深入理解递归
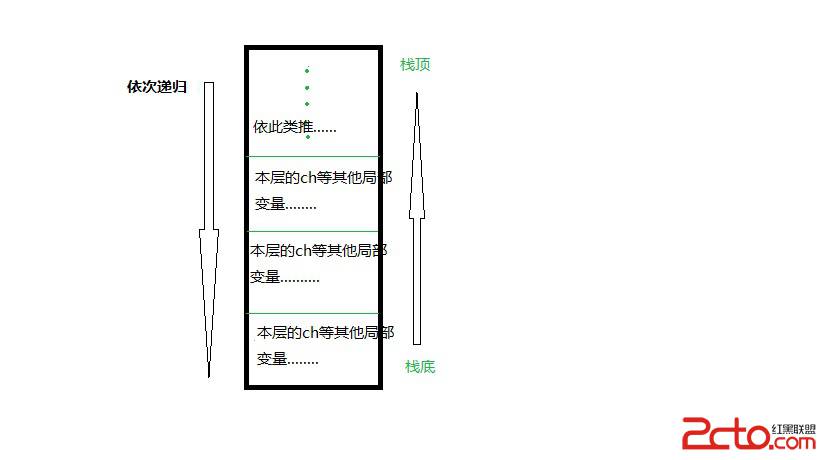
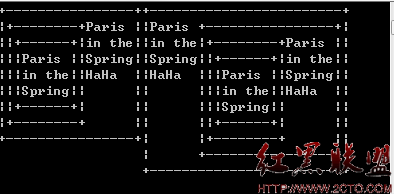
大家都知道,递归的本质和栈数据的存取很相似了,都是先进去,但是往往最后处理!再者对于递归函数的局部变量的存储是按照栈的方式去存的,对于每一层的递归函数在栈中都保存了本层函数的局部变量,一边该层递归函数结束时能够保存原来该层的数据!如图:
如上图递归式依次往下进行的,并且在该层递归函数还没结束即将进入下一层递归调用时,将会把该层函数中的局部变量保存起来,以供下次使用!
好了,以上是递归函数的数据存储方式,可是有时候我们又得抓头了,递归的话,有时候又很难理解,貌似总也想不通!
于是我又把每一层递归函数化分为三部分了,第一部分:是递归调用前的一些数据处理,判断以及递归结束判断(当然了结束条件肯定在递归调用前,要不每次递归就不会结束了),第二部分:就是递归函数本身了。而第三部分:当然就是递归函数的后续处理代码了!在这里我想我们得想明白一件事情了,每一层的函数都是在上一层递归函数结束时才返回的然后接着处理该层递归函数剩下的部分!例如如下代码:
[cpp]
#include<iostream>
#include<string>
using namespace std;
int i=0,j;
void reverse(string &s);
int main()
{
string s;
cin>>s;
j=i=s.size();
reverse(s);
cout<<s<<endl;
return 0;
}
void reverse(string &s)
{
char ch; //..........第一部分 ..........
i--;
ch=s[i];
cout<<ch<<endl; //这里i是全局变量,而ch是局部变量会保存在栈中
if(-1==i)
return;
reverse(s); //本身的递归看做第二部分
//后续部分看做第三部分
s[--j]=ch; //这句当且仅当该递归函数中的reverse返回时 才执行
cout<<ch<<endl;
}
在以上代码中,每一层只有当reverse()结束了才会接着处理下面的s[--j]=ch;代码,因为每一次递归进去的时候reverse()上面的代码都已经处理了,所以当递归返回时处理的自然就是reverse()下面的代码了,如此循环直到结束!不过我觉着最重要的还有一样就是有时候不必刻意去关注的那么细,也要有全局观,例如我们只需要知道函数reverse()是继续处理同样的功能,没必要再去想这个函数里面又是怎么样怎么样的,我感觉肯定会抓狂的!希望跟我一样纠结的朋友不在纠结递归了.........
另外,
递归的使用条件:
存在一个递归调用的终止条件;
每次递归的调用必须越来越靠近这个条件;只有这样递归才会终止,否则是不能使用递归的!
总之,在你使用递归来处理问题之前必须首先考虑使用递归带来的好处是否能补偿
他所带来的代价!否则,使用迭代算易做图比递归算法要高效。
递归的基本原理:
1 每一次函数调用都会有一次返回.当程序流执行到某一级递归的结尾处时,它会转移到前一级递归继续执行.
2 递归函数中,位于递归调用前的语句和各级被调函数具有相同的顺序.如打印语句 #1 位于递归调用语句前,它按照递归调用的顺序被执行了 4 次.
3 每一级的函数调用都有自己的局部变量.
4 递归函数中,位于递归调用语句后的语句的执行顺序和各个被调用函数的顺序相反.
即位于递归函数入口前的语句,右外往里执行;位于递归函数入口后面的语句,由里往外执行。
5 虽然每一级递归有自己的变量,但是函数代码并不会得到复制.
6 递归函数中必须包含可以终止递归调用的语句.
一旦你理解了递归(理解递归,关键是脑中有一幅代码的图片,函数执行到递归函数入口时,就扩充一段完全一样的代码,执行完扩充的代码并return后,继续执行前一次递归函数中递归函数入口后面的代码),阅读递归函数最容易的方法不是纠缠于它的执行过程,而是相信递归函数会顺利完成它的任务。如果你的每个步骤正确无误,你的限制条件设置正确,并且每次调用之后更接近限制条件,递归函数总是能正确的完成任务。
不算递归调用语句本身,到目前为止所执行的语句只是除法运算以及对quotient的值进行测试。由于递归调用这些语句重复执行,所以它的效果类似循环:当quotient的值非零时,把它的值作为初始值重新开始循环。但是,递归调用将会保存一些信息(这点与循环不同),也就好是保存在堆栈中的变量值。这些信息很快就会变得非常重要。
斐波那契数是典型的递归案例:
Fib(0) = 0 [基本情况] Fib(1) = 1 [基本情况]
对所有n > 1的整数:Fib(n) = (Fib(n-1) + Fib(n-2)) [递归定义]
递归算法一般用于解决三类问题:
(1)数据的定义是按递归定义的。(Fibonacci函数)
(2)问题解法按递归算法实现。(回溯)
(3)数据的结构形式是按递归定义的。(树的遍历,图的搜索)
如:
procedure a;
begin
a;
end;
这种方式是直接调用.
又如:
procedure b;
begin
c;
end;
procedure c;
begin
b;
end;
这种方式是间接调用.
如何设计递归算法
1.确定递归公式
2.确定边界(终了)条件
补充:软件开发 , C++ ,