Oracle like '%...%'优化
Oracle like '%...%'优化
1。尽量不要使用 like '%%'
2。对于 like '%' (不以 % 开头),Oracle可以应用 colunm上的index
3。对于 like '%…' 的 (不以 % 结尾),可以利用reverse + function index 的形式,变化成 like '%'
4.非用like'%%'不可时,使用Oracle内部函数:INSTR()解决。
建测试表和Index,注意,重点在于带reverse的function index。同时,一定要使用CBO才行
create table test_like as select object_id,object_name from dba_objects;
-------建立测试表
create index test_like__name on test_like(object_name);
------建立索引
create index test_like__name_reverse on test_like(reverse(object_name));
------建立反向索引
易做图yze table test_like compute statistics for table for all indexes;
------对表进行分析
都过SQLPLUS连接到数据,一定是SQLPLUS,因为下面有写命令在PLSQL的命令行中不被支持;
set autotrace trace exp
-----设定SQL跟踪
set linesize 2000
-------设定输出宽度
select * from test_like where object_name like 'AS%';
使用了索引
select * from test_like where object_name like '%S';
未使用索引
select * from test_like where reverse(object_name)like reverse('%AS');
使用了索引
4.
在大表中,进行模糊查询,一般情况下是用LIKE'%%',但是这个东西走的是全表扫描,如果在数据量非常大的情况下,效率特别慢,因此,尝试用ORACLE函数INSTR()来解决。
实验步骤如下:
首先构造一张百万行的表。
SQL> insert into emp2 select * from emp2;
1032192 rows inserted
如上所示,构造完成
接下来连续运用多个LIKE查询来模糊匹配
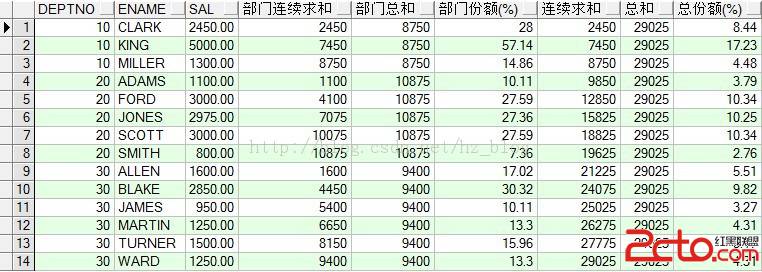
SQL> select * from emp2 where job like '%RE%' and ename like '%A%' and mgr like '%3%';
EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO
----- ---------- --------- ----- ----------- --------- --------- ------
Executed in 1.859 seconds
如上所示,LIKE查询一次,就走一次全表扫描,效率非常慢
同样的效果,现在来换做INSTR函数来执行
SQL> select * from emp where instr(job,'RE')>0 and instr(ename,'A')>0 and instr(mgr,'3')>0;
EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO
----- ---------- --------- ----- ----------- --------- --------- ------
Executed in 0.063 seconds
看到了吧,,时间上的差异很明显,INSTR在一瞬间执行完成,因为这个是查找的字段,而非走全表扫描
看来,oracle 内部函数效率还是高些。
因此,大家以后碰到同样的问题,除了全文检索外,这个也是个好方式
注意:
select id, name from users where instr(id, '101') > 0;
等价于
select id, name from users where id like '%101%'