C++使用Uniscribe进行文字自动换行的计算和渲染
在使用Uniscribe之前,我们先看看利用Uniscribe我们可以做到什么样的效果:
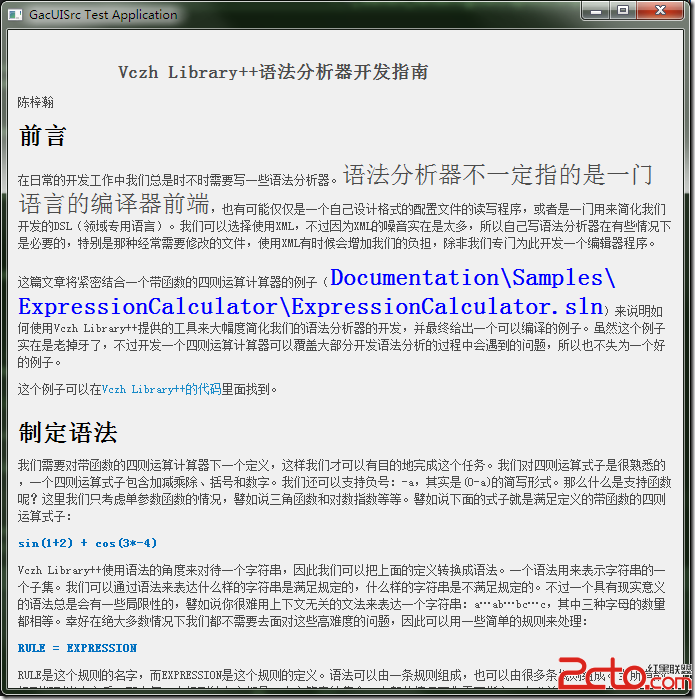
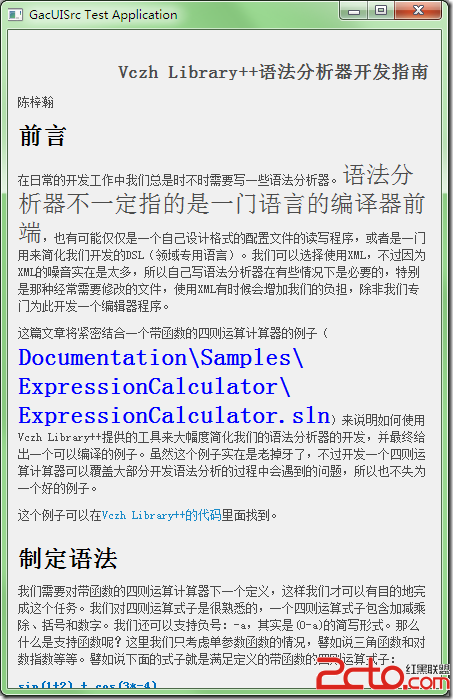
通过Uniscribe,我们可以获得把各种不同大小的字符串混合在一起渲染的时候所需要的所有数据,甚至可以再漂亮的地方换行,譬如说这里:

当然,渲染的部分不包含在Uniscribe里面,只不过Uniscribe告诉我们的信息可以让我们直接计算出渲染每一小段字符串的位置。当然,这也就足够了。下面我来介绍一下Uniscribe的几个函数的作用。
首先,我们需要注意的是,Uniscribe一次只处理一行字符串。我们固然可以把多行字符串一次性丢给Uniscribe进行计算,但是得到的结果处理起来要困难得多。所以我们一次只给Uniscribe一行的字符串。现在我们需要渲染一个带有多种格式的一行字符串。首先我们需要知道这些字符串可以被分为多少段。这在那些从右到左阅读的文字(譬如说易做图文)特别重要,而且这也是一个特别复杂的话题,在这里我就不讲了,我们假设我们只处理从左到右的字符串。
于是我们第一个遇到的函数就是ScriptItemize。
HRESULT ScriptItemize(
_In_ const WCHAR *pwcInChars,
_In_ int cInChars,
_In_ int cMaxItems,
_In_opt_ const SCRIPT_CONTROL *psControl,
_In_opt_ const SCRIPT_STATE *psState,
_Out_ SCRIPT_ITEM *pItems,
_Out_ int *pcItems
);
由于我们不处理从右到左的字符串渲染,也不处理把数字变成乱七八糟格式的效果(譬如在某些易做图的帝国主义国家12345被表达成12,345),因此这个函数的psControl和psState参数我们都可以给NULL。这个时候我们需要首先为SCRIPT_ITEM数组分配空间。由于一个字符串的item最多就是字符数量那么多个,所以我们要先创建一个cInChars+1那么长的SCRIPT_ITEM数组。在调用了这个函数之后,*pcItems+1的结果就是pItems里面的有效长度了。为什么pItems的长度总是要+1呢?因为SCRIPT_ITEM里面有一个很有用的成员叫做iCharPos,这个成员告诉我们这个item是从字符串的什么地方开始的。那长度呢?自然是用下一个SCRIPT_ITEM的cCharPos去剪了。那么最后一个item怎么办呢?所以ScriptItemize给了我们额外的一个结尾item,让我们总是可以方便的这么减……特别的蛋疼……
好了,现在我们把一行字符串分成了各个item。现在第一个问题就来了,一行字符串里面可能有各种不同的字体的样式,接下来怎么办呢?我们要同时用item的边界和样式的边界来切割这个字符串,让每一个字符串的片段都完全被某个item包含,并且片段的所有字符都有一样的样式。这听起来好像很复杂,我来举个例子:
譬如我们有一个字符串长成下面这个样子:
This parameter (foo) is optional
然后ScriptItemize告诉我们这个字符串一共分为3个片段(这个划分当然是我胡扯的,我只是举个例子):
