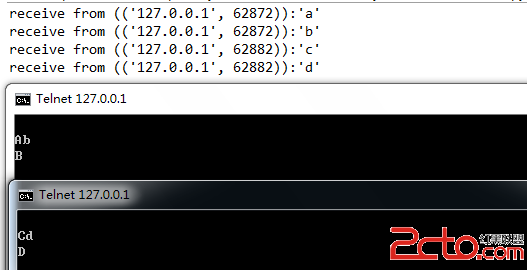
python 爬取指定url的ICP备案信息(结构化抓取)
[python]
#coding=gbk
import os
import sys
import re
import time
import urllib2
def perror_and_exit(message, status = -1):
sys.stderr.write(message + '\n')
sys.exit(status)
def get_text_from_html_tag(html):
pattern_text = re.compile(r">.*? return pattern_text.findall(html)[0][1:-2].strip()
def parse_alexa(url):
url_alexa = "http://icp.alexa.cn/index.php?q=%s" % url
print url_alexa
#handle exception
times = 0
while times < 5000: #等待有一定次数限制
try:
alexa = urllib2.urlopen(url_alexa).read()
pattern_table = re.compile(r"
match_table = pattern_table.search(alexa)
if not match_table:
raise BaseException("No table in HTML")
break
except:
print "try %s times:sleep %s seconds" % (times, 2**times)
times += 1
time.sleep(2**times)
continue
table = match_table.group()
pattern_tr = re.compile(r"
match_tr = pattern_tr.findall(table)
if len(match_tr) != 2:
perror_and_exit("table format is incorrect")
icp_tr = match_tr[1]
pattern_td = re.compile(r"
match_td = pattern_td.findall(icp_tr)
#print match_td
company_name = get_text_from_html_tag(match_td[1])
company_properties = get_text_from_html_tag(match_td[2])
company_icp = get_text_from_html_tag(match_td[3])
company_icp = company_icp[company_icp.find(">") + 1:]
company_website_name = get_text_from_html_tag(match_td[4])
company_website_home_page = get_text_from_html_tag(match_td[5])
company_website_home_page = company_website_home_page[company_website_home_page.rfind(">") + 1:]
company_detail_url = get_text_from_html_tag(match_td[7])
pattern_href = re.compile(r"href=\".*?\"", re.DOTALL | re.MULTILINE)
match_href = pattern_href.findall(company_detail_url)
if len(match_href) == 0:
company_detail_url = ""
else:
company_detail_url = match_href[0][len("href=\""):-1]
return [url, company_name, company_properties, company_icp, company_website_name, company_website_home_page, company_detail_url]
pass
if __name__ == "__main__":
fw = file("out.txt", "w")
for url in sys.stdin:
fw.write("\t".join(parse_alexa(url)) + "\n")
#coding=gbk
import os
import sys
import re
import time
import urllib2
def perror_and_exit(message, status = -1):
sys.stderr.write(message + '\n')
sys.exit(status)
def get_text_from_html_tag(html):
pattern_text = re.compile(r">.*? return pattern_text.findall(html)[0][1:-2].strip()
def parse_alexa(url):
url_alexa = "http://icp.alexa.cn/index.php?q=%s" % url
print url_alexa
#handle exception
times = 0
while times < 5000: #等待有一定次数限制
try:
alexa = urllib2.urlopen(url_alexa).read()
pattern_table = re.compile(r"
match_table = pattern_table.search(alexa)
if not match_table:
raise BaseException("No table in HTML")
break
except:
print "try %s times:sleep %s seconds" % (times, 2**times)
times += 1
time.sleep(2**times)
continue
table = match_table.group()
pattern_tr = re.compile(r"
match_tr = pattern_tr.findall(table)
if len(match_tr) != 2:
perror_and_exit("table format is incorrect")
icp_tr = match_tr[1]
pattern_td = re.compile(r"
match_td = pattern_td.findall(icp_tr)
#print match_td
company_name = get_text_from_html_tag(match_td[1])
company_properties = get_text_from_html_tag(match_td[2])
company_icp = get_text_from_html_tag(match_td[3])
company_icp = company_icp[company_icp.find(">") + 1:]
company_website_name = get_text_from_html_tag(match_td[4])
company_website_home_page = ge补充:Web开发 , Python ,