INDEX FAST FULL SCAN AND SKIP SCAN
INDEX FAST FULL SCAN AND SKIP SCAN
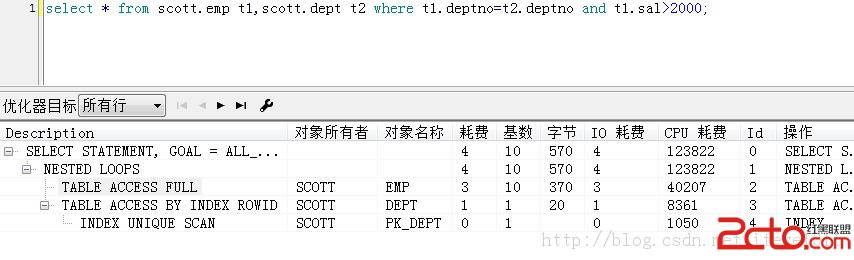
在快速扫描索引时,oracle读取b-tree索引的所有叶子节点块,而且是顺序读,而且可以同时读取db_file_multiblock_read_count,
而且索引快速扫描比full table scan的物理IO小很多,可以更快的响应请求。以下还是看下原文:
The fast full scan can be used if all of the columns in the query for the table are in the index
with the leading edge of the index not part of the WHERE condition.
In the following example, the emp table is used. As shown
earlier in this chapter, it has a concatenated index on the columns empno, ename, and deptno.
select empno, ename, deptno
from emp
where deptno = 30;
Since all of the columns in the SQL statement are in the index, a fast full scan is available.
Index fast full scans are commonly performed during joins in which only the indexed join key
columns are queried. As an alternative, Oracle may perform a skip-scan access of the index; the
optimizer should consider the histogram for the Deptno column (if one is available) and decide
which of the available access paths yields the lowest possible performance cost.
既然这里提到了SKIP SCANS,顺别看一下,SKIP SCAN比FAST FULL SCAN INDEX 更快
为了好理解,就拿书中的例子看一下:
这里emp5表有N 万行,建议一个组合索引,如果在查询中不使用引导列作为查询条件,也就是where后面不能有JOB列的限制
优化器为CBO,引导列JOB最好没有重复值,可以强制使用index
create index skip1 on emp5(job,empno);
select count(*)
from emp5
where empno = 7900;
Execution Plan
0 SELECT STATEMENT Optimizer=CHOOSE (Cost=4 Card=1 Bytes=5)
1 0 SORT (AGGREGATE)
2 1 INDEX (FAST FULL SCAN) OF 'SKIP1' (NON-UNIQUE)
Statistics
6826 consistent gets
6819 physical reads
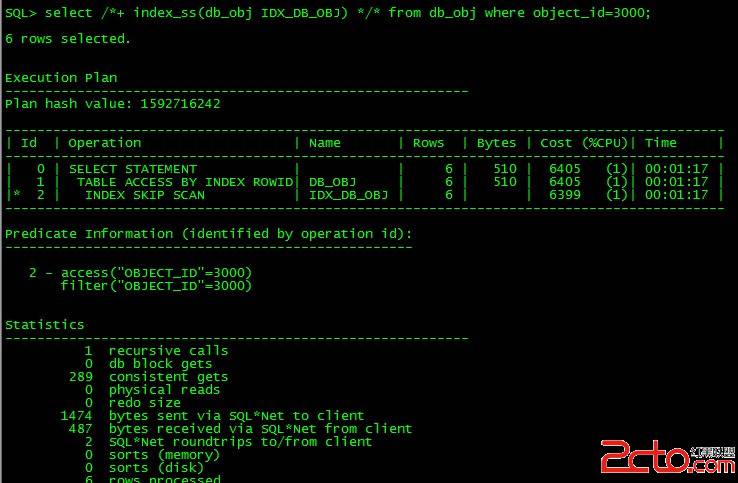
select /*+ index(emp5 skip1) */ count(*)
from emp5
where empno = 7900;
Elapsed: 00:00:00.56
Execution Plan
0 SELECT STATEMENT Optimizer=CHOOSE (Cost=6 Card=1 Bytes=5)
1 0 SORT (AGGREGATE)
2 1 INDEX (SKIP SCAN) OF 'SKIP1' (NON-UNIQUE)
Statistics
21 consistent gets --------逻辑IO相比较而言小了很多
17 physical reads
这里可以看到IO上的区别是很明显的,逻辑IO和物理IO小了很多,有利就有弊,使用SKIP SCAN虽然IO上是有效果,但是CPU的消耗会增加,以上就可以看出,cost变大了,不能盲目使用,以下两个例子CPU COST很明显

使用SKIP SCAN,可以看到逻辑读是比全表扫描少了,CPU cost大了不少
网上有资料说SKIP SCAN是转化为多个SQL union操作,如果前导列重复值很少,将转化为大量的UNION操作,这样效率肯定会低很多。所以前导列重复值多的时候,不会选择skip scan,而且从B-TREE索引的结构看出,确实是选择性越高,那么索引的效果越好。所以一般组合索引,都是选择性高的做为前导列。至于什么时候用skip scan,这个看情况而定了,万事都有个权衡。
