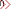当前位置:操作系统 > 电脑通通透 >>
[page_break] CORE构架的取指令能力也是16字节的,所以它最大也只能满足一周期4条平均4字节的指令。为了解决这个弱点,INTEL设计了特殊的双内置64字节缓冲器来连接发出一条64字节指令,并在一周期内完成连续的32字节指令。
改进的分支预测单元和运算法则
K8构架的分支预测单元比Conroe的分支预测单元更加简洁高效,但是K8简洁的分支预测单元也同样有着弱点,例如省略了的间接分支预测功能将会影响到其多面体指令的性能,其预测准确率也将低于对手,这也是同频率K8在3D图形性能运用中远不敌Conroe的原因之一。所以在K8L构架中,AMD针对这一重点问题将做一系列大的改进,包括添加更为全面的预测指令和改进预测运算法则等。
四、K8L的整数性能
改进的乱序执行方式
编译好的宏指令Macro-Ops以三条为一组发送到指令控制器ICU,指令控制器把宏指令的信息存入重排序缓冲区ROB,然后转移到调度程序Scheduler等待调出。重排序缓冲区会自动保存宏指令的信息并且控制他们的退出顺序, 宏指令依然以三条一组的方式退出,由调度程序分派到不同执行单元进行下一步编译。调度程序分派出的宏指令在三条整数列队中排序为8条一组、共24条,同时它们的出入顺序也由编码器记录。每24条宏指令排满后,调度程序就立即向算数逻辑单元ALU发出整数运算指令,同时也向地址产成单元AGU发出寻址指令。这样,每一时钟周期就可以同时完成3条宏指令和2条寻址指令。例如:
· add ebx,ecx;
· mov eax,[ebx+10h];快速寻址计算
· mov ecx,[eax+ebx];地址依赖于前一个指令操作
· mov edx,[ebx+24h];这个指令在前面所有指令的地址计算完成之前是不会被执行的
三个一排的宏指令组会在执行后从ROB中移出,宏指令的排序和移出使得调度单元动态的控制着整体资源,提高处理器工作效率。不过当三个宏指令序列中有一个出现满载情况,那么新的宏指令序列就不能进入调度单元。但是在实际操作中出现这样的情况并不是太多,即使偶尔发生这种情况也并不会对处理器的执行效率有太大的影响。除此之外,组中宏指令组到调度单元序列的静态链接也有可能会降低调度单元的工作效率,因为一个序列可能含有2个或更多的宏指令等待执行,另一个序列则可能一个等待的宏指令也没有。这种情况在实际执行中并不常见,通常在管线中都会有足够多的等待执行指令。
在“AMD与奔腾4的终结!Intel世袭构架涅磐”一文中,我们提到过:“在过去的几年里,大多数CPU都远离了乱序执行方式(OOOE)的内核设计思路,而偏向了有序执行方式(IOE),大量的VLIW处理器的性能都严重受限于程序与编码器,而现在Core的出现则代表了INTEL当前OOOE方式的最高设计水平,INTEL宣称Core将比现有的IOE处理器更好更合理的迅速处理完数据。”现在令DIYER满意的是,AMD也将采用其最新的OOOE技术,运用到AMD赋予厚望、对抗强敌CORE构架的K8L构架之中,这将使K8L构架与CORE构架在寻址速度、数据介入上达到同一水准。同样的,乱序执行OOOE是必须有序输出BIO的,AMD的工程师们使用了同样成熟的Memory Disambiguation技术,可以也让K8L构架中存数和取数指令同时进行乱序执行而不用等待前排取数/存数指令的完成。这一优化也使K8L构架节约了一倍的亢余周期,使其存储器数据处理/传输环节速度显著加快。K8L构架和CORE构架的乱序执行机制存在着一些技术上的差异,不过都为每时钟周期5条宏指令的派遣速度(3 ALU+2 MEM)。
