如何在Linux操作系统线程库中进行性能测试与分析
NPTL 成为 glibc "正选" 线程库后,它的性能如何受到很多人的关注。本文就针对 NPTL 与 LinuxThreads 的性能比较,以及超线程、内核可抢占等特性对线程性能的影响进行了全面评测。
一、 前言
在 Linux 2.6.x 内核中,调度性能的改进是其中最引人注目的一部分 [1]。NPTL(Native Posix Thread Library)[2] 使用内核的新特性重写了 Linux 的线程库,取代历史悠久而备受争议的 LinuxThreads [3] 成为 glibc 的首选线程库。
NPTL 的性能究竟如何?相对 LinuxThreads 又有哪些明显的改进?在对 NPTL 进行全面分析之前,本文针对这两种线程库,以及内核中 "内核可抢占"(Preemptible)和超线程(HyperThreading)[4] 等特性进行了全面的性能评测,结果表明 NPTL 绝对值得广大服务器系统期待和使用。
二、 Benchmark
1. 测试平台
进行本测试的硬件平台为浪潮 NF420R 服务器 [7],4 个 Hyperthreading-enabled Intel Xeon 2.2G 处理器,4G 内存。Linux 选择了 Slackware 9.0 发行版 [8],所使用的内核源码来自www.kernel.org。
2. 针对测试:LMBench
lmbench 是一个用于评价系统综合性能的多平台开源 benchmark [5],但其中没有对线程的支持。其中有两个测试进程性能的 benchmark:lat_proc 用于评测进程创建和终止的性能,lat_ctx 用于评测进程切换的开销。lmbench 拥有良好的 benchmark 结构,只需要修改具体的 Target 程序(如 lat_proc.c 和 lat_ctx.c),就可以借用 lmbench 的计时、统计系统得到我们关心的线程库性能的数据。
基于 lat_proc和lat_ctx 的算法,本文实现了 lat_thread和lat_thread_ctx 两个 benchmark。在 lat_thread 中,lat_proc 被改造成使用线程,用 pthread_create() 替代了 fork(),用 pthread_join() 替代 wait();在 lat_thread_ctx 中,沿用 lat_ctx 的评测算法(见 lat_ctx 手册页),将创建进程的过程改写为创建线程,仍然使用管道进行通信和同步。
lat_thread null
null 参数表示线程不进行任何实际操作,创建后即刻返回。
lat_thread_ctx -s #threads
size 参数与 lat_ctx 定义相同,可表示线程的大小(实际编程时为分配 K 数据;#threads 参数为线程数,即参与令牌传递的线程总数,相当于程序负载情况。
