求助:正则表达式取网页中的网址
--------------------编程问答-------------------- string pattern="(?is)(?<=<a[^>]*?title=[""'])[^""']+(?=[""'])"; --------------------编程问答-------------------- 效果:
代码:
--------------------编程问答--------------------
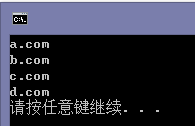
string txt = System.IO.File.ReadAllText("1.txt");
var vls = Regex.Matches(txt, "(?is)<a href=\".*?\".*?title=\"(.*?)\">.*?</a>").OfType<Match>().Select(x => x.Groups[1]);
foreach (var item in vls)
{
Console.WriteLine(item.Value);
}
Console.Read();
static class Program
{
static void Main()
{
string txt = @"
<a href=""a.com"" title=""a.com"">a</a>
<a title=""b.com"" href=""b.com"">b</a>
<a title=""c.com"" href=""c.com"">c</a>
<a id=""d123"" title=""d.com"" href=""d.com"">d</a>
";
foreach (Match match in Regex.Matches(txt, @"<a\s+(?:(?!title|</).)*title=""(?<title>[^""]*)"""))
Console.WriteLine(match.Groups["title"].Value);
}
}
QQ:406485989 --------------------编程问答--------------------
(?i)(?<=title=(['"]?))[^'"]+(?=\1)
补充:.NET技术 , C#