改进的整数处理单元
数据块中的X86指令被编码为宏指令,每个宏指令分解为两个微指令:一个整数或浮点运算指令和一个内存寻址操作。K8构架处理器区分有三种不同的指令:
[page_break] · 单直接路径指令被硬件解码器的编译成一个宏指令
· 双直接路径指令被硬件解码器编译成两个宏指令
· 矢量路径指令被芯片整合的微代码引擎ROM解码成3条或更多的宏指令
K8构架不能够同时派遣出直接路径指令和矢量路径指令。解码器每周期最大只能完成3条宏指令,所以硬件解码器能完成三条单直接路径指令、一条单直接路径指令和一条双直接路径指令、或者一条半的双直接路径指令(分为两个周期完成的三条双直接路径指令),而矢量路径指令则需要更多的时间。
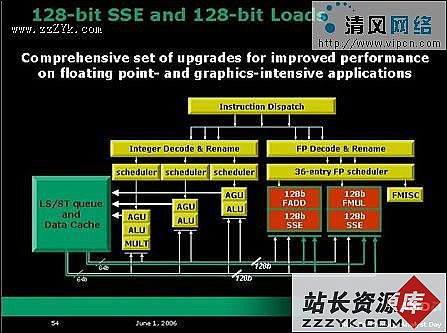
宏指令在硬件解码器中编译然后被统一成组发出,一组可能包含2个甚至1个宏指令以分隔直接路径和矢量路径,或者是区分不同组的指令。SSE、SSE2、SSE3中的矢量路径指令被K8构架处理器分为多条宏指令,然后由其64位执行单元分为两部分来处理这些128位的数据。这就是K8构架处理器把矢量路径指令解码成3条或更多条宏指令的原因。在K8L构架中,SSE执行单元将加宽到128位,这样就可以在一周期内完成部分的完整SSE指令,这意味着优化SSE指令后K8L构架处理器的处理速度至少比同频率K8构架处理器提高20%以上。
虽然K8L构架依然无法在一周期内完成4-5条指令而CORE构架可以,但是这并不会负面影响到K8L构架处理器的性能,因为一般而言,绝大部分周期指令都是不多于三条的,而且K8L构架由SSE指令分解出的宏指令数量要远低于Conroe。
与K8构架不同,CORE构架的3个整数执行单元中有2个为SIU简单整数单元快速执行单元,另一个为CIU复杂整数单元,同时宏指令的列队容量为32条,这使得CORE构架的整数执行效率要比K8构架稍高。但在K8L构架中AMD则设计为3个SIU简单整数单元和1个CIU复杂整数单元,总的来看,K8L构架处理器和CORE构架处理器的整数性能是处于同一水平的,严格的来看,K8L构架稍微领先于CORE构架,毕竟K8L构架要晚于对手半年多才定案。
五、K8L构架的浮点运算性能 - 两倍于K8构架
在当前的K8构架中,64位的FPU单元使得所有的128位浮点宏指令是必须被分为两条64位宏指令来进行传输和编译的,这样多出的分解过程、两倍数量的宏指令传输过程、载入、再组合等过程严重影响了K8构架的浮点性能。这已经从众多测试软件中明显的显现出来。
得益于2006年工艺的大幅度提升,AMD在K8L构架的浮点运算器方面有了进行翻倍性能加强的能力:FADD、FMUL及SSE等浮点运算器将由64位扩展到128位。同时,K8L构架的两条浮点数据传输带宽也加宽到128位,这使得处理器可以与L1缓存进行128位的高速传输。相比只拥有一条浮点数据传输带的CORE构架,K8L将有一定的优势。同时,K8L构架在浮点FADD和FMUL中也将拥有128位的ADD/MUL块处理能力来面对SSE2数据。在K8构架中FSTORE单元所存在的传输及运算法则缺陷等问题也将在K8L中得到改进。
