当前位置:编程学习 > JSP >>
答案:当前,Java 2平台企业版(J2EE)架构在厂商市场和开发者社区中倍受推崇。作为一种工具,可扩展标记语言(XML)简化了数据交换、进程间消息交换这一类的事情,因而对开发者逐渐变得有吸引力,并开始流行起来。自然,在J2EE架构中访问或集成XML解决方案的想法也很诱人。因为这将是强大系统架构同高度灵活的数据管理方案的结合。 XML的应用似乎是无穷无尽的,但它们大致上可以分为三大类: ●简单数据的表示和交换(针对XML的简单API(SAX)和文档对象模型(DOM)语法解析,不同的文档类型定义(DTDs)和概要(schemas)) ●面向消息的计算(XML-RPC(远程过程调用),SOAP协议,电子化业务XML(ebXML)) ●用户界面相关、表示相关的上下文(可扩展样式表语言(XSL),可扩展样式表语言转换(XSLT)) 这几类应用在J2EE架构中恰好有天然的对应:数据表示和交换功能是EJB组件模型中持久化服务(persistence services)的一部分,基于消息的通讯由Java消息服务(JMS)API来处理,而界面表示正是Java服务器页面(JSP)和Java Servlets的拿手好戏。 在本文中,我们将看到当今基于J2EE的应用里,XML是如何在上述几个方面进行应用的,以及在相关标准的未来版本中这些应用将会如何发展。 基础:数据的表示和交换 原型化的XML应用(假设有的话)的内容通常是:数据以XML格式存放,为了进行显示、修改甚至写入某个XML文档而经常被读入到某个对象模型中。作为例子,假定我们正处理多种类型的媒体(图品、视频、文本文档等等),并且用下面这个简单的XML DTD来描述这些媒体的元数据: <!-- DTD for a hypothetical media management system --> <!-- Media assets are the root of the object hierarchy. Assets are also hierarchical - they can contain other assets. --> <!ELEMENT media-asset (name, desc?, type*, media-asset*, urn)> <!-- Metadata about the asset --> <!ELEMENT name (#PCDATA)> <!ELEMENT desc (#PCDATA)> <!ELEMENT type (desc, mime-type?)> <!ELEMENT mime-type (#PCDATA)> <!ELEMENT urn (#PCDATA)> 以下是一个基于上述媒体DTD的XML文档,描述了与某个课程讲座相关的内容: <?xml version="1.0" ?><!DOCTYPE media-asset PUBLIC "-//Jim Farley//DTD Media Assets//EN" "http://localhost/Articles/Sun/dtds/media.dtd"> <media-asset> <name>第14讲</name> <desc>与第14讲相关的所有内容</desc> <!-- 内容对象"lecture 14"的一套子组件 --> <media-asset> <name>讲座的幻灯片</name> <type> <desc>MS PowerPoint</desc> <mime-type>application/vnd.ms-powerpoint</mime-type> </type> <urn>http://javatraining.org/jaf/E123/lecture- 14/slides.ppt</urn> </media-asset> <media-asset> <name>讲座的视频片断</name> <type> <desc>RealPlayer streaming video</desc> <mime-type>video/vnd.rn-realvideo</mime-type> </type> <urn>http://javatraining.org/jaf/E123/lecture- 14/lecture.rv</urn> </media-asset> <!-- 讲座开始 --> <urn>http://javatraining.org/jaf/E123/lecture-14/index.jsp</urn> </media-asset> 从Web或者企业级应用的角度看,能以这种方式访问数据真是一种福音,因为它体现了高度的可移动性,使我们与元数据的实际资源本身隔离。这些资源可能来自一个关系数据库系统、某种活动媒体服务器或者Web服务器上的一个静态XML文档,等等。如果想把这些数据加载到Java应用中,我们可以从当前众多的Java语言XML解析器中选用一个,通过它将XML数据装入一个DOM文档,最后遍历文档,将所有这些数据转换到我们应用系统的对象模型中。 下面是个简单的基于DOM的解析程序,可对上述的媒体DTD进行解析。解析器用的是 Apache Xerces: package jaf.xml; import java.util.*; import java.io.IOException; import org.w3c.dom.*; import org.xml.sax.