ASP.NET程序性能优化心得(1):数据库篇
数据库性能优化
一、字段的建立1、减少跨表查询
需求确定后往往就开始建立数据库,那么建立数据库,对数据库的操作离不开增删改查这些最基本的操作,其中查询应该是频繁的操作,提升查询操作的一个基本的原则是尽量减少跨表查询,也就是JOIN、UNION和子查询等,这种情况往往最为常见,往往是A表中其中一个字段是B表的外键,查询时往往需要同时将A表中的数据全部查询出来,同时再把匹配A表外键的字段查询出来,这样就会大大增加查询的成本。这里我们以文章系统为例,一般表结构如下:
News(NewsId,NewsTitle,Content,CateId,PostUserId,Hits,AddTime)--文章
NewsCate(CateId,CateTitle)--文章分类
这样的表结构肯定就需要使用两次查询或者连接查询等方法来取得两张表的数据。如果统计一个分类下的文章数量,还需要SELECT COUNT(*)来进行News表的全表扫描来完成,这样就会在性能上受到严重影响。对于这种本身表结构设计欠合理的情况,优化SQL语句基本作用不大,改进方法是将表中需要跨表查询的地方减少到最小,可以将表结构建立如下:
News(NewsId,NewsTitle,Content,CateId,CateName,PostUserId,PostUserName,Hits,AddTime)
NewsCate(CateId,CateTitle,NewsNum)
这里进行了两个地方的改进,一是将CateName同时并入到News表中,这样可以避免跨表连接查询带来的性能损耗(PostUserName与此类似);二是将News表中的总记录数存入NewsCate表中的NewsNum字段中,可以避免SELECT COUNT(*)带来的性能损耗(在大数据量的情况下效果是非常明显的)。由此产生的冗余字段带来的性能影响与之前的性能影响相比较,可以很明显的对比出来。这种优化可以称为以空间换时间。2、排序问题
另外一点是针对AddTime字段,一般情况下以它排序的情况较多,这种DateTime类型字段在排序时会进行计算,它的排序比Int类型要慢得多,因此还可以考虑新增加一个DateNum(int)字段来储存日期,比如AddTime为2011-05-27,那么插入到DateNum可以是20110527这个数字,这样在排序时可以通过ORDER BY DateNum DESC来减少排序的时间。当然如果你的AddTime默认是getdate(),并且排序只有一个按时间排序的话,可以ORDER BY NewsID DESC来完成。
对于排序,数据库在查询出满足WHERE所有条件的数据后,然后再进行排序,因此如果没有必要,不要使用复杂的排序,可以根据实际情况考虑是否添加OrderNum来减少相关的排序;对于的确需要复杂的排序我们第二点会讲到索引问题来解决。
3、需要外键吗?
如果你的数据库学得不错的话,一定记得数据库范式,满足易做图范式才是标准的数据库设计,在实际情况中,绝不可完全照书本来。对于是否需要外键争论一直较多,我的理解是外键是一个约束,它在避免程序插入异常数据会有一定的帮助,异常的数据会导致程序需要异常处理的地方增加,随之代码增加,程序稳定性降低。但在实际的开发中,外键会导致调试程序的复杂,并且会在一定程序上降低SQL执行的效率,因为数据在插入前引擎会对数据的合法性进行校验,这样在一定程序上也会降低数据库的性能,另外对于外键数据在删除情况下查询主表数据可能会发生不可预料的异常。在网站中我的个人建议是不用外键,但为了避免出现DBNull的情况,“是否为空”这个选项在必要时要选择不允许为空。
二、索引的建立