另外,相对于K8构架的1个双精度浮点FADD和1个双精度浮点FMUL,K8L构架翻倍的增强了其浮点计算峰值的性能,并引入了新的指令集FMAC等和改进了算法法则。K8L构架相比过去K8构架的1个双精度浮点运算/时钟的能力,提高到2个双精度浮点/时钟。除去引入的新指令集的优势,K8L构架也已经把K8构架的1个双精度浮点FADD及FMUL/时钟,提高到K8L构架的2个双精度浮点FADD及FMUL/时钟。K8L构架在基于SSE/SSE2/SSE3的浮点运算运用中也会有一定程度的提高--实现了单周期执行同一并行SSE2指令的能力,这点和CORE构架是一样的,而K8构架则需要2周期。(不过在SSE浮点任务上K8L构架依然会落后于同频CORE构架处理器。)
FPU性能翻倍的同时,过去在K8构架中的两条FPU宏指令将在K8L构架中将能够融合为一条宏指令来同时分派和编译,增强了数据处理的合理性和便利性。所以128位的浮点运算单元将至少使K8L构架处理器在FPU、向量SSE数据的分派、传输、解码速度三方面同时达到现有K8构架处理器的两倍速度。
[page_break] 总的来看,K8L构架的浮点运算能力将至少比K8构架快一倍,甚至比当前最强大的CORE构架处理器还要快10%,尤其在处理没有SSE优化的X87数据上,K8L将比CORE构架快50%以上。
六、全新构架07年夏季登场
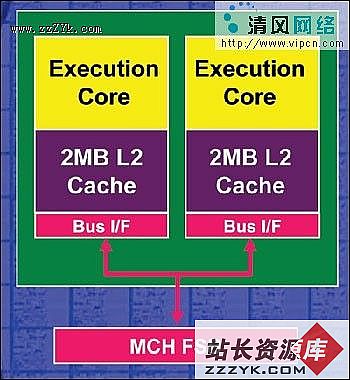
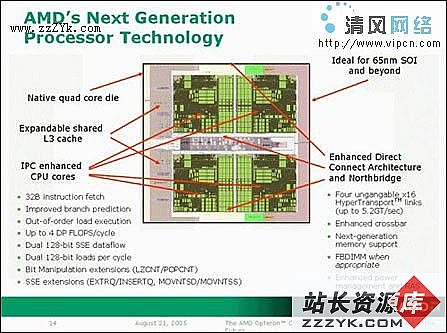
AMD日前进一步公布了K8L构架处理器的发售时间计划,其中最先于2007年夏季销售的四核心K8L构架处理器代号为Barcelona(巴塞罗那),支持Hyper-Transport 2.0,步进为Rev H核心,功耗将从68W至120W不等,其主流型号TDP将为95W。此功耗控制对于四核心、2M L3缓存的强大K8L处理器而言是比较令人满意的,四核心和L3缓存的引入并没有使K8L构架处理器出现预先担忧的150W左右的巨大功耗,这与INTEL因功耗控制问题而屡屡遇挫的Netburst构架形成了鲜明的对比。
代号Budapest(布达佩斯)的完善版K8L核心则于2007年秋末上市,支持更新的Hyper-Transport 3.0、更大的L3缓存容量,其型号将为Opteron 12XX系列以及ATHLON64全系列。
2008年春季,代号为Shanghai(上海)的最强服务器版四核心处理器 - Opteron22XX以及82XX系列届时将成为AMD最强的处理器,AMD将引入更多新的电路技术来控制其功耗等问题。
K8L构架相对于K8构架的进步是巨大的,K8L构架中多种最新技术的引入使得DIY用户们有信心在明年就可以更换为目前遥不可及的四核处理器。同时AMD和INTEL的争夺也将更为激烈,而广大DIY用户们则在欣赏激斗的同时可以轻松获得物美价廉的强大处理器--无论是CORE构架或者K8L构架。
答案:
INTEL的Core 2 Duo处理器目前在市场大受好评,而AMD一直没能推出与其相匹敌的新构架CPU。不过这种情况将有所改善:AMD日前承诺将于明年夏季大规模发售其极有自信的“Conroe杀手”-- 全面改进的四核K8L构架处理器(名称未定),AMD此次将近年的多项革新技术融入到目前市场主流的K8构架,其构架的各个细节设计和技术均有了极大的进步,K8L也将是K8构架的最终演化形态。AMD自信的称其为Conroe杀手的同时,或许预示着明年又将有一场精彩的CPU大战上演。