Hibernate4实战 之 第三部分:Hibernate的基本开发
1:瞬时(Transient) - 由new操作符创建,且尚未与Hibernate Session 关联的对象被认定为瞬时的。瞬时对象不会被持久化到数据库中,也不会被赋予持久化标识(identifier)。 如果瞬时对象在程序中没有被引用,它会被垃圾回收器销毁。 使用Hibernate Session可以将其变为持久状态,Hibernate会自动执行必要的SQL语句。2:持久(Persistent) - 持久的实例在数据库中有对应的记录,并拥有一个持久化标识。 持久的实例可能是刚被保存的,或刚被加载的,无论哪一种,按定义,它存在于相关联的Session作用范围内。 Hibernate会检测到处于持久状态的对象的任何改动,在当前操作单元执行完毕时将对象数据与数据库同步。开发者不需要手动执行UPDATE。将对象从持久状态变成瞬时状态同样也不需要手动执行DELETE语句。
3:脱管(Detached) - 与持久对象关联的Session被关闭后,对象就变为脱管的。 对脱管对象的引用依然有效,对象可继续被修改。脱管对象如果重新关联到某个新的Session上, 会再次转变为持久的,在脱管期间的改动将被持久化到数据库。
通过Session接口来操作Hibernate
新增——save方法、persist方法
1:persist() 使一个临时实例持久化。然而,它不保证立即把标识符值分配给持久性实例,这会发生在flush的时候。persist() 也保证它在事务边界外调用时不会执行INSERT 语句。这对于长期运行的带有扩展会话/持久化上下文的会话是很有用的。
2:save() 保证返回一个标识符。如果需要运行INSERT 来获取标识符(如"identity" 而非"sequence" 生成器),这个INSERT 将立即执行,不管你是否在事务内部还是外部。这对于长期运行的带有扩展会话/持久化上下文的会话来说会出现问题。
删除——delete方法
修改——有四种方法来做,分别是:
1:直接在Session打开的时候load对象,然后修改这个持久对象,在事务提交的时候,会自动flush到数据库中。
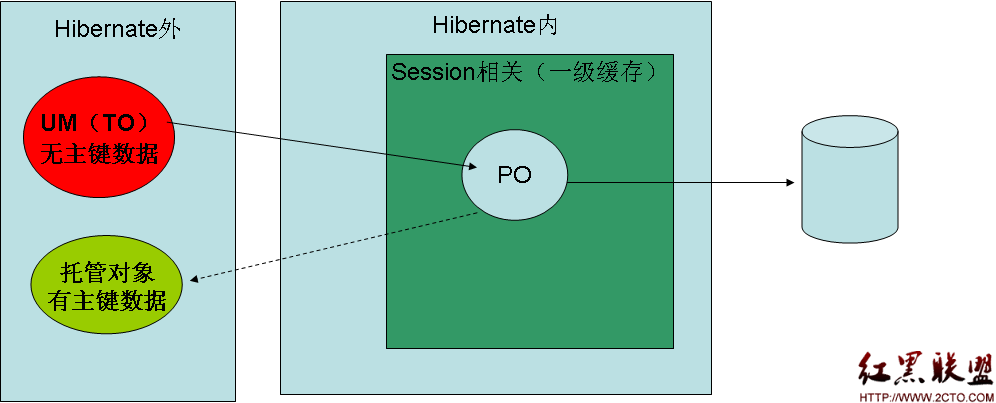
2:修改托管对象,可用update或merge方法
3:自动状态检测:saveOrUpdate方法
update和merge方法
1:如果数据库里面存在你要修改的记录,update每次是直接执行修改语句;而merge是先在缓存中查找,缓存中没有相应数据,就到数据库去查询,然后再合并数据,如果数据是一样的,那么merge方法不会去做修改,如果数据有不一样的地方,merge才真正修改数据库。
2:如果数据库中不存在你要修改的记录,update是报错;而merge方法是当作一条新增的值,向数据库中新增一条数据。
3:update后,传入的TO对象就是PO的了,而merge还是TO的。
4:如果你确定当前session没有包含与之具有相同持久化标识的持久实例,使用update()。如果想随时合并改动而不考虑session的状态,使用merge()。换句话说,在一个新session中通常第一个调用的是update()方法,以保证重新关联脱管对象的操作首先被执行。
5:请注意:使用update来把一个TO变成PO,那么不管是否修改了对象,都是要执行update sql语句的。
通常下面的场景会使用 update() 或 saveOrUpdate()
1:程序在第一个 session 中加载对象
2:该对象被传递到表现层
3:对象发生了一些改动
4:该对象被返回到业务逻辑层
5:程序调用第二个session的update()方法持久这些改动
saveOrUpdate方法做下面的事:
1:如果对象已经在本session中持久化了,不做任何事
2:如果另一个与本session关联的对象拥有相同的持久化标识,抛出一个异常
3:如果对象没有持久化标识属性,对其调用 save()
4:如果对象的持久标识表明其是一个新实例化的对象,对其调用 save()。
5:如果对象是附带版本信息的(通过 <version> 或 <timestamp>)并且版本属性的值表明其是一个新实例化的对象,save() 它。
6:否则update()这个对象
merge做如下的事情
1:如果session中存在相同持久化标识的实例,用用户给出的对象的状态覆盖旧有的持久实例
2:如果session中没有相应的持久实例,则尝试从数据库中加载,或创建新的持久化实例
3:最后返回该持久实例
4:用户给出的这个对象没有被关联到 session 上,它依旧是脱管的
按主键查询
1:load方法:load的时候首先查询一级缓存,没有就创建并返回一个代理对象,等到使用的时候,才查二级缓存,如果二级缓存中没有数据就查数据库,如果数据库中没有,就抛例外
2:get方法:先查缓存,如果缓存中没有这条具体的数据,就查数据库,如果数据库没有值,就返回null,总之get方法不管用不用,都要拿到真实的数据