3. 综合测试:Volanomark
volanomark是一个纯java的benchmark,专门用于测试系统调度器和线程环境的综合性能[6],它建立一个模拟Client/Server方式的Java聊天室,通过获取每秒平均发送的消息数来评测宿主机综合性能(数值越大性能越好)。Volanomark测试与Java虚拟机平台相关,本文使用Sun Java SDK 1.4.2作为测试用Java平台,Volanomark版本2.5.0.9。
三、 测试结果
测试计划中将内核分为 2.4.26、2.6.6/ 支持内核抢占和 2.6.6/ 不支持内核抢占三类;通过配置内核以及 NF420R 的 BIOS 实现三类 SMP 规模:单处理机 (UP)、4CPU 的 SMP(SMP4)和打开超线程支持的虚拟 8CPU SMP(SMP8*)。内核配置和 SMP 规模的每一种组合都针对 LinuxThreads 和 NPTL 使用 lat_thread、lat_thread_ctx 和 volanomark 获取一组数据。由于 NPTL 无法在 2.4.x 内核上使用,该项数据空缺。
四、 结果分析
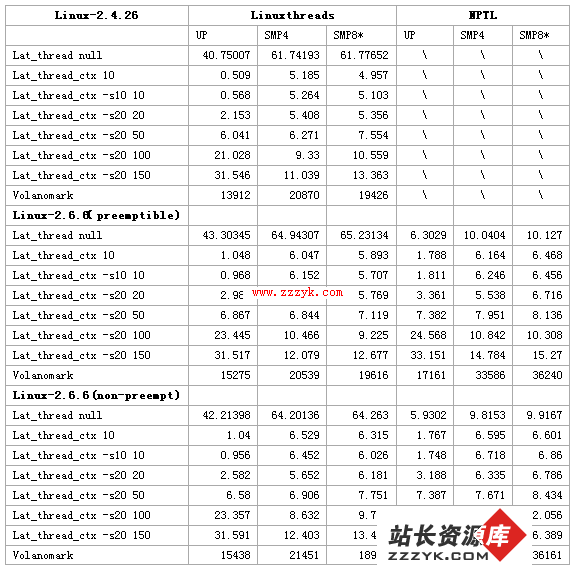
1. LinuxThreads vs NPTL:线程创建/销毁开销
使用 2.6.6/preemptible 内核配置下 UP 和 SMP4 的测试数据获得下图:
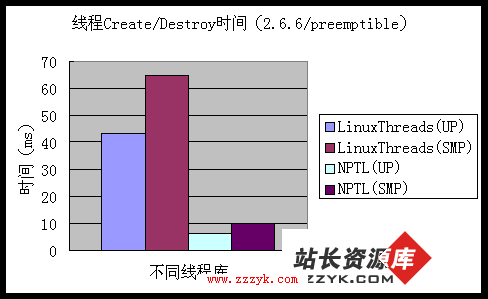
图 1
在线程创建/销毁开销方面,NPTL 的改进相当明显(降低约 600%)。实际上,NPTL 不再像 LinuxThreads 那样需要使用用户级的管理线程来维护线程的创建和销毁 [9],因此,很容易理解它在这方面的开销能够大幅度降低。
同时,由图可见,单 CPU 下创建线程总是比多 CPU 下迅速。
2. LinuxThreads vs NPTL:线程切换开销
同样使用 2.6.6/preemptible 内核配置下 UP 和 SMP4 的数据:
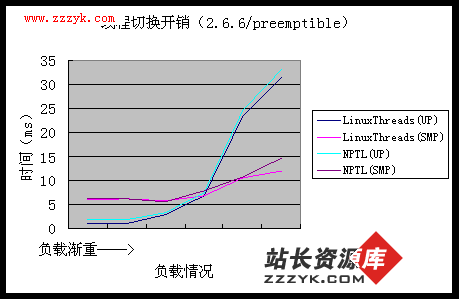
图 2
随着 lat_thread_ctx 的参与线程增多,不管是哪个线程库,单处理机条件下的线程切换开销都陡峭上升,而 SMP 条件下则上升比较平缓。在这方面,LinuxThreads 和 NPTL 表现基本相同。
3. 内核影响
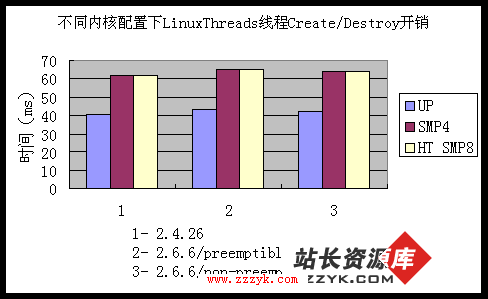
图 3

图 4
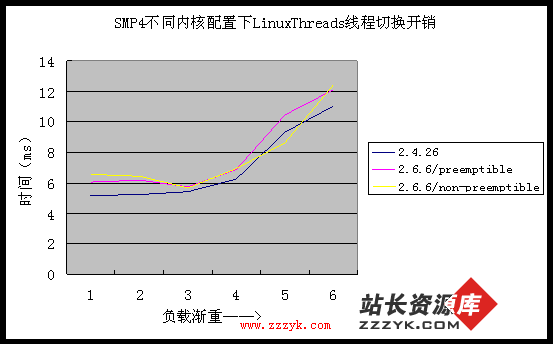
图 5
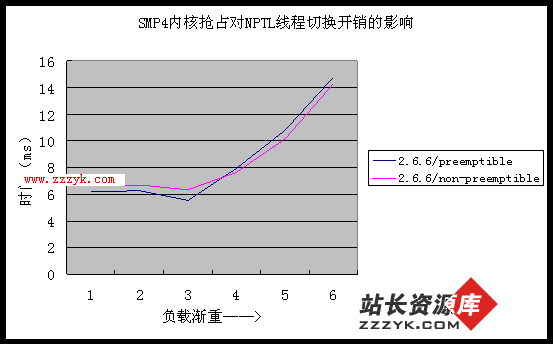
图 6
从上面四张图中我们可以得出两点结论:
1、"内核可抢占" 是 Linux 对实时应用提供更好支持的有力保障,但对线程性能影响很小,甚至有一点损失,毕竟抢占锁的开销不可忽略;