This parameter
(foo)
is optional
所以,字体的样式和ScriptItemize的结果就把这个字符串分成了下面的五段:
This
parameter
(foo)
is
optional
是不是听起来很直观呢?但是代码写起来还是比较麻烦的,不过其实说麻烦也不麻烦,只需要大约十行左右就可以搞定了。在MSDN里面,这五段的“段”叫做“run”或者是“range”。www.zzzyk.com
现在,我们拿起一个run,送进一个叫做ScriptShape的函数里面:
HRESULT ScriptShape(
_In_ HDC hdc,
_Inout_ SCRIPT_CACHE *psc,
_In_ const WCHAR *pwcChars,
_In_ int cChars,
_In_ int cMaxGlyphs,
_Inout_ SCRIPT_ANALYSIS *psa,
_Out_ WORD *pwOutGlyphs,
_Out_ WORD *pwLogClust,
_Out_ SCRIPT_VISATTR *psva,
_Out_ int *pcGlyphs
);
这个函数可以告诉我们,这一堆wchar_t可以被如何分割成glyph。这里我们要注意的是,glyph的数量和wchar_t的数量并不相同。所以在调用这个函数的时候,我们要先猜一个长度来分配空间。MSDN告诉我们,我们可以先让cMaxGlyphs = cChars*1.5 + 16。
在上面的参数里,SCRIPT_ANALYSIS其实就是SCRIPT_ITEM::a。由于一个run肯定是完整的属于一个item的,因此SCRIPT_ITEM就可以直接从上一个函数的结果获得了。然后这个函数告诉我们三个信息:
1、pwOutGlyphs:这个字符串一共有多少glyph组成。
2、psva:每一个glyph的属性是什么。
3、pwLogClust:wchar_t(术语叫unicode code point)是如何跟glyph对应起来的。
在这里解释一下glyph是什么意思。glyph其实就是字体里面的一个“图”。一个看起来像一个字符的东西,有可能由多个glyph组成,譬如说“á”,其实就占用了两个wchar_t,同时这两个wchar_t具有两个glyph(a和上面的小点)。而且这两个wchar_t在渲染的时候必须被渲染在一起,因此他们至少应该属于同一个range,鼠标在文本框选中的时候,这两个wchar_t必须作为一个整体(后面这些信息可以由ScriptBreak函数给出)。当然还有1个wchar_t对多个glyph的情况,但是我现在一下子找不到。
不仅如此,还有两个wchar_t对一个glyph的情况,譬如说这些字“㦲 ”。虽然wchar_t的范围是0到65536,但这并不代表utf-16只有6万多个字符(实际上是60多万),所以wchar_t其实也是变长的。但是utf-16的编码设计的很好,当我们拿到一个wchar_t的时候,我们通过阅读他们的数字就可以知道这个wchar_t是只有一个code point的、还是那些两个code point的字的第一个或者是第二个,跟我们以前遇到的MBCS(char/ANSI)完全不同。
因此wchar_t和glyph的对应关系很复杂,可能是一对多、多对一、一对一或者多对多。所以pwLogClust这个数组就特别的重要。MSDN里面有一个例子:
