sql 入门教程
sql 入门教程
1)from阶段
这个阶段是查询逻辑处理的第一步。想到这里,想起了linq表达式不就是从from开始的嘛,看来还是挺有道理的。from阶段负责表示表或要查询的表。如果指定了表运算符,还需 要按从左到右的顺序,对运算符进行逐个处理。表运算符有4类,join,apply,pivot,unpivot。每个表运算符都有自己的处理规则。这里挑最常见的join来说。
对于联接(join),一般有以下几个个步骤:
a.求笛卡尔积,对两张表进行cross join,得出最大的可能结果集。如果左表有n行,右表有m行,则结果集有nxm行。
b.利用on筛选条件来筛选,剔除不符合条件的行。
c.对于外联接(left,right,full outer join),还需要添加外部行。在上个步骤中,on条件剔除掉了所有不匹配两张表的行。但是在外联接中,通过指定外连接的类型,需要将其中的一个或者两个表标记为保留表,并返回该表中所有的行。所以这时候还需要将保留表中被on筛选条件剔除的行重新加入到结果集中(这些重新加进来的表,书中称为外部行),并将外部行中非保留表的列值标记为null.再次提醒一下,这一个步骤,只有外联接才执行,对于内联接(inner join)只需要执行a和b两个步骤的。
(2)where阶段
对于上一步骤返回的虚拟表,经过where条件的判定,只有让where条件为true的行才会被保留下来。请注意,因为还没有对数据进行分组,所以在where子句中不能聚合。也不能引用select列表中创建的别名,因为select阶段还在后头呢。例如where orderid>max(orderid), select year(thedate) as theyear... where theyear>2010是不能使用的。
另外一个很让人迷惑的问题是,对于包含join的查询,到底on和where子句有什么区别,应该什么时候使用on子句,什么时候使用where子句。这里作一下说明。只有对于外联接,on和where子句才会存在这种逻辑区别,因为在外联接中,通过on子句的筛选之后,还要对保留表进行外部行添加,而where子句则是在外部行添加过之后才进行筛选的。因此,on子句对这种外联接的情况的筛选,并不是最终的结果,在from阶段的第三个步骤,还会把外部行添加回来的。而对于内联接,where子句和on子句作用是完全一样的,在哪里筛选都是同种效果,没有其他步骤。所以在处理这种含有外联接的查询,一定要注意on筛选和where筛选的区别,避免使用错了,达不到筛选的效果。另外,对于内联接,一个不错的建议是,对于两个表都存在的字段筛选,用on子句,对于单个表的字段筛选,用where,例如:select * from a inner join b on a.col = b.col where a.col2 >1。
(3)group by阶段
在这一阶段将上一步返回的虚拟表中的结果集按分组进行重组,由分组集所有列的每个唯一组合,标识出一个组。再用这些组,跟上一步返回的每一个行进行关系。注意,每个行只能关联一个组。最后,生成的结果集中,每个组只能有一行。关于group by还有很多有意思的地方,比如cube,rollup,grouping等等,有时间再一一介绍。
(4)having阶段
having筛选器用于对上一步返回的结果集进行筛选。having筛选器是唯一能筛选分组数据的筛选器,on和where都不行。理由很简单,on和where都是在分组之前进行处理的,自然不能对分组进行筛选。所以having和where的区别,也是很显而易见了。having 只能与 select 语句一起使用。having 通常在 group by 子句中使用。如果不使用 group by 子句,则 having 的行为与 where 子句一样。
(5)select阶段
这一个步骤,将构造最终返回给调用者的表。这个步骤涉及到3个子阶段。
a.计算表达式。在这个阶段中,select列表可以返回油上一步得到的虚拟表的基础列,也可以是对这些基础列的操作。有一点需要注意的是,在这个select列表中,所有的表达式是同时计算的。举个例子,在sql中,可以这么交换两个列值:update tab_test set col1 = col2,col2 =col1;在别的语言看来这的确很神奇。
而且在select列表中创建的别名不能在同一select列表中的其他表达式中使用。所以,基于这个特性,我们就会得出一个结论,select列表的顺序是无关紧要的。
b.处理dinstinct,如果查询中指定了dinstinct,则从上一步返回的虚拟表中删除重复的行。
c.应用top选项。对于指定了top选项的查询,则会根据查询的order by子句来选择指定数量的行。top选项里有很多特殊的地方,此处先不扯远,以后有机会单独讲。
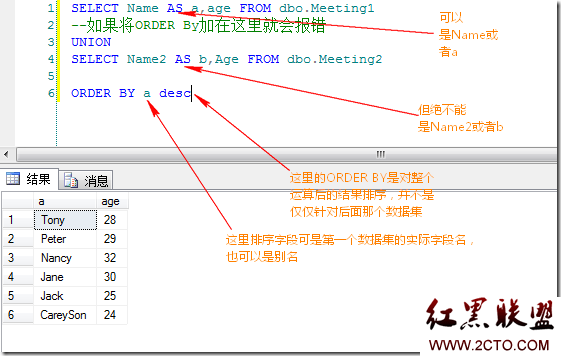
(6)order by阶段
这一步按照order by列表中的列明对上一步的表进行排序,返回游标。
这里有必要谈一下集合和游标。sql的理论基础是集合,集合是无序的,它只是成员的一种逻辑集合。对于带有排序作用的order by子句的查询,可以返回一个对象,其中的行按照特定的顺序组织在一起。ansi把这种 对象成为游标(cursor)。
因为在这一步中,最后返回的是游标,所以带有order by的查询,是不能用来定义视图,子查询,公用表等。例如:
select * from (select col1,col2 from tab_test order by col1)是无效的,并且将报错。
但是如果同时指定了top选项,则是一个例外。select * from (select top (10) col1,col2 from tab_test order by col1),对于这个查询,因为同时指定了top和order by,则子查询中的结果一定是固定而且有序的的,但是外部的查询,则不能保证是有序排列的。
补充:数据库,Mssql