此文简要的解析了K8L构架,并将之与经典的K8构架和目前最强的CORE构架进行一些简单的对比。 2006年7月27日,INTEL正式发布了强大的Core 2 Duo处理器,基于两颗Conroe核心和CORE构架的全新Core 2 Duo,其性能远超过当前主流“奔腾D”性能的2倍以上,同时也在下一代CPU的竞争上将对手AMD远远的甩在了后方。而AMD似乎太沉浸于近年来K8构架在市场上的巨大成功之中 -- 在Core构架面世的近半年多时间后却依然一直没能公布与之相对抗的新型构架CPU,而K8构架却已经明显不能够完成与CORE构架处理器争夺市场的重任。不过日前AMD终于透露,将于明年夏季全面发售全新的K8L构架处理器(名称未定)--在CORE构架发布的一年之后。(在3月我们曾报道过AMD准备发布K8L构架处理器,后因技术改进而推迟。)超越K8构架一个时代的K8L构架其原始设计即是四核心,它的四颗独立核心将在同一块晶圆上以最新的65nm工艺制造。除了采用当前最先进的65nm工艺以外,K8L还将引入IBM专利的Embedded Silcon Germanium技术和Stress Memorization技术这两项最新的尖端电路技术,这将可以十分有效的减少K8L构架处理器的电子迁移现象及漏电率等负面影响。另外,AMD还可能使用更先进的PD-SOI技术或者FD-SOI(Fully-Depleted)技术从而更进一步的降低K8L构架处理器的功耗。综合多方技术,K8L构架将比上代90nm的K8构架降低30%的功耗。当前K8构架处理器的功耗和发热问题已经使用户十分满意了,而进一步降低功耗和发热的K8L构架处理器则将使全世界用户进入一个超低CPU功耗/发热的时代,同时这也意味着K8L构架处理器将拥有十分强大的超频潜力。
一、K8L构架的内存系统性能 - 两倍于K8构架
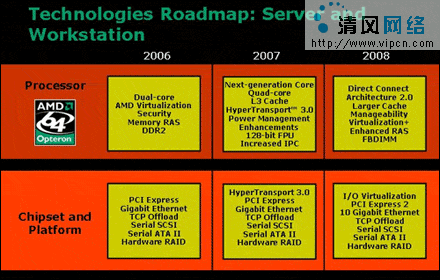
L1、L2缓存提速一倍
K8构架中采取的L1缓存方案是1个64K指示缓存+1个64K数据缓存来组成,各拥有并发2路/周期的传输能力。在K8L中,AMD将其L1缓存的传输能力提升为并发4路/周期,L1缓存与内核间将拥有2条双向128位的数据通道。改进的缓存模块拥有极低的延迟和高达95%以上的命中率。超过K8构架L1缓存一倍的高速传输能力使得K8L构架的L1缓存容量减为1个32K指示缓存+1个32K数据缓存,从而增加其命中率/周转率--其储存的全部是当前处理器最关键的核心数据。K8L构架处理器相对于K8构架处理器的L1缓存系统性能将有80%以上的增长,同时AMD也在考虑将L1缓存依然保持为1个64K指示缓存+1个64K数据缓存,这将取决于AMD缓存技术的发展情况。K8L构架中512K的L2缓存是独立于其L1缓存的,L2缓存中的数据和L1缓存中的数据是完全没有重复的。它们之间有2条单行的64位传输线路来互相传输数据,但是这两条64位、仅8字节传输量的总线其延迟是很高的,不过AMD设计了极高的缓存命中率(高达95%以上)来使得K8L的L1缓存和L2缓存可以满足数据互换的需要,另外AMD也在争取将其64位线路扩展为128位,当然这就取决于AMD技术人员和其制造工艺的发展情况。
