PL/SQL批处理语句:BULK COLLECT和FORALL对优化的贡献
我们知道PL/SQL程序中运行SQL语句是存在开销的,因为SQL语句是要提交给SQL引擎处理
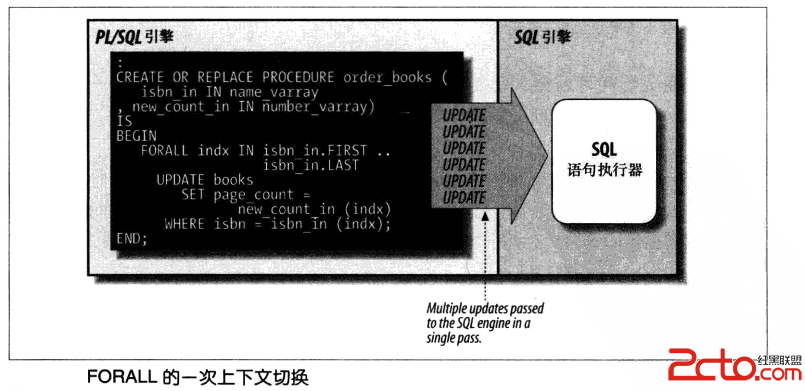
这种在PL/SQL引擎和SQL引擎之间的控制转移叫做上下文却换,每次却换时,都有额外的开销
请看下图:
但是,FORALL和BULK COLLECT可以让PL/SQL引擎把多个上下文却换压缩成一个,这使得在PL/SQL中的要处理多行记录的SQL语句执行的花费时间骤降
请再看下图:
下面详解这爷俩
㈠ 通过BULK COLLECT 加速查询
⑴ BULK COLLECT 的用法
采用BULK COLLECT可以将查询结果一次性地加载到collections中,而不是通过cursor一条一条地处理
可以在select into ,fetch into , returning into语句使用BULK COLLECT
注意在使用BULK COLLECT时,所有的INTO变量都必须是collections
举几个简单例子:
① 在select into语句中使用bulk collect
[sql]
DECLARE
TYPE sallist IS TABLE OF employees.salary%TYPE;
sals sallist;
BEGIN
SELECT salary BULK COLLECT INTO sals FROM employees where rownum<=50;
--接下来使用集合中的数据
END;
/
② 在fetch into中使用bulk collect
[sql]
DECLARE
TYPE deptrectab IS TABLE OF departments%ROWTYPE;
dept_recs deptrectab;
CURSOR cur IS SELECT department_id,department_name FROM departments where department_id>10;
BEGIN
OPEN cur;
FETCH cur BULK COLLECT INTO dept_recs;
--接下来使用集合中的数据
END;
/
③ 在returning into中使用bulk collect
[sql]
CREATE TABLE emp AS SELECT * FROM employees;
DECLARE
TYPE numlist IS TABLE OF employees.employee_id%TYPE;
enums numlist;
TYPE namelist IS TABLE OF employees.last_name%TYPE;
names namelist;
BEGIN
DELETE emp WHERE department_id=30
RETURNING employee_id,last_name BULK COLLECT INTO enums,names;
DBMS_OUTPUT.PUT_LINE('deleted'||SQL%ROWCOUNT||'rows:');
FOR i IN enums.FIRST .. enums.LAST
LOOP
DBMS_OUTPUT.PUT_LINE('employee#'||enums(i)||':'||names(i));
END LOOP;
END;
/
deleted6rows:
employee#114:Raphaely
employee#115:Khoo
employee#116:Baida
employee#117:Tobias
employee#118:Himuro
employee#119:Colmenares
⑵ BULK COLLECT 对大数据DELETE UPDATE的优化
这里举DELETE就可以了,UPDATE同理
举个案例:
需要在一个1亿行的大表中,删除1千万行数据
需求是在对数据库其他应用影响最小的情况下,以最快的速度完成
如果业务无法停止的话,可以参考下列思路:
根据ROWID分片、再利用Rowid排序、批量处理、回表删除
在业务无法停止的时候,选择这种方式,的确是最好的
一般可以控制在每一万行以内提交一次,不会对回滚段造成太大压力
我在做大DML时,通常选择一两千行一提交
选择业务低峰时做,对应用也不至于有太大影响
代码如下:
[sql]
DECLARE
--按rowid排序的cursor
--删除条件是oo=xx,这个需根据实际情况来定
CURSOR mycursor IS SELECT rowid FROM t WHERE OO=XX ORDER BY rowid;
TYPE rowid_table_type IS TABLE OF rowid index by pls_integer;
v_rowid rowid_table_type;
BEGIN
OPEN mycursor;
LOOP
FETCH mycursor BULK COLLECT INTO v_rowid LIMIT 5000;--5000行提交一次
EXIT WHEN v_rowid.count=0;
FORALL i IN v_rowid.FIRST..v_rowid.LAST
DELETE t WHERE rowid=v_rowid(i);
COMMIT;
END LOOP;
CLOSE mycursor;
END;
/
⑶ 限制BULK COLLECT 提取的记录数
语法:
FETCH cursor BULK COLLECT INTO ...[LIMIT rows];
其中,rows可以是常量,变量或者求值的结果是整数的表达式
假设你需要查询并处理1W行数据,你可以用BULK COLLECT一次取出所有行,然后填充到一个非常大的集合中
可是,这种方易做图消耗该会话的大量PGA,APP可能会因为PGA换页而导致性能下降
这时,LIMIT子句就非常有用,它可以帮助我们控制程序用多大内存来处理数据
例子:
[sql]
DECLARE
CURSOR allrows_cur IS SELECT * FROM employees;
TYPE employee_aat IS TABLE OF allrows_cur%ROWTYPE INDEX BY BINARY_INTEGER;
v_emp employee_aat;
BEGIN
OPEN allrows_cur;
LOOP
FETCH allrows