当前位置:编程学习 > JSP >>
答案:重要提示:本文部分内容是斑竹从网上搜集整理而来,如果您认为该文档的内容侵犯了您的权益,请与整理者(excelarthur@yahoo.com.cn)联系,与dev2dev网站无关。
JDBC3.0的特性
1、JDBC3.0规范中数据库连接池框架
JDBC3.0规范中通过提供了一个支持数据库连接池的框架,这个框架仅仅规定了如何支持连接池的实现,而连接池的具体实现JDBC 3.0规范并没有做相关的规定。通过这个框架可以让不同角色的开发人员共同实现数据库连接池。通过JDBC3.0规范可以知道具体数据库连接池的实现可以分为JDBC Driver级和Application Server级。在JDBC Driver级的实现中任何相关的工作均由特定数据库厂商的JDBC Drvier的开发人员来具体实现,即JDBC Driver既需要提供对数据库连接池的支持同时也必须对数据库连接池进行具体实现。而在Application Server级中数据库连接池的实现易做图定数据库厂商的JDBC Driver开发人员和Application Server开发人员来共同实现数据库连接池的实现(但是现在大多数Application Server厂商实现的连接池的机制和规范中提到有差异),其易做图定数据库厂商的JDBC Driver提供数据库连接池的支持而特定的Application Server厂商提供数据库连接池的具体实现。
JDBC3.0规范规定了如下的类和接口来支持数据库连接池的实现。
javax.sql.ConnectionEvent javax.sql.ConnectionPoolDataSource javax.sql.PooledConnection javax.sql.ConnectionEventListener其中除javax.sql.ConnectionEvent是类,其它的均为接口。
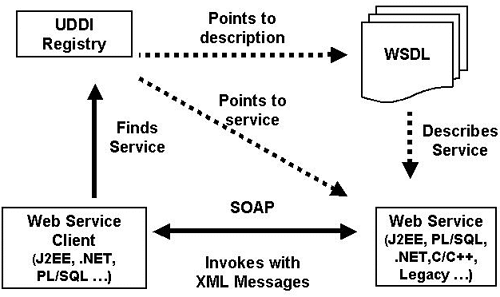
JDBC3.0连接池框架的关系图
通过此图可以大概的了解相关接口在一个典型的三层环境中应用程序的位置。
2、检索自动产生的关键字
为了解决对获取自动产生的或自动增加的关键字的值的需求,JDBC 3.0 API 现在将获取这种值变得很轻松。要确定任何所产生的关键字的值,只要简单地在语句的 execute() 方法中指定一个可选的标记,表示您有兴趣获取产生的值。您感兴趣的程度可以是 Statement.RETURN_GENERATED_KEYS,也可以是 Statement.NO_GENERATED_KEYS。在执行这条语句后,所产生的关键字的值就会通过从 Statement 的实例方法 getGeneratedKeys() 来检索 ResultSet 而获得,ResultSet 包含了每个所产生的关键字的列,下面的示例创建一个新的作者并返回对应的自动产生的关键字。…… Statement stmt = conn.createStatement(); // Obtain the generated key that results from the query. stmt.executeUpdate("INSERT INTO authors " + "(first_name, last_name) " + "VALUES (‘Ghq', ‘Wxl')", Statement.RETURN_GENERATED_KEYS); ResultSet rs = stmt.getGeneratedKeys(); if ( rs.next() ) { // Retrieve the auto generated key(s). int key = rs.getInt(); } ……3、返回多重结果
JDBC 2 规范的一个局限是,在任意时刻,返回多重结果的语句只能打开一个ResultSet。作为 JDBC 3.0 规范中改变的一个部分,规范将允许 Statement 接口支持多重打开的 ResultSets。然而,重要的是 execute() 方法仍然会关闭任何以前 execute() 调用中打开的 ResultSet。所以,要支持多重打开的结果,Statement 接口就要加上一个重载的 getMoreResults() 方法。新式的方易做图做一个整数标记,在 getResultSet() 方法被调用时指定前一次打开的 ResultSet 的行为。接口将按如下所示定义标记:CLOSE_ALL_RESULTS:当调用 getMoreResults() 时,所有以前打开的 ResultSet 对象都将被关闭。
CLOSE_CURRENT_RESULT:当调用 getMoreResults() 时,当前的 ResultSet 对象将被关闭。
KEEP_CURRENT_RESULT:当调用 getMoreResults() 时,当前的 ResultSet 对象将不会被关闭。
下面展示的是一个处理多重打开结果的示例。
…… String procCall; // Set the value of procCall to call a stored procedure. // … CallableStatement cstmt = connection.prepareCall(procCall); int retval = cstmt.execute(); if (retval == false) { // The statement returned an update count, so handle it. // … } else { // ResultSet ResultSet rs1 = cstmt.getResultSet(); // … retval = cstmt.getMoreResults(Statement.KEEP_CURRENT_RESULT); if (retval == true) { ResultSet rs2 = cstmt.getResultSet(); // Both ResultSets are open and ready for use. rs2.next(); rs1.next(); // … } } ……4、在事务中使用 Savepoint
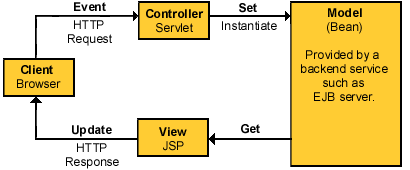
也许在 JDBC 3.0 中最令人兴奋的附加特点就是 Savepoint 了。JDBC 2 中的事务支持让开发人员可以控制对数据的并发访问,从而保证持续数据总是保持一致的状态。可惜的是,有时候需要的是对事务多一点的控制,而不是在当前的事务中简单地对每一个改变进行回滚。在JDBC 3.0 下,可以通过 Savepoint 获得这种控制。Savepoint 接口允许您将事务分割为各个逻辑断点,以控制有多少事务需要回滚。下图将说明如何在事务中运用 Savepoint。