[page_break] 自K8构架起,AMD在CPU内部集成了内存控制器。这使得CPU将数据绕过L2缓存直接与L1缓存和内存相连,L2缓存则储存L1缓存中所没有的其他紧缺数据。这大大加速了K8构架的内存性能和核心数据处理速度。K8L构架中依然采用了K8构架的独立缓存方案及内置处理器内存控制器方案:L1缓存、L2缓存与L3缓存之间取消了数据的预提和缓冲关系,而是直接与内存和核心相连。不过这一方案的性能要取决于AMD的缓存技术发展情况,如果AMD不能大幅度提高其现有K8构架处理器表现出的缓存技术水平,则K8构架中大受欢迎的内置内存控制器方案可能会使K8L构架处理器在缓存速度方面落后于INTEL的CORE构架。
二、开创性共享L3缓存的引入
相对过去所有的CPU构架而言,K8L构架最突出的特点就是其4个核心处理器将拥有一个共享的L3缓存。L3缓存与4颗内核同样原生于一块晶圆,其容量为最小2M起跳。同L2缓存一样,L3缓存也是独立的,L1缓存的数据和L3缓存的数据是不会重复的。
正如CORE构架共享L2缓存的Advanced Smart CacheCore技术使得其L2缓存性能比双核PENTIUM D处理器的L2缓存性能翻倍一样,AMD此次采用的更为先进的四核心共享L3缓存技术将使K8L构架处理器的4颗核心获得极快速的数据交换能力,同时更智能和动态化的分用L3缓存。另外在单核心负荷量极大而其它核心较为空闲的情况下,L3缓存将可以比CORE构架的智能共享L2缓存更快速的为负载大的核心提供更大更快的缓存空间。L3缓存对K8L构架处理器的性能提升是巨大的,全新的L3缓存设计将使K8L构架处理器比K8构架处理器的缓存效率提高2倍以上,从而对CPU整体性能的提升做出极大的贡献。
CORE构架中采取的是的8路32K的L1缓存和16路2-4M的L2缓存,其间的总线带宽为256位。高速的L1缓存和超大容量的L2缓存使CORE构架不用仅依靠缓慢的内存系统,而直接从L2换存中提取到需要的数据,再通过高速的256位传输总线与L1缓存和内部解码器相连。这一改进使CORE构架的SPEC INT性能较过去的PENTIUM D得到了40%的提高。(相对于Yonah核心在大部分SPEC子项目测试中)
支持DDR3内存
另一方面,K8L构架的内存系统将支持DDR3内存和FB-DIMM标准,同时还将升级为Hyper-Transport 3,不过无论是DDR3、FB-DIMM 或是 Hyper-Transport 3,这对于K8L性能的提升是有十分有限的。与显卡强势的GDDR3显存不同,DDR3带给K8L构架处理器的性能提升则不明显的多。
三、K8L构架的指令派遣 - 速度加倍
K8构架在每一时钟周期内可以从L1缓存中读取16字节的核心数据,这意味着K8构架处理器可以在一周期内同时完成并行的3条5字节的指令处理任务。很明显的例子,拥有寄存器处理能力的SSE2指令是4字节的(例如MOVAPD XMM0, XMM1),间接寻址指令则有6-8字节,如果是64位模式同时使用寄存器、添加REX前缀的SSE2指令则将增加至7-9字节。(SSE在标量情况下将与之相同,矢量情况下会少1字节。)
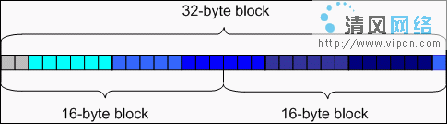
所以,每周期16字节的取指令派遣速度不能保证K8构架CPU能每周期完成3条指令,但是因为在K8构架中SSE/SSE2矢量指令必须要分两部分来完成这3条指令,所以16字节的取指令速度还可以满足K8构架的64位FPU数据处理需求。但是在未来的K8L构架中,一周期连续指令将增加到3指令或者更多条,这样16字节的取指令能力就不能够满足了。如图2,未来K8L构架的32字节数据取指令能力可以在一周期读取5条指令,而过去的K8构架取指令最大16字节的能力则需要将其延时一倍的时间。