*; // XML文档解析程序,使用上述媒体DTD. public class MediaParser implements ErrorHandler { /** 使用Apache Xerces解析器 */ org.apache.xerces.parsers.DOMParser mParser = new org.apache.xerces.parsers.DOMParser(); /** 构造函数 */ public MediaParser() { // 告诉解析器验证并解析文档 try { mParser.setFeature( "http://xml.org/sax/features/validation", true); } catch (SAXException e) { System.out.println("Error setting validation on parser:"); e.printStackTrace(); } // 设置解析器的错误处理句柄 mParser.setErrorHandler(this); } /** 解析指定的URL,返回找到的XML文档 */ public Document parse(String url) throws SAXException, IOException { mParser.parse(url); Document mediaDoc = mParser.getDocument(); return mediaDoc; } /** 解析指定URL的XML文档,将内容转换成 MediaAsset 对象 */ public Collection loadAssets(String url) throws SAXException, IOException { Document doc = parse(url); Collection assets = new LinkedList(); NodeList assetNodes = doc.getElementsByTagName("media-asset"); for (int i = 0; i < assetNodes.getLength(); i++) { Node assetNode = assetNodes.item(i); MediaAsset asset = new MediaAsset(assetNode); assets.add(asset); } return assets; } /** * 错误处理代码(为简洁起见省略了) */ } MediaParser类的构造函数初始化了一个Xerces DOM解析器。parse()方法告诉解析器到哪个URL去找XML源,然后得到结果文档并返回。loadAssets()方法调用parse()方法从某个XML源加载文档,然后为文档中找到的每个“media-asset”节点创建一个MediaAsset对象。 以下是一个使用MediaAsset类的例子: package jaf.xml; import java.util.*; public class MediaAsset { // 资源元数据 private String mName = ""; private String mDesc = ""; private Collection mChildren = new LinkedList(); private Vector mTypes = new Vector(); private String mUrn = ""; protected MediaAsset(org.w3c.dom.Node assetNode) { // 为简洁起见省略后面代码 . . . } } 因为篇幅的关系省略了MediaAsset类的详细代码,但应用模式依然是清晰的。MediaAsset类遍历文档的节点,当它碰到不同的子节点时,它用子节点的内容填充自己的成员数据。如果它发现了一个嵌套的子资源节点,它只需要创建一个新的MediaAsset对象,然后将子资源节点的数据填充到新对象的成员数据中。 实现上述处理的方法数不胜数。我们还可以使用其他的解析器或解析器架构,如Java API for XML Parsing (JAXP)。除了使用DOM模型外,事件驱动的SAX模型也可用于解析XML。类似的程序也可用来产生XML数据——前提是允许产生新的数据对象(在本例中是MediaAsset),它可将其相应的XML实体插入到DOM中,然后将DOM输出到一个流中(诸如一个文件,一个Socket,或者一个HTTP连接...)。还有其他更高层次的标准,可将XML映射到Java对象的过程进一步自动化(或简化)。例如,使用XML概要(Schema)和XML绑定处理引擎,您可以半自动地将满足某个XML 概要的XML数据转变成Java数据对象。代表性的引擎是Castor,是由ExoLab小组管理的一个开放源代码项目的产物。上述使用Xerces DOM的简单例子仅仅是演示了这一处理过程的底层模型。 上述示例表明,在Java环境中解析或产生XML是非常方便的,这与J2EE没有必然关联。格式化为XML的数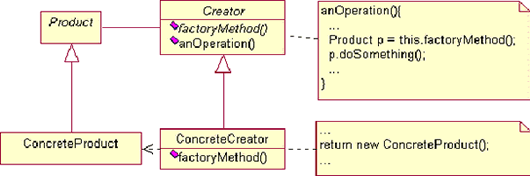



- 更多JSP疑问解答:
- jsp新手求指导,不要笑!
- 如何让一个form提取的值传递给多个jsp?
- DW中,新建的html页面能否有jsp或php代码?
- jsp 如何限制表单,实现只能填写特定的数据。
- jsp 和javabean结合的程序有问题
- 从数据库里取出的数据如何传递到另外的jsp页面中
- 你好,ext嵌入那个jsp页面,是不是还需要加上一些插件啊,不太懂,麻烦你了。
- JSP不能处理所有问题吗?还要来一大堆的TLD,TAG,XML。为JSP 非要 Servlet 不可吗?
- 光标离开时全角转半角在jsp中怎么实现
- jsp 页面 打开 pdf 文件 控制大小 和 工具栏 能发份源码么 谢啦
- jsp页面点保存按钮,运行缓慢,弹出对话框提示
- jsp刷新页面如何不闪屏
- jsp 与html 的交互问题?
- jsp小数显示问题 例如 我在oracle 数据库中查询出来的是 0.01 但是在jsp页面上就显示成 .01 没有前面的0
- jsp中日历控件