Savepoint 的直观表示
你或许不是经常需要使用 Savepoint。然而,在一种普遍的情况下 Savepoint 会发挥作用,那就是您需要作一系列的改变,但是在知道所有的结果之前不能确定应该保留这些改变的哪一部分。下面的代码示例说明了如何使用 Savepoint 接口。...... conn.setAutoCommit(false); // Set a conservative transaction isolation level. conn.setTransactionIsolation(Connection.TRANSACTION_SERIALIZABLE); Statement stmt = conn.createStatement(); int rows = stmt.executeUpdate( "INSERT INTO authors " + " (first_name, last_name) VALUES " + " ('Ghq', 'Wxl')"); // Set a named savepoint. Savepoint svpt = conn.setSavepoint("NewAuthor"); // … rows = stmt.executeUpdate( "UPDATE authors set type = 'fiction' " + "WHERE last_name = 'Wxl'"); // … conn.rollback(svpt); // … // The author has been added, but not updated. conn.commit(); ......5、其他的特性
1)元数据 API
元数据 API 已经得到更新,DatabaseMetaData 接口现在可以检索 SQL 类型的层次结构,一种新的 ParameterMetaData 接口可以描述 PreparedStatement 对象中参数的类型和属性。2)CallableStatements 中已命名的参数
在 JDBC 3.0 之前,设置一个存储过程中的一个参数要指定它的索引值,而不是它的名称。 CallableStatement 接口已经被更新了,现在您可以用名称来指定参数。3)数据类型的改变
JDBC 所支持的数据类型作了几个改变,其中之一是增加了两种新的数据类型。为了便于修改 CLOB(Character Large OBject,字符型巨对象)、BLOB(Binary Large OBject,二进制巨对象)和 REF(SQL 结构)类型的值,同名的数据类型接口都被更新了。接下来的是,因为我们现在能够更新这些数据类型的值,所以 ResultSet 接口也被修改了,以支持对这些数据类型的列的更新,也包括对 ARRAY 类型的更新。增加的两种新的数据类型是 java.sql.Types.DATALINK 和 java.sql.Types.BOOLEAN。新增的数据类型指的是同名的 SQL 类型。DATALINK 提供对外部资源的访问或 URL,而 BOOLEAN 类型在逻辑上和 BIT 类型是等同的,只是增加了在语义上的含义。DATALINK 列值是通过使用新的 getURL() 方法从 ResultSet 的一个实例中检索到的,而 BOOLEAN 类型是通过使用 getBoolean() 来检索的。
二进制大对象Blob
Blob对象是SQL Blob的Java语言映射。SQL Blob是一个内置类型,它可以将一个二进制大对象保存在数据库中。接口ResultSet、CallableStatement和PreparedStatement中的方法允许程序员使用与访问SQL 92内置类型同样的方式来访问SQL 99类型BLOB。在标准实现中,JDBC驱动程序在后台使用SQL类型LOCATOR(BLOB)来实现Blob接口。LOCATOR(BLOB)指向保存在数据库服务器上的SQL BLOB值,而且这些操作作用在这个LOCATOR(定位器)上与作用在BLOB值本身有同样的结果。这意味着用户可以在一个Blob实例上执行操作而不必将这个BLOB数据物化到用户上,这将显著的提高性能。因为驱动程序在后台使用LOCATOR(BLOB),所以它的使用对程序员是完全透明的。
Blob实例的标准行为一直保持有效,直到这个事务(创建一个Blob的事务)执行了提交或者回滚操作。
- 创建Blob对象
下面的代码说明了如何创建一个Blob对象,其中stmt是一个Statement对象:Statement stmt = con..createStatement(ResultSet.TYPE_INSENSITIVE, ResultSet.CONCUR_READ_ONLY); ResultSet rs = stmt.excuteQuery(“SELECT DATA FROM TABLE 1”); If (rs.next()){ rs.first(); Blob blob=rs.getBlob(“DATA”); } 变量blob包含一个指向BLOB值的逻辑指针,该BLOB值保存在结果集rs的第一行的DATA列中。即使变量blob实际上并不包含BLOB值中的数值,应用程序在blob上执行操作仍然像在实际的数据上执行一样。即应用程序在blob上所作的任何操作都会对表中的BLOB值起作用。- 物化BLOB数据
开发人员可以在Blob对象上调用JDBC API中的方法,就像这些方法直接
在该对象所指向的SQL





- 更多JSP疑问解答:
- jsp新手求指导,不要笑!
- 如何让一个form提取的值传递给多个jsp?
- DW中,新建的html页面能否有jsp或php代码?
- jsp 如何限制表单,实现只能填写特定的数据。
- jsp 和javabean结合的程序有问题
- 从数据库里取出的数据如何传递到另外的jsp页面中
- 你好,ext嵌入那个jsp页面,是不是还需要加上一些插件啊,不太懂,麻烦你了。
- JSP不能处理所有问题吗?还要来一大堆的TLD,TAG,XML。为JSP 非要 Servlet 不可吗?
- 光标离开时全角转半角在jsp中怎么实现
- jsp 页面 打开 pdf 文件 控制大小 和 工具栏 能发份源码么 谢啦
- jsp页面点保存按钮,运行缓慢,弹出对话框提示
- jsp刷新页面如何不闪屏
- jsp 与html 的交互问题?
- jsp小数显示问题 例如 我在oracle 数据库中查询出来的是 0.01 但是在jsp页面上就显示成 .01 没有前面的0
- jsp中日历控件