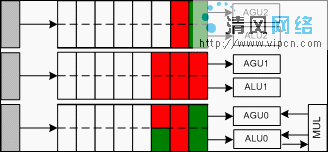
· K8构架每周期发出6条宏指令(分别解码为9条微指令),整数列队容量为最大24条宏指令。
· K8L构架每周期发出8条宏指令(分别解码为11条微指令),整数列队容量为最大32条宏指令。
· CORE构架每周期发出8条宏指令(分别解码为11条微指令),整数列队容量为最大32条宏指令。

| 上一页 [1] [2] [3] [4] [5] 下一页 |
[page_break] CORE构架的取指令能力也是16字节的,所以它最大也只能满足一周期4条平均4字节的指令。为了解决这个弱点,INTEL设计了特殊的双内置64字节缓冲器来连接发出一条64字节指令,并在一周期内完成连续的32字节指令。
改进的分支预测单元和运算法则
K8构架的分支预测单元比Conroe的分支预测单元更加简洁高效,但是K8简洁的分支预测单元也同样有着弱点,例如省略了的间接分支预测功能将会影响到其多面体指令的性能,其预测准确率也将低于对手,这也是同频率K8在3D图形性能运用中远不敌Conroe的原因之一。所以在K8L构架中,AMD针对这一重点问题将做一系列大的改进,包括添加更为全面的预测指令和改进预测运算法则等。
四、K8L的整数性能
改进的乱序执行方式
编译好的宏指令Macro-Ops以三条为一组发送到指令控制器ICU,指令控制器把宏指令的信息存入重排序缓冲区ROB,然后转移到调度程序Scheduler等待调出。重排序缓冲区会自动保存宏指令的信息并且控制他们的退出顺序, 宏指令依然以三条一组的方式退出,由调度程序分派到不同执行单元进行下一步编译。调度程序分派出的宏指令在三条整数列队中排序为8条一组、共24条,同时它们的出入顺序也由编码器记录。每24条宏指令排满后,调度程序就立即向算数逻辑单元ALU发出整数运算指令,同时也向地址产成单元AGU发出寻址指令。这样,每一时钟周期就可以同时完成3条宏指令和2条寻址指令。例如:
· add ebx,ecx;
· mov eax,[ebx+10h];快速寻址计算
· mov ecx,[eax+ebx];地址依赖于前一个指令操作
· mov edx,[ebx+24h];这个指令在前面所有指令的地址计算完成之前是不会被执行的
三个一排的宏指令组会在执行后从ROB中移出,宏指令的排序和移出使得调度单元动态的控制着整体资源,提高处理器工作效率。不过当三个宏指令序列中有一个出现满载情况,那么新的宏指令序列就不能进入调度单元。但是在实际操作中出现这样的情况并不是太多,即使偶尔发生这种情况也并不会对处理器的执行效率有太大的影响。除此之外,组中宏指令组到调度单元序列的静态链接也有可能会降低调度单元的工作效率,因为一个序列可能含有2个或更多的宏指令等待执行,另一个序列则可能一个等待的宏指令也没有。这种情况在实际执行中并不常见,通常在管线中都会有足够多的等待执行指令。