2、升级内核并不会对 LinuxThreads 线程库性能带来多少变化,因此,对于服务器系统而言,不能指望仅仅编译使用新内核就能提高性能。
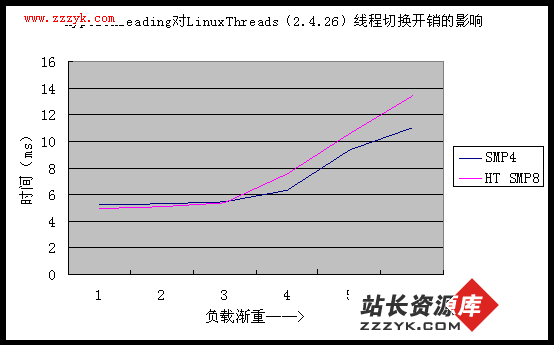
图 7
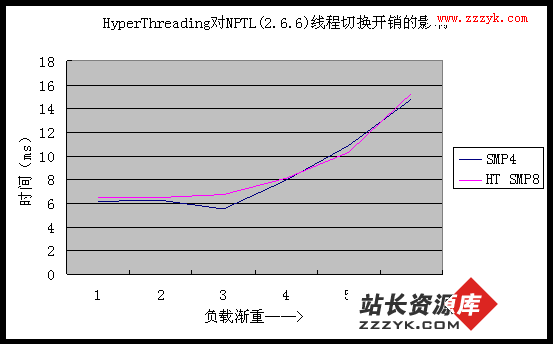
图 8
从图 3、图 4 我们已经知道,打开超线程支持对线程创建/销毁性能几乎没有影响,而这两张图表也进一步说明,超线程技术对于线程切换开销也没有明显的影响。超线程技术是 CPU 内部的优化技术,和真正的双 CPU 完全不同。大量研究表明,如果没有内核与用户应用相结合的专门优化措施,超线程并不会带来很大的性能变化。除非是高负载综合服务器系统(例如繁忙的数据库系统),购买超线支持的 CPU 并不能带来多少好处。
4. 综合性能
从图 3、图 4 我们已经知道,打开超线程支持对线程创建/销毁性能几乎没有影响,而这两张图表也进一步说明,超线程技术对于线程切换开销也没有明显的影响。超线程技术是 CPU 内部的优化技术,和真正的双 CPU 完全不同。大量研究表明,如果没有内核与用户应用相结合的专门优化措施,超线程并不会带来很大的性能变化。除非是高负载综合服务器系统(例如繁忙的数据库系统),购买超线支持的 CPU 并不能带来多少好处。 4. 综合性能
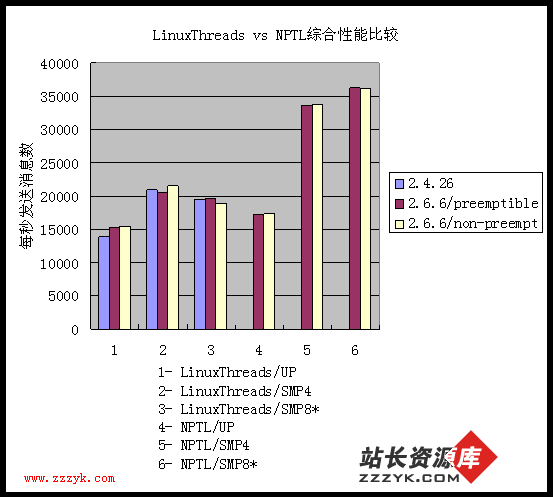 |
图 9
前面几节分析让我们了解了线程库性能改进的细节,通过 volanomark 测试,我们可以近似得到在综合应用环境下,特别是网络服务需求中线程库以及内核对系统整体性能的影响程度。
图 9 综合了不同内核、不同处理机数条件下,两种线程库的 volanomark 结果。从图中可以观察到以下三点:
- NPTL 能极大提高 SMP 环境下服务器系统的整体性能(超过 65%),相对而言,对单处理机系统影响较小(10% 左右);
- 2.6 内核的抢占特性对系统性能影响很小(不超过 ±1%),某些情况下甚至有所下降;
- 超线程技术在 LinuxThreads 中的影响是负面的,在 NPTL 中是正面的,但影响幅度都很小(5% - 6%)。
以上结论中前两点与 LMBench 针对性测试结果完全吻合,第三点的偏差实际上反映了超线程技术对于综合服务器环境还是有一定加速的。
五、 总结
我们的评测为广大 Linux 用户,特别是服务器用户提供了一点有价值的参考:
- 如果你的是多处理机系统,那么毫不犹豫地升级你的内核,并记住,一定要同时升级你的线程库,它通常与 glibc 紧密耦合;
- 如果你的系统并没有实时应用,不要打开 "内核可抢占" 开关,它只会让你的系统更慢;
- 慎重考虑是否使用超线程技术,即使你已经购买了支持超线程的 CPU,有时关闭它可能更适合你的需求。
www.zzzyk.com 电脑知识网 打造全国最大的电脑知识学习基地