MongoDB结构划分简述
MongoDB结构划分简述
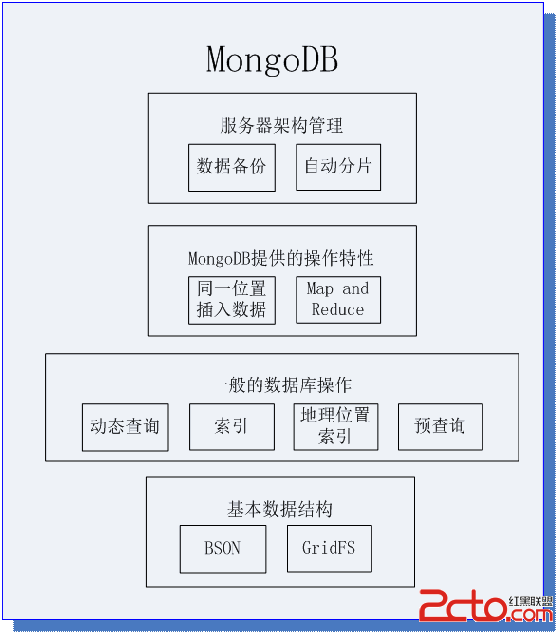
从整体上可以将MongoDB自底向上划分为四部分:
基础数据部分
一般的数据库操作
MongoDB提供的操作特性
数据库架构管理
二、 各部分简介
1. 基础数据部分
数据库最终的工作就是把数据存储,然后在用户需要的时候以一种方式把数据提出去。因此,所有数据都需要以一种形式保存到内存或者硬盘里。
在MongoDB里面主要有两种数据的存储方式。
BSON:类似于一个有序的JSON。是数据存储的基础,在MongoDB中的大部分数据都是用这种数据结构与用户交互。与一般数据库不同虽然MongoDB也是KV操作读取数据,但是用一Key对应的Value可以是不同类型。
GridFS:BSON只能存储最大4MB的数据,当需要存储大型数据的时候,就需要用GridFS来做存储了。
2. 一般数据库操作
作为数据库应该包含基本的增、删、改、查功能,并且提供加速基本操作的辅助工具,MongoDB同样也提供了这些基本功能。
动态查询:基本的增删改查功能。同时在做这些操作的时候MongoDB为这些操作自动优化,如:考虑可以利用的索引,直接从缓存中读取内容等等。
索引:在MongoDB中为每一条数据创建了一个_id的属性,作为最基本的索引。用户也可以自己创建一个索引来提高查询效率。MongoDB也提供了合并索引的功能,可以用来合并多关键词的索引。
地理位置索引:可以根据距离等位置相关属性来做索引。
预查询:在真正执行一条语句前,测试查询等基本操作的耗时,作为数据库设计或者语句效率的检测。
3. MongoDB提供的操作特性
同一位置插入数据:与其他数据库不同,MongoDB在真正将数据写入本地前,做了缓存处理,在内存中读写数据的速度比每次都写到本地的速度快多了。
Map and Reduce Function:MongoDB的特殊数据结构,决定了他可以有与众不同的特殊数据处理方式。编写这两个函数可以完成很多数据库本身没有提供的自定义功能。
4. 数据库架构管理
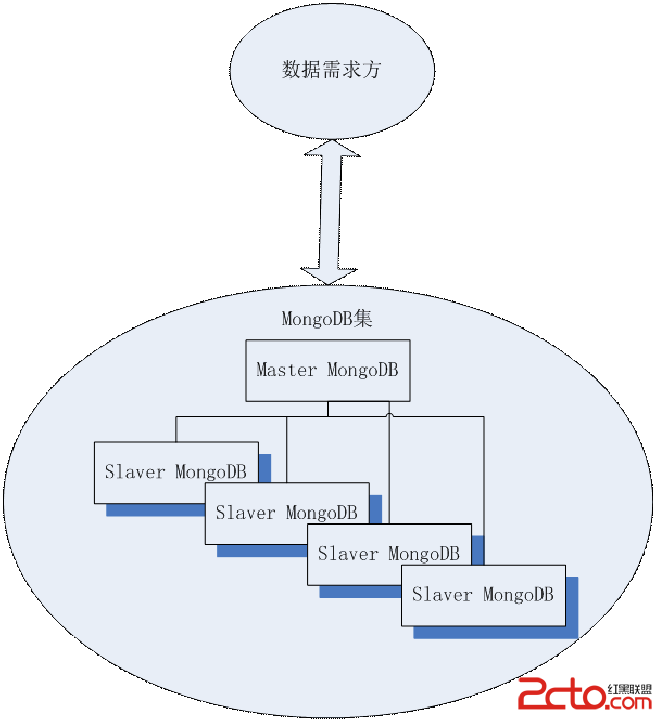
数据备份:由于MongoDB的实时读取性和内存中处理数据的特性,单个MongoDB数据库是很容易造成数据丢失的,为保证数据不丢失或少丢失(实际生产中会丢失),MongoDB提供了数据备份和选举运行主机的机制。(在实际生产中不能需要多台MongoDB服务器共同运行)下图简单描述了MongoDB的主从机关系。
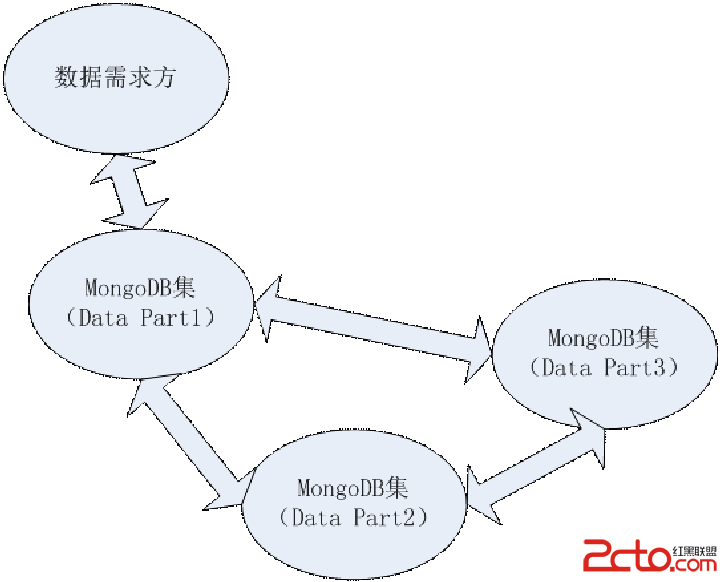
自动分片:在实际生产中,当数据量过大超过了一台MongoDB服务器所能支持的时候,需要考虑建立一个MongoDB的数据库集群,每一个集保存整体数据的某一部分。下图简单描述了一个MongoDBs集群的工作情况:
三、 源码阅读顺序及要点
了解了MongoDB的集群方式后,我觉得自底向上对MongoDB的源码进行阅读比较好。
原因:
1. 先了解基础的数据结构,对逻辑算法中出现的数据结构有所了解。
2. 算法与运行平台无关,集群等功能与运行平台有关。为了不过早的牵绊与系统功能,理解MongoDB的设计哲学之后对深层次功能的了解更有利。
3. 在生产优化中,底部的数据结构或者算法调整可能更容易产生效果。
因此,列出如下几点阅读顺序:
1. GridFS,BJSON
了解基本数据结构。
2. 基本搜索功能
了解对数据的基本处理,输入输出规则。
3. 索引,搜索优化
索引的创建和索引是如何提供其强大的辅助搜索功能的。
4. 数据备份
多台服务器的副本是如何保持同步的。
当主服务器宕机程序是如何选择副本服务器的。
当主服务器恢复后是以什么策略再次同步数据的。
5. 自动分片搜索
当创建完分片之后,MongoDB是如何处理多个服务器之间的数据跳转搜索的。