谈数据库索引和Sqlite中索引的使用
谈数据库索引和Sqlite中索引的使用
要使用索引对数据库的数据操作进行优化,那必须明确几个问题:
1.什么是索引 www.zzzyk.com
2.索引的原理
3.索引的优缺点
4.什么时候需要使用索引,如何使用
围绕这几个问题,来探究索引在数据库操作中所起到的作用。
1.数据库索引简介
回忆一下小时候查字典的步骤,索引和字典目录的概念是一致的。字典目录可以让我们不用翻整本字典就找到我们需要的内容页数,然后翻到那一页就可以。索引也是一样,索引是对记录按照多个字段进行排序的一种展现。对表中的某个字段建立索引会创建另一种数据结构,其中保存着字段的值,每个值还包括指向与它相关记录的指针。这样,就不必要查询整个数据库,自然提升了查询效率。同时,索引的数据结构是经过排序的,因而可以对其执行二分查找,那就更快了。
2. B-树与索引
大多数的数据库都是以B-树或者B+树作为存储结构的,B树索引也是最常见的索引。先简单介绍下B-树,可以增强对索引的理解。
B-树是为磁盘设计的一种多叉平衡树,B树的真正最准确的定义为:一棵含有t(t>=2)个关键字的平衡多路查找树。一棵M阶的B树满足以下条件:
1)每个结点至多有M个孩子;
2)除根结点和叶结点外,其它每个结点至少有M/2个孩子;
3)根结点至少有两个孩子(除非该树仅包含一个结点);
4)所有叶结点在同一层,叶结点不包含任何关键字信息,可以看作一种外部节点;
5)有K个关键字的非叶结点恰好包含K+1个孩子; www.zzzyk.com
B树中的每个结点根据实际情况可以包含大量的关键字信息和分支(当然是不能超过磁盘块的大小,根据磁盘驱动(disk drives)的不同,一般块的大小在1k~4k左右);这样树的深度降低了,这就意味着查找一个元素只要很少结点从外存磁盘中读入内存,很快访问到要查找的数据。B-树上操作的时间通常由存取磁盘的时间和CPU计算时间这两部分构成。而相对于磁盘的io速度,cpu的计算时间可以忽略不计,所以B树的意义就显现出来了,树的深度降低,而深度决定了io的读写次数。
B树索引是一个典型的树结构,其包含的组件主要是:
1)叶子节点(Leaf node):包含条目直接指向表里的数据行。
2)分支节点(Branch node):包含的条目指向索引里其他的分支节点或者是叶子节点。
3) 根节点(Root node):一个B树索引只有一个根节点,它实际就是位于树的最顶端的分支节点。
如下图所示:

每个索引都包含两部分内容,一部分是索引本身的值,第二部分即指向数据页或者另一个索引也的指针。每个节点即为一个索引页,包含了多个索引。 www.zzzyk.com
当你为一个空表建立一个索引,数据库会分配一个空的索引页,这个索引页即代表根节点,在你插入数据之前,这个索引页都是空的。每当你插入数据,数据库就会在根节点创建索引条目,。当根节点插满的时候,再插入数据时,根节点就会易做图。举个例子,根节点插入了如图所示的数据。(超过4个就易做图),这时候插入H,就会易做图成2个节点,移动G到新的根节点,把H和N放在新的右孩子节点中。如图所示:

根节点插满4个节点
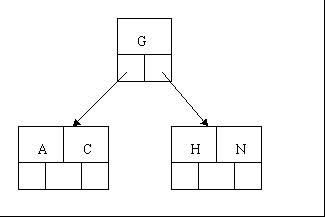
插入H,进行易做图。
大致的易做图步骤如下:
1)创建两个儿子节点
2)将原节点中的数据近似分为两半,写入两个新的孩子节点中。
3)在跟节点中放置指向页节点的指针
当你不断向表中插入数据,根节点中指向叶节点的指针也易做图满,当叶子还需要易做图的时候,根节点没有空间再创建指向新的叶节点的指针。那么数据库就会创建分支节点。随着叶子节点的易做图,根节点中的指针都指向了这些分支节点。随着数据的不断插入,索引会增加更多的分支节点,使树结构变成这样的一个多级结构。 www.zzzyk.com
3. 索引的种类
1)聚集索引:表中行的物理顺序与键值的逻辑(索引)顺序相同。因为数据的物理顺序只能有一种,所以一张表只能有一个聚集索引。如果一张表没有聚集索引,那么这张表就没有顺序的概念,所有的新行都会插入到表的末尾。对于聚集索引,叶节点即存储了数据行,不再有单独的数据页。就比如说我小时候查字典从来不看目录,我觉得字典本身就是一个目录,比如查裴字,只需要翻到p字母开头的,再按顺序找到e。通过这个方法我每次都能最快的查到老师说的那个字,得到老师的表扬。
2)非聚集索引:表中行的物理顺序与索引顺序无关。对于非聚集索引,叶节点存储了索引字段值以及指向相应数据页的指针。叶节点紧邻在数据之上,对数据页的每一行都有相应的索引行与之对应。有时候查字典,我并不知道这个字读什么,那我就不得不通过字典目录的“部首”来查找了。这时候我会发现,目录中的排序和实际正文的排序是不一样的,这对我来说很苦恼,因为我不能比别人快了,我需要先再目录中找到这个字,再根据页数去找到正文中的字。
4.索引与数据的查询,插入与删除
1)查询。查询操作就和查字典是一样的。当我们去查找指定记录时,数据库会先查找根节点,将待查数据与根节点的数据进行比较,再通过根节点的指针查询下一个记录,直到找到这个记录。这是一个简单的平衡树的二分搜索的过程,我就不赘述了。在聚集索引中,找到页节点即找到了数据行,而在非聚集索引中,我们还需要再去读取数据页。 www.zzzyk.com
2)插入。聚集索引的插入操作比较复杂,最简单的情况,插入操作会找到对于的数据页,然后为新数据腾出空间,执行插入操作。如果该数据页已经没有空间,那就需要拆分数据页,这是一个非常耗费资源的操作。对于仅有非聚集索引的表,插入只需在表的末尾插入即可。如果也包含了聚集索引,那么也会执行聚集索引需要的插入操作。
3)删除。删除行后下方的数据会向上移动以填补空缺。如果删除的数据是该数据页的最后一行,那么这个数据页会被回收,它的前后一页的指针会被改变,被回收的数据页也会在特定的情况被重新使用。与此同时,对于聚集索引,如果索引页只剩一条记录,那么该记录可能会移动到邻近的索引表中,原来的索引页也会被回收。而非聚集索引没办法做到这一点,这就会导致出现多个数据页都只有少量数据的情况。
5. 索引的优缺点
其实通过前面的介绍,索引的优缺点已经一目了然。
先说优点:
1)大大加快数据的检索速度,这也是创建索引的最主要的原因
2)加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义。
3)在使用分组和排序子句进行数据检索时,同样可以显著减少查询中分组和排序的时间。
www.zzzyk.com
再说缺点:
1)创建索引需要耗费一定的时间,但是问题不大,一般索引只要build一次
2)索引需要占用物理空间,特别是聚集索引,需要较大的空间
3)当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,降低了数据的维护速度,这个是比较大的问题。
6.索引的使用
根据上文的分析,我们大致对什么时候使用索引有了自己的想法(如果你没有,回头再看一遍。。。)。一般我们需要在这些列上建立索引:
1)在经常需要搜索的列上,这是毋庸置疑的;
2)经常同时对多列进行查询,且每列都含有重复值可以建立组合索引,组合索引尽量要使常用查询形成索引覆盖(查询中包含的所需字段皆包含于一个索引中,我们只需要搜索索引页即可完成查询)。 同时,该组合索引的前导列一定要是使用最频繁的列。对于前导列的问题,在后面sqlite的索引使用介绍中还会做讨论。
3)在经常用在连接的列上,这些列主要是一些外键,可以加快连接的速度,连接条件要充分考虑带有索引的表。;
4)在经常需要对范围进行搜索的列上创建索引,因为索引已经排序,其指定的范围是连续的,同样,在经常需要排序的列上最好也创建索引。
6)在经常放到where子句中的列上面创建索引,加快条件的判断速度。要注意的是where字句中对列的任何操作(如计算表达式,函数)都需要对表进行整表搜索,而没有使用该列的索引。所以查询时尽量把操作移到等号右边。 www.zzzyk.com
对于以下的列我们不应该创建索引:
1)很少在查询中使用的列
2)含有很少非重复数据值的列,比如只有0,1,这时候扫描整表通常会更有效
3)对于定义为TEXT,IMAGE的数据不应该创建索引。这些字段长度不固定,或许很长,或许为空。
当然,对于更新操作远大
上一个:MongoDB学习(一)安装配置
下一个:mongo查询语法收藏



- 更多SQLite疑问解答:
- 数据库sqlite3 里:用函数sqlite3_get_table来获取数据是否 可以 排序么(order by cTime asc)
- 开始学sqlite,在下载了个sqlite3_exe,和一个sqlite admin数据库,我现在疑问的是,可以通过sqlite3.exe
- 关于Sqlite使用Group by以后的排序问题。
- sqlite做网络数据库怎么样
- sqlite支持动态sQL,能不能给个对表名进行拼接的,可以运行通的过的代码范例啊,大侠们
- 用SQLite expert创建的数据库,如何导入到android中
- sqlite3 开始建立数据库时,没有设定主键。怎么去修改
- Android中用SQLite数据库是出现的错误,帮忙解决一下:
- android 应用程序开发用到数据库 ,是否需要使用SQLite Manager
- sqlite查询条件参数为空怎么办
- Android sqlite通过字符串为条件执行删除某一记录的问题
- android 程序碰到问题,很简单的一个程序,从sqlite数据库里面查找数据,点击按钮后获得相应数据
- sqlite数据库中插入数据时出现database is locked!什么原因?我没有设置密码.
- ios移动开发、QT应用开发、ZigBee协议栈、SQlite数据库支持,这些都可以描述成我应用到的技术吗?
- sqlite和mysql有关系吗? 能代替mysql运行织梦程序吗?