解决Heritrix镜像方式存储路径中文乱码的解决方案
在解决此问题前先看看为何会出现乱码。
以中国文物网为例,下面的一个路径下有图片,如下
http://www.wenwuchina.com/uploads/conew_刘亚东老师现场弹奏《潇湘水云》_conew1.jpg
,当在浏览器输入该地址时,浏览器会将其编码为如下地址
http://www.wenwuchina.com/uploads/conew_%E5%88%98%E4%BA%9A%E4%B8%9C%E8%80%81%E5%B8%88%E7%8E%B0%E5%9C%BA%E5%BC%B9%E5%A5%8F%E3%80%8A%E6%BD%87%E6%B9%98%E6%B0%B4%E4%BA%91%E3%80%8B_conew1.jpg。
红色部分就是浏览器对中文进行编码后的路径。
Heritrix就是以此路径来访问该资源的,当以镜像方式存储下载的资源时,最终就会以conew_%E5%88%98%E4%BA%9A%E4%B8%9C%E8%80%81%E5%B8%88%E7%8E%B0%E5%9C%BA%E5%BC%B9%E5%A5%8F%E3%80%8A%E6%BD%87%E6%B9%98%E6%B0%B4%E4%BA%91%E3%80%8B_conew1.jpg的文件名来存储该资源,就产生的所谓的乱码。
解决方案就是在其创建路径时对路径名进行编码,主要代码在org.archive.crawler.writer. MirrorWriterProcessor类下的方法LumpyString方法。
为了尊重源码,我没有对原来的方法进行改动,新建了org.archive.crawler.writer. MirrorWriterForWenwuchinaProcessor类,来对heritrix进行扩展。复制了org.archive.crawler.writer. MirrorWriterProcessor类中所有代码,并对LumpyString进行必要的改动。如下(红色为修改的部分)
| 代码如下 |
复制代码 |
|
LumpyString(String str, int beginIndex, int endIndex, int padding,
int maxLen, Map characterMap, String dotBegin) {
if (beginIndex < 0) {
throw new IllegalArgumentException("beginIndex < 0: "
+ beginIndex);
}
if (endIndex < beginIndex) {
throw new IllegalArgumentException("endIndex < beginIndex "
+ "beginIndex: " + beginIndex + "endIndex: " + endIndex);
}
if (padding < 0) {
throw new IllegalArgumentException("padding < 0: " + padding);
}
if (maxLen < 1) {
throw new IllegalArgumentException("maxLen < 1: " + maxLen);
}
if (null == characterMap) {
throw new IllegalArgumentException("characterMap null");
}
if ((null != dotBegin) && (0 == dotBegin.length())) {
throw new IllegalArgumentException("dotBegin empty");
}
// Initial capacity. Leave some room for %XX lumps.
// Guaranteed positive.
int cap = Math.min(2 * (endIndex - beginIndex) + padding + 1,
maxLen);
string = new StringBuffer(cap);
aux = new byte[cap];
for (int i = beginIndex; i != endIndex; ++i) {
String s=str.substring(i, i + 1);
try {
s = new String(s.getBytes(),"GB2312");
} catch (UnsupportedEncodingException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
String lump; // Next lump.
if (".".equals(s) && (i == beginIndex) && (null != dotBegin)) {
lump = dotBegin;
} else {
lump = (String) characterMap.get(s);
}
if (null == lump) {
if ("%".equals(s) && ((endIndex - i) > 2)
&& (-1 != Character.digit(str.charAt(i + 1), 16))
&& (-1 != Character.digit(str.charAt(i + 2), 16))) {
// %XX escape; treat as one lump.
lump = str.substring(i, i + 3);
i += 2;
} else {
lump = s;
}
}
if ((string.length() + lump.length()) > maxLen) {
assert checkInvariants();
return;
}
append(lump);
}
assert checkInvariants();
}
然后在
|