在“AMD与奔腾4的终结!Intel世袭构架涅磐”一文中,我们提到过:“在过去的几年里,大多数CPU都远离了乱序执行方式(OOOE)的内核设计思路,而偏向了有序执行方式(IOE),大量的VLIW处理器的性能都严重受限于程序与编码器,而现在Core的出现则代表了INTEL当前OOOE方式的最高设计水平,INTEL宣称Core将比现有的IOE处理器更好更合理的迅速处理完数据。”现在令DIYER满意的是,AMD也将采用其最新的OOOE技术,运用到AMD赋予厚望、对抗强敌CORE构架的K8L构架之中,这将使K8L构架与CORE构架在寻址速度、数据介入上达到同一水准。同样的,乱序执行OOOE是必须有序输出BIO的,AMD的工程师们使用了同样成熟的Memory Disambiguation技术,可以也让K8L构架中存数和取数指令同时进行乱序执行而不用等待前排取数/存数指令的完成。这一优化也使K8L构架节约了一倍的亢余周期,使其存储器数据处理/传输环节速度显著加快。K8L构架和CORE构架的乱序执行机制存在着一些技术上的差异,不过都为每时钟周期5条宏指令的派遣速度(3 ALU+2 MEM)。
改进的整数处理单元
数据块中的X86指令被编码为宏指令,每个宏指令分解为两个微指令:一个整数或浮点运算指令和一个内存寻址操作。K8构架处理器区分有三种不同的指令:
| 上一页 [1] [2] [3] [4] [5] 下一页 |
[page_break] · 单直接路径指令被硬件解码器的编译成一个宏指令
· 双直接路径指令被硬件解码器编译成两个宏指令
· 矢量路径指令被芯片整合的微代码引擎ROM解码成3条或更多的宏指令
K8构架不能够同时派遣出直接路径指令和矢量路径指令。解码器每周期最大只能完成3条宏指令,所以硬件解码器能完成三条单直接路径指令、一条单直接路径指令和一条双直接路径指令、或者一条半的双直接路径指令(分为两个周期完成的三条双直接路径指令),而矢量路径指令则需要更多的时间。
宏指令在硬件解码器中编译然后被统一成组发出,一组可能包含2个甚至1个宏指令以分隔直接路径和矢量路径,或者是区分不同组的指令。SSE、SSE2、SSE3中的矢量路径指令被K8构架处理器分为多条宏指令,然后由其64位执行单元分为两部分来处理这些128位的数据。这就是K8构架处理器把矢量路径指令解码成3条或更多条宏指令的原因。在K8L构架中,SSE执行单元将加宽到128位,这样就可以在一周期内完成部分的完整SSE指令,这意味着优化SSE指令后K8L构架处理器的处理速度至少比同频率K8构架处理器提高20%以上。
虽然K8L构架依然无法在一周期内完成4-5条指令而CORE构架可以,但是这并不会负面影响到K8L构架处理器的性能,因为一般而言,绝大部分周期指令都是不多于三条的,而且K8L构架由SSE指令分解出的宏指令数量要远低于Conroe。
与K8构架不同,CORE构架的3个整数执行单元中有2个为SIU简单整数单元快速执行单元,另一个为CIU复杂整数单元,同时宏指令的列队容量为32条,这使得CORE构架的整数执行效率要比K8构架稍高。但在K8L构架中AMD则设计为3个SIU简单整数单元和1个CIU复杂整数单元,总的来看,K8L构架处理器和CORE构架处理器的整数性能是处于同一水平的,严格的来看,K8L构架稍微领先于CORE构架,毕竟K8L构架要晚于对手半年多才定案。
五、K8L构架的浮点运算性能 - 两倍于K8构架
在当前的K8构架中,64位的FPU单元使得所有的128位浮点宏指令是必须被分为两条64位宏指令来进行传输和编译的,这样多出的分解过程、两倍数量的宏指令传输过程、载入、再组合等过程严重影响了K8构架的浮点性能。这已经从众多测试软件中明显的显现出来。
