10分钟搭建Hadoop集群
10分钟搭建Hadoop集群1. 准备
3台Linux机器或虚拟机,安装了CentOS6/Redhat6/Ubuntu;
www.zzzyk.com
在所有机器上都安装了ssh和rsync,ubuntu安装例子:
$ sudo apt-get install ssh
$ sudo apt-get install rsync
2. 规划节点:
将其中一台机器作为master作为NameNode,另外两台作为DataNode,命名3台机器为:node1,node2,node3,这里将node1作为NameNode,node2,node3作为dataNode;
在所有机器的/etc/hosts中加入hostname配置信息,加入如下例子中的红色部分:
www.zzzyk.com
127.0.0.1 localhost
# The following lines are desirable for IPv6 capable hosts
::1 ip6-localhost ip6-loopback
fe00::0 ip6-localnet
ff00::0 ip6-mcastprefix
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
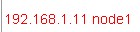
192.168.1.12 node2
192.168.1.13 node3
为方便管理和安装,在所有机器上创建同一个hadoop用户,以下所有操作都在此账户下进行。
设置无密码登陆,在node1上创建public密钥,并将public密钥copy到其他节点机器,并将public密钥导入到所有机器(包括本机):
$ ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
$ cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
规划hadoop数据目录,在所有机器上创建如下目录:
$ mkdir ~/data
$ mkdir ~/data/hdfs
$ mkdir ~/data/hdfs/name #namenode
$ mkdir ~/data/hdfs/data #datanode
$ mkdir ~/data/hdfs/tmp #临时文件夹
解压:tar -zxvf hadoop-1.0.4-bin.tar.gz
修改配置文件:
hadoop-1.0.4/conf/hadoop-env.sh 中指定JAVA_HOME:
# The java implementation to use. Required.
# export JAVA_HOME=/usr/lib/j2sdk1.5-sun
export JAVA_HOME=/opt/java/jdk1.6.0_24
# Extra Java CLASSPATH elements. Optional.
# export HADOOP_CLASSPATH=
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/data/hdfs/tmp</value>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://node1:9000</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/home/hadoop/data/hdfs/name</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/home/hadoop/data/hdfs/data</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>node1:9001</value>
</property>
<property>
<name>mapreduce.jobtracker.system.dir</name>
<value>/home/hadoop/data/hdfs/mapred/system</value>
</property>
<property>
<name>mapreduce.cluster.local.dir</name>
<value>/home/hadoop/data/hdfs/mapred/local</value>
</property>
node1
hadoop-1.0.4/conf/slaves
node2
node3
4. 同步hadoop所有软件和配置到其他机器node3
创建目标机器列表文件,并加入目标机器名:/home/hadoop/servers
node2
node3
创建同步脚本:/home/hadoop/cp_hadoop
node3
for host in `cat servers`
do
echo ------------------------------------------------------------------
echo rsync host: $host
ssh $host 'rm -fr /home/hadoop/hadoop-1.0.4'
rsync -avz /home/hadoop/hadoop-1.0.4 $host:/home/hadoop/hadoop-1.0.4
done
执行同步脚本: $ ./cp_hadoopdo
echo ------------------------------------------------------------------
echo rsync host: $host
ssh $host 'rm -fr /home/hadoop/hadoop-1.0.4'
rsync -avz /home/hadoop/hadoop-1.0.4 $host:/home/hadoop/hadoop-1.0.4
done
www.zzzyk.com
5. 启动所有服务:
$ cd /home/hadoop/hadoop-1.0.4/bin
$ ./start_all.sh
6. 访问web界面验证安装:$ ./start_all.sh
NameNode - http://node1:50070/
JobTracker - http://node2:50030/