在项目开始前要确定实际项目中可能哪些会频繁进行查询——一般情况下实际情况是程序员和DBA是同一个人,因此假设你已经知道了这些会频繁查询的地方。以一个文章系统为例来说,可能会有时间、分类和关键字这几种查询比较频繁。那么必要时要建立索引,一般情况需要对其各自建立索引,比如实际的表结构如下:
News(NewsId,NewsTitle,Content,CateId,CateName,PostUserId,PostUserName,Hits,AddTime,CommentNum)
假设以分类和时间排序来进行查询十分频繁,那么需要各自建立CateId和AddTime索引;如果这个查询属于复杂查询,如果SQL语句如下:SELECT * FROM News WHERE CateId=1 ORDER BY AddTime DESC,CommentNum DESC
那么可以建立多个字段的复合索引,这里可以将CateId,AddTime建立复合索引,如有必要可以将CommentNum也包括在内。对于搜索如果以关键字查询较为频繁,建议在查询字段上建立全文索引,全文索引是SQL Server内置的搜索算法来进行的查询规则,性能比LIKE就好很多。比如查询标题:
SELECT TOP 10 * FROM News WHERE CONTAINS(News,‘walkingp’)
*注意SQL 2000及以后的版本才有全文索引功能。三、查询的优化
查询是绝大多数SQL语句优化的用武之地,不同的SQL语句可能会让查询时间有着很大的区别;查询优化最核心的内容就是减少scan,尽量做到seek;scan代表全表扫描,seek代表定位到某一行。使用COUNT、NOT、!=、IN、LIKE等都会引起全表扫描,如果这张表数据足够多,那么性能影响是非常大的。更好的方法是避免这种全表扫描,使用最准确的条件限制来缩小数据库扫描的范围,减少SQL执行的时间。
以上表为例,ASP.NET程序最常使用的DAL功能是根据某一编号取数据然后存储到对象中。
SELECT * FROM News WHERE NewsId=@NewsId
这样即使在查询到需要的数据后,它仍会执行剩余数据的查询进行全表扫描,这样就浪费了大量的资源和程序时间。可以使用TOP 1来进行条件限制:SELECT TOP 1 * FROM News WHERE NewsId=@NewsId
假设有一百万条数据,实际中NewsId=1,那么我们就节约了查询999999条数据的时间。一般情况下News表会很大,而NewsCate会很少,对于这种对比非常悬殊的两表,如果进行连接查询,将数据小的NewsCate放到JOIN后面,这样可以提升查询性能。
关于查询优化,相关的资料非常丰富,大家可以自己去搜索一下,对于争执比较多的类似IN和EXISTS等问题,可以在实际数据库中测试其性能,然后决定选用哪一种。
四、SQL Profiler的使用
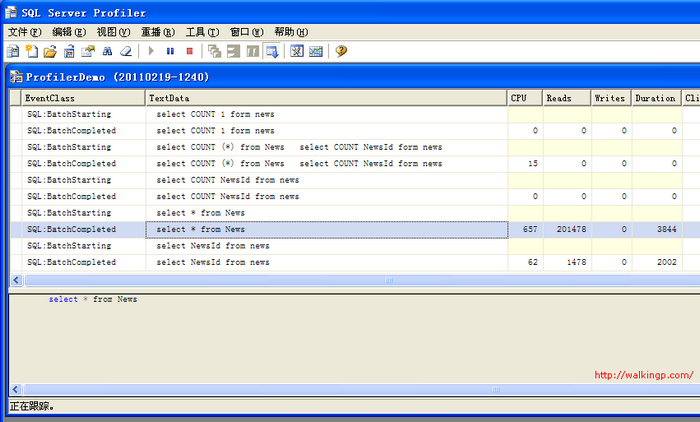
SQL Profiler是最容易被忽视的工具,而这个工具是数据库性能优化一个非常强大的工具,它与Management Studio在SQL Server安装时都会绑定在一起,选择新建跟踪,然后在跟踪属性中选择相应的事件列,一般选择CPU、Reads、Writes、Duration、StartTime、EndTime即可,它们对应了在物理上SQL语句对CPU的占用、对硬盘读写的次数和起止时间,通过它可以很直观地看出影响SQL性能的地方。
比如我这里测试是对一百万条数据SELECT *和SELECT NewsId的性能测试,可以较直观地看出SELECT * 在CPU损耗、和硬盘读取上会大很多。因此在实际项目中建议“吃多少,拿多少”。

补充:Web开发 , ASP.Net ,