得益于2006年工艺的大幅度提升,AMD在K8L构架的浮点运算器方面有了进行翻倍性能加强的能力:FADD、FMUL及SSE等浮点运算器将由64位扩展到128位。同时,K8L构架的两条浮点数据传输带宽也加宽到128位,这使得处理器可以与L1缓存进行128位的高速传输。相比只拥有一条浮点数据传输带的CORE构架,K8L将有一定的优势。同时,K8L构架在浮点FADD和FMUL中也将拥有128位的ADD/MUL块处理能力来面对SSE2数据。在K8构架中FSTORE单元所存在的传输及运算法则缺陷等问题也将在K8L中得到改进。
另外,相对于K8构架的1个双精度浮点FADD和1个双精度浮点FMUL,K8L构架翻倍的增强了其浮点计算峰值的性能,并引入了新的指令集FMAC等和改进了算法法则。K8L构架相比过去K8构架的1个双精度浮点运算/时钟的能力,提高到2个双精度浮点/时钟。除去引入的新指令集的优势,K8L构架也已经把K8构架的1个双精度浮点FADD及FMUL/时钟,提高到K8L构架的2个双精度浮点FADD及FMUL/时钟。K8L构架在基于SSE/SSE2/SSE3的浮点运算运用中也会有一定程度的提高--实现了单周期执行同一并行SSE2指令的能力,这点和CORE构架是一样的,而K8构架则需要2周期。(不过在SSE浮点任务上K8L构架依然会落后于同频CORE构架处理器。)
FPU性能翻倍的同时,过去在K8构架中的两条FPU宏指令将在K8L构架中将能够融合为一条宏指令来同时分派和编译,增强了数据处理的合理性和便利性。所以128位的浮点运算单元将至少使K8L构架处理器在FPU、向量SSE数据的分派、传输、解码速度三方面同时达到现有K8构架处理器的两倍速度。
| 上一页 [1] [2] [3] [4] [5] 下一页 |
[page_break] 总的来看,K8L构架的浮点运算能力将至少比K8构架快一倍,甚至比当前最强大的CORE构架处理器还要快10%,尤其在处理没有SSE优化的X87数据上,K8L将比CORE构架快50%以上。
六、全新构架07年夏季登场
AMD日前进一步公布了K8L构架处理器的发售时间计划,其中最先于2007年夏季销售的四核心K8L构架处理器代号为Barcelona(巴塞罗那),支持Hyper-Transport 2.0,步进为Rev H核心,功耗将从68W至120W不等,其主流型号TDP将为95W。此功耗控制对于四核心、2M L3缓存的强大K8L处理器而言是比较令人满意的,四核心和L3缓存的引入并没有使K8L构架处理器出现预先担忧的150W左右的巨大功耗,这与INTEL因功耗控制问题而屡屡遇挫的Netburst构架形成了鲜明的对比。
代号Budapest(布达佩斯)的完善版K8L核心则于2007年秋末上市,支持更新的Hyper-Transport 3.0、更大的L3缓存容量,其型号将为Opteron 12XX系列以及ATHLON64全系列。
2008年春季,代号为Shanghai(上海)的最强服务器版四核心处理器 - Opteron22XX以及82XX系列届时将成为AMD最强的处理器,AMD将引入更多新的电路技术来控制其功耗等问题。
K8L构架相对于K8构架的进步是巨大的,K8L构架中多种最新技术的引入使得DIY用户们有信心在明年就可以更换为目前遥不可及的四核处理器。同时AMD和INTEL的争夺也将更为激烈,而广大DIY用户们则在欣赏激斗的同时可以轻松获得物美价廉的强大处理器--无论是CORE构架或者K8L构架。
(出处:http://www.zzzyk.com/)
| 上一页 [1] [2] [3] [4] [5] |
上一个:为什么我的电脑一遇潮湿天气就启动不了?
下一个:高手近来帮忙看看?