Oracle百问百答(二)
Oracle百问百答(一)
http://www.zzzyk.com/database/201309/242497.html
11. nvl函数有什么用?
NVL( string1, replace_with)
功能:如果string1为NULL,则NVL函数返回replace_with的值,否则返回string1的值。
注意事项:string1和replace_with必须为同一数据类型,除非显式的使用TO_CHAR函数。
例:NVL(TO_CHAR(numeric_column), 'some string') 其中numeric_column代指某个数字类型的值。
12. 数据库名和数据库实例名有什么区别?
数据库名是用于区分数据库的一个内部标识,是以二进制方式存储在数据库控制文件中的参数。数据库创建之后不能再修改这个参数。数据库创建后,它被写入数据库参数文件pfile或Spfile中。格式如下:
db_name="orcl"
db_domain=dbcenter.toys.com
instance_name=orcl
service_names=orcl.dbcenter.toys.com
数据库实例是操作数据库的实体,用户通过实例与数据库交互。实例名用来标识这个数据库实例。数据库创建后,实例名可以被修改。也在数据库参数文件pfile或Spfile中。格式如下:
instance_name=orcl
service_names=orcl.dbcenter.toys.com
数据库名与实例名可以相同。一个数据库对应一个实例的情况下设置成相同的便于标识数据库。
13.简述profile的作用?
profile是口令限制,资源限制的命令集合,当建立数据库的,oracle会自动建立名称为default的profile。当建立用户没有指定profile选项,那么oracle就会将default分配给用户。
账户锁定:
概述:指定该账户(用户)登陆时最多可以输入密码的次数,也可以指定用户锁定的时间(天)一般用dba的身份去执行该命令。
例子:指定scott这个用户最多只能尝试3次登陆,锁定时间为2天,让我们看看怎么实现。
创建profile文件
SQL> create profile lock_account limit failed_login_attempts 3 password_lock_time 2;
SQL> alter user scott profile lock_account;
给账户解锁:
SQL> alter user tea lock_account unlock;
14.简述存储过程的用法?
创建:
create or replace procedure a_proc(a_name IN varchar2,a_num OUT number)
is
num_1 number;
num_2 number;
begin
select stu_id,age into num_1,num_2 from stuinfo
where stu_name=a_name;
a_num:=num_1*num_2;
end;
调用:
SQL> set serveroutput on
SQL> declare tname varchar(20);
2 tnum number;
3 begin
4 tname:='gggzz';
5 a_proc(tname,tnum);
6 dbms_output.put_line(tnum);
7 end;
8 /
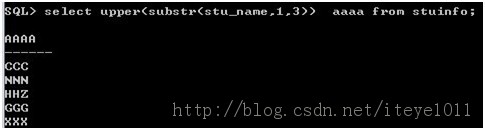
15.怎样以大写方式显示所有员工姓名的前3位字符?
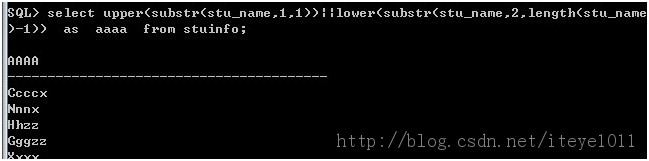
16.怎样以首字母大写后面小写的方式显示员工姓名?
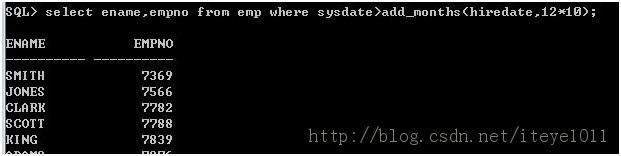
17.怎样显示满10年服务年限的员工的姓名和工号?
18.怎样显示入职日期在当月最后十天入职的员工姓名和工号?
19.cmd命令窗口有哪些常用快捷键?
↑ 返回上一个命令,↓返回下一个命令, →逐个字符返回上个命令
F8 逐个返回上一个命令,但光标处于第一个字符
F3 仅能返回上一个命令
F7 弹出命令历史记录窗口,结合↑↓按键选择命令,回车执行选中的命令。太长的命令可以使用→键在cmd窗口查看。home切换到第一个命令,end最后一个,PageDown、PageUp翻页查看。
F9 输入命令号码,该号码由F7中命令记录来定义。如果要多次执行某个命令,而且是长命令,可以使用该技巧。或许更有效率。
Alt+PrintScreen 对cmd窗口进行截图。
insert 使光标转换为插入状态,键入字符时可以替换光标当前字符。
20.表中重复的记录是怎样查询的?
a、查找表中多余的重复记录,重复记录是根据单个字段(peopleId)来判断
select * from people where peopleId in (select peopleId from people group by peopleId having count(peopleId) > 1)
b、删除表中多余的重复记录,重复记录是根据单个字段(peopleId)来判断,只留有rowid最小的记录
delete from people where peopleId in (select peopleId from people group by peopleId having count(peopleId) > 1)
and rowid not in (select min(rowid) from people group by peopleId having count(peopleId )>1)
c、查找表中多余的重复记录(多个字段)
select * from vitae awhere (a.peopleId,a.seq) in (select peopleId,seq from vitae
group by peopleId,seq having count(*) > 1)
d、删除表中多余的重复记录(多个字段),只留有rowid最小的记录
delete from vitae awhere (a.peopleId,a.seq) in (select peopleId,seq from vitae group by peopleId,seq having count(*) > 1)
and rowid not in (select min(rowid) from vitae group by peopleId,seq having count(*)>1)
e、查找表中多余的重复记录(多个字段),不包含rowid最小的记录
select * from vitae awhere (a.peopleId,a.seq) in (select peopleId,seq from vitae group by peopleId,seq having count(*) > 1)
and rowid not in (select min(rowid) from vitae group by peopleId,seq having count(*)>1)