在快速扫描索引时,oracle读取b-tree索引的所有叶子节点块,而且是顺序读,而且可以同时读取db_file_multiblock_read_count,
而且索引快速扫描比full table scan的物理IO小很多,可以更快的响应请求。以下还是看下原文:
The fast full scan can be used if all of the columns in the query for the table are in the index
with the leading edge of the index not part of the WHERE condition.
In the following example, the emp table is used. As shown
earlier in this chapter, it has a concatenated index on the columns empno, ename, and deptno.
select empno, ename, deptno
from emp
where deptno = 30;
Since all of the columns in the SQL statement are in the index, a fast full scan is available.
Index fast full scans are commonly performed during joins in which only the indexed join key
columns are queried. As an alternative, Oracle may perform a skip-scan access of the index; the
optimizer should consider the histogram for the Deptno column (if one is available) and decide
which of the available access paths yields the lowest possible performance cost.
既然这里提到了SKIP SCANS,顺别看一下,SKIP SCAN比FAST FULL SCAN INDEX 更快
为了好理解,就拿书中的例子看一下:
这里emp5表有N 万行,建议一个组合索引,如果在查询中不使用引导列作为查询条件,也就是where后面不能有JOB列的限制
优化器为CBO,引导列JOB最好没有重复值,可以强制使用index
create index skip1 on emp5(job,empno);
select count(*)
from emp5
where empno = 7900;
Execution Plan
0 SELECT STATEMENT Optimizer=CHOOSE (Cost=4 Card=1 Bytes=5)
1 0 SORT (AGGREGATE)
2 1 INDEX (FAST FULL SCAN) OF 'SKIP1' (NON-UNIQUE)
Statistics
6826 consistent gets
6819 physical reads
select /*+ index(emp5 skip1) */ count(*)
from emp5
where empno = 7900;
Elapsed: 00:00:00.56
Execution Plan
0 SELECT STATEMENT Optimizer=CHOOSE (Cost=6 Card=1 Bytes=5)
1 0 SORT (AGGREGATE)
2 1 INDEX (SKIP SCAN) OF 'SKIP1' (NON-UNIQUE)
Statistics
21 consistent gets --------逻辑IO相比较而言小了很多
17 physical reads
这里可以看到IO上的区别是很明显的,逻辑IO和物理IO小了很多,有利就有弊,使用SKIP SCAN虽然IO上是有效果,但是CPU的消耗会增加,以上就可以看出,cost变大了,不能盲目使用,以下两个例子CPU COST很明显
使用SKIP SCAN,可以看到逻辑读是比全表扫描少了,CPU cost大了不少
网上有资料说SKIP SCAN是转化为多个SQL union操作,如果前导列重复值很少,将转化为大量的UNION操作,这样效率肯定会低很多。所以前导列重复值多的时候,不会选择skip scan,而且从B-TREE索引的结构看出,确实是选择性越高,那么索引的效果越好。所以一般组合索引,都是选择性高的做为前导列。至于什么时候用skip scan,这个看情况而定了,万事都有个权衡。