python爬虫和数据挖掘
考虑用python做爬虫,需要研究学习的python模块
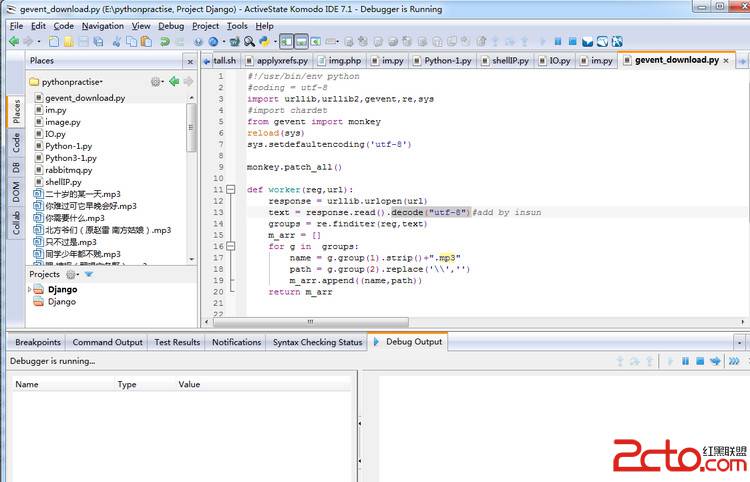
1内置的 urllib, urllib2 库用来爬取数据
2 使用BeautifulSoup做数据清洗
http://www.crummy.com/software/BeautifulSoup/
编码规则
Beautiful Soup tries the following encodings, in order of priority, to turn your document into Unicode:
1 An encoding you pass in as the fromEncoding argument to the soup constructor.
2 An encoding discovered in the document itself: for instance, in an XML declaration or (for HTML documents) an http-equiv META tag. If Beautiful Soup finds this kind of encoding within the document, it parses the document again from the beginning and gives the new encoding a try. The only exception is if you explicitly specified an encoding, and that encoding actually worked: then it will ignore any encoding it finds in the document.
3 An encoding sniffed by looking at the first few bytes of the file. If an encoding is detected at this stage, it will be one of the UTF-* encodings, EBCDIC, or ASCII.
4 An encoding sniffed by the chardet library, if you have it installed.
5 UTF-8
6 Windows-1252
可以用fromEncoding参数来构造BeautifulSoup
soup = BeautifulSoup(euc_jp, fromEncoding="gbk")
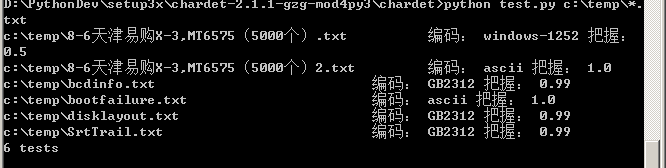
3 使用python chardet 字符编码判断
http://chardet.feedparser.org/download/
4 更加强大的 selenium
作者 张大鹏
补充:Web开发 , Python ,