Hibernate实现按条件查询的方式
1:最重要的按条件查询的方法是使用Query接口,使用HQL
2:本地查询(native sql):就是使用标准的sql,也是通过Query接口来实现
3:按条件查询(Query By Criteria,QBC):使用动态的,面向对象的方式来创建查询
4:按样例查询(Query By Example,简写QBE):类似我们自己写的getByCondition
5:命名查询:在hbm.xml中配置hql语句,在程序里面通过名称来创建Query接口
Query的list方法
一个查询通常在调用 list() 时被执行,执行结果会完全装载进内存中的一个集合,查询返回的对象处于持久状态。如果你知道的查询只会返回一个对象,可使用 list() 的快捷方式 uniqueResult()。
Iterator和List
某些情况下,你可以使用iterate()方法得到更好的性能。 这通常是你预期返回的结果在session,或二级缓存(second-level cache)中已经存在时的情况。 如若不然,iterate()会比list()慢,而且可能简单查询也需要进行多次数据库访问: iterate()会首先使用1条语句得到所有对象的持久化标识(identifiers),再根据持久化标识执行n条附加的select语句实例化实际的对象。
外置命名查询
可以在映射文件中定义命名查询(named queries)。
java代码:
1. <query name="javass">
2. <![CDATA[select Object(o) from UserModel o]]>
3. </query>
参数绑定及执行以编程方式完成:
List list = s.getNamedQuery("cn.javass.h3.hello.UserModel.javass").list();
注意要用全限定名加名称的方式进行访问
flush方法
每间隔一段时间,Session会执行一些必需的SQL语句来把内存中对象的状态同步到JDBC连接中。这个过程被称为刷出(flush),默认会在下面的时间点执行:
1:在某些查询执行之前
2:在调用org.hibernate.Transaction.commit()的时候
3:在调用Session.flush()的时候
涉及的 SQL 语句会按照下面的顺序发出执行:
1. 所有对实体进行插入的语句,其顺序按照对象执行save() 的时间顺序
2. 所有对实体进行更新的语句
3. 所有进行集合删除的语句
4. 所有对集合元素进行删除,更新或者插入的语句
5. 所有进行集合插入的语句
6. 所有对实体进行删除的语句,其顺序按照对象执行 delete() 的时间顺序
除非你明确地发出了flush()指令,关于Session何时会执行这些JDBC调用是完全无法保证的,只能保证它们执行的前后顺序。 当然,Hibernate保证,Query.list(..)绝对不会返回已经失效的数据,也不会返回错误数据。
lock方法:也允许程序重新关联某个对象到一个新 session 上。不过,该脱管对象必须是没有修改过的。示例如:s.lock(um, LockMode.READ);
注意:lock主要还是用在事务处理上,关联对象只是一个附带的功能
获取元数据
Hibernate 提供了ClassMetadata接口和Type来访问元数据。示例如下:
java代码:
查看复制到剪贴板打印
1. ClassMetadata catMeta = sf.getClassMetadata(UserModel.class);
2. String[] propertyNames = catMeta.getPropertyNames();
3. Type[] propertyTypes = catMeta.getPropertyTypes();
4. for (int i = 0; i < propertyNames.length; i++) {
5. System.out.println("name=="+propertyNames[i] + ", type==“
6. +propertyTypes[i]);
7. }
8.
HQL介绍
Hibernate配备了一种非常强大的查询语言,这种语言看上去很像SQL。但是不
要被语法结构 上的相似所迷惑,HQL是非常有意识的被设计为完全面向对象的查
询,它可以理解如继承、多态 和关联之类的概念。
看个示例,看看sql和HQL的相同与不同:
Sql:select * from tbl_user where uuid=‘123’
HQL:select Object(o) from UserModel o where o.uuid=‘123’
HQL特点
1:HQL对Java类和属性是大小写敏感的,对其他不是大小写敏感的。
2:基本上sql和HQL是可以转换的,因为按照Hibernate的实现原理,最终运行的还是sql,只不过是自动生成的而已。
3:HQL支持内连接和外连接
4:HQL支持使用聚集函数,如:c
补充:软件开发 , Java ,