROWNUM是记录表中数据编号的一个隐藏子段,所以可以在得到TOP N条记录的时候同时抽出记录的ROWNUM,然后再从这N条记录中抽取记录编号为M的记录,即使我们希望得到的结果。
从上面的分析可以很容易得到下面的SQL语句。
SELECT 列名1...列名n FROM
(
SELECT ROWNUM RECNO, 列名1...列名nFROM
(SELECT 列名1...列名n FROM 表名 ORDER BY 列名1...列名n)
WHERE ROWNUM <= N(抽出记录数)
ORDER BY ROWNUM ASC
)
WHERE RECNO = M(M <= N)
同样以上表的数据为基础,那么得到以NAME的字母顺排序的第二个顾客的信息的SQL语句应该这样写:
SELECT ID, NAME FROM
(
SELECT ROWNUM RECNO, ID, NAME FROM
(SELECT * FROM CUSTOMER ORDER BY NAME)
WHERE ROWNUM <= 3
ORDER BY ROWNUM ASC )
WHERE RECNO = 2
结果则为:
ID NAME
05 fifth
3.抽出按某种方式排序的记录集中的第N条记录
在2的说明中,当M = N的时候,即为我们的标题讲的结果。实际上,2的做法在里面N>M的部分的数据是基本上不会用到的,我们仅仅是为了说明方便而采用。
如上所述,则SQL语句应为:
SELECT 列名1...列名n FROM
(
SELECT ROWNUM RECNO, 列名1...列名nFROM
(SELECT 列名1...列名n FROM 表名 ORDER BY 列名1...列名n)
WHERE ROWNUM <= N(抽出记录数)
ORDER BY ROWNUM ASC
)
WHERE RECNO = N
那么,2中的例子的SQL语句则为:
SELECT ID, NAME FROM
(
SELECT ROWNUM RECNO, ID, NAME FROM
(SELECT * FROM CUSTOMER ORDER BY NAME)
WHERE ROWNUM <= 2
ORDER BY ROWNUM ASC
)
WHERE RECNO = 2
结果为:
ID NAME
05 fifth
4.抽出按某种方式排序的记录集中的第M条记录开始的X条记录
3里所讲得仅仅是抽取一条记录的情况,当我们需要抽取多条记录的时候,此时在2中的N的取值应该是在N >= (M + X - 1)这个范围内,当让最经济的取值就是取等好的时候了的时候了。当然最后的抽取条件也不是RECNO = N了,应该是RECNO BETWEEN M AND (M + X - 1)了,所以随之而来的SQL语句则为:
SELECT 列名1...列名n FROM
(
SELECT ROWNUM RECNO, 列名1...列名nFROM
(
SELECT 列名1...列名n FROM 表名 ORDER BY 列名1...列名n)
WHERE ROWNUM <= N (N >= (M + X - 1))
ORDER BY ROWNUM ASC
)
WHERE RECNO BETWEEN M AND (M + X - 1)
同样以上面的数据为例,则抽取NAME的字母顺的第2条记录开始的3条记录的SQL语句为:
SELECT ID, NAME FROM
(
SELECT ROWNUM RECNO, ID, NAME FROM
(SELECT * FROM CUSTOMER ORDER BY NAME)
WHERE ROWNUM <= (2 + 3 - 1)
ORDER BY ROWNUM ASC
)
WHERE RECNO BETWEEN 2 AND (2 + 3 - 1)
注意:
sql各子句的执行顺序:
1. FROM
2. WHERE
3. GROUP BY
4. HAVING
5. SELECT
6. ORDER BY
补充:数据库,Oracle教程