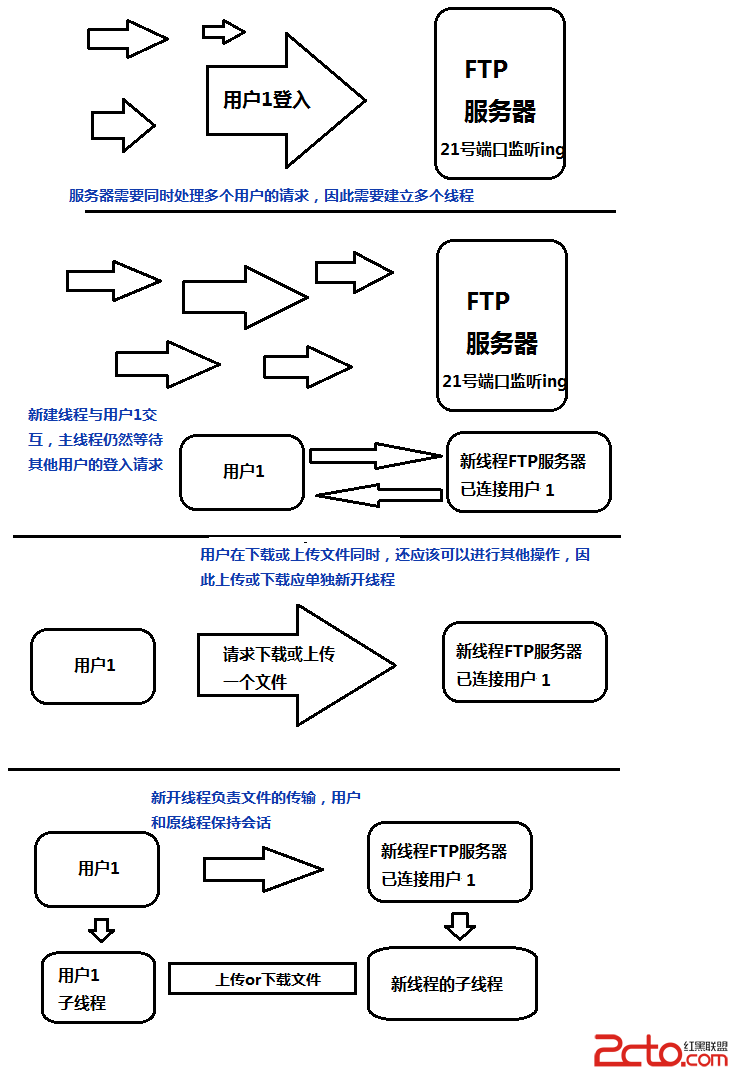
python webkit 异步抓取页面数据
cl
ass FetcherCartoon:[python] view plaincopyprint?def getCartoonUrl(self, url):
if url is None:
return false
#todo many decide about url
ghost = Ghost()
#open webkit
ghost.open(url)
#exceute javascript and get what you want
result, resources = ghost.evaluate("document.getElementById('cp_image').getAttribute('src');")
del resources
return result
def getCartoonUrl(self, url):
if url is None:
return false
#todo many decide about url
ghost = Ghost()
#open webkit
ghost.open(url)
#exceute javascript and get what you want
result, resources = ghost.evaluate("document.getElementById('cp_image').getAttribute('src');")
del resources
return result[python] view plaincopyprint?if __name__ == "__main__":
url = 'http://www.dm5.com/m136836-p3/'
result = None
fetcher = FetcherCartoon()
result = fetcher.getCartoonUrl(url)
print result
if __name__ == "__main__":
url = 'http://www.dm5.com/m136836-p3/'
result = None
fetcher = FetcherCartoon()
result = fetcher.getCartoonUrl(url)
print result
补充:Web开发 , Python ,