譬如说我们的一个7个wchar_t的字符串被分成4组glyph,对应关系如下:
字符:| c1u1 | c2u1 | c3u1 c3u2 c3u3 | c4u1 c4u2 |
图案:| c1g1 | c2g1 c2g2 c2g3 | c3g1 | c4g1 c4g2 c4g3 |
上面的意思是,第二个字符c2u2被渲染成了3个glyph:c2g1、c2g2和c2g3,而c3u1、c3u2和c3u3三个字符责备合并成了一个glyph:c3g1。这种情况下,pwLogClust[cChars]的内容就是下面这个样子的:
| 0 | 1 | 4 4 4 | 5 5 |
连续的数字相同的几个clust说明这些wchar_t是被归到一起的,而且这一组wchar_t的第一个glyph的的序号就是pwLogClust的内容了。那么这一组wchar_t究竟有多少个glyph呢?当然就要看下一组wchar_t的第一个glyph在哪了。
为什么我们需要这些信息呢?因为字符串的长度是按照glyph的长度来计算的!而且接下来我们要介绍的函数ScriptPlace会真的给我们每一个glyph的长度。因此我们在计算换行的时候,我们只能在每一组glyph并且ScriptBreak告诉我们可以换行的那个地方换行,所以当我们拿出一段完整的不会被换行的一个run的子集的时候,我们要在渲染的时候计算长度,就要特别小心glyph和wchar_t的对应关系。因为我们渲染的是一串wchar_t,但是我们的长度是按照glyph计算的,这个对应关系要是乱掉了,要么计算出错,要么渲染的字符选错,总之是很麻烦的。那么ScriptPlace究竟长什么样子呢:
HRESULT ScriptPlace(
_In_ HDC hdc,
_Inout_ SCRIPT_CACHE *psc,
_In_ const WORD *pwGlyphs,
_In_ int cGlyphs,
_In_ const SCRIPT_VISATTR *psva,
_Inout_ SCRIPT_ANALYSIS *psa,
_Out_ int *piAdvance,
_Out_ GOFFSET *pGoffset,
_Out_ ABC *pABC
);
这就是那个传说中的帮我们计算glyph大小的函数了。其中pwGlyphs就是我们刚刚从ScriptShape函数拿到的pwOutGlyphs,而psa还是那个psa,psva也还是那个psva。接下来的piAdvance数组告诉我们每一个glyph的长度,pGoffset这个是每一个glyph的偏移量(还记得“á”上面的那个小点吗),pABC是整一个run的长度。至于ABC的三个长度我们并不用管,因为我们需要的是pABC里面三个长度的和。而且这个和跟piAdvance的所有数字加起来一样。
现在我们拿到了所有glyph的尺寸信息,和他们的分组情况,最后就是知道字符串的一些属性了,譬如说在哪里可以换行。为什么要知道这些呢?譬如说我们有一个字符串叫做
c:\ThisIsAFolder\ThisIsAFile.txt
然后我们渲染字符串的位置可以容纳下“c:\ThisIsAFolder\”,却不能容纳完整的“c:\ThisIsAFolder\ThisIsAFile”。这个时候,ScriptBreak函数就可以告诉我们,一个优美的换行可以在斜杠“\”的后面产生。让我们来看看这个ScriptBreak
补充:软件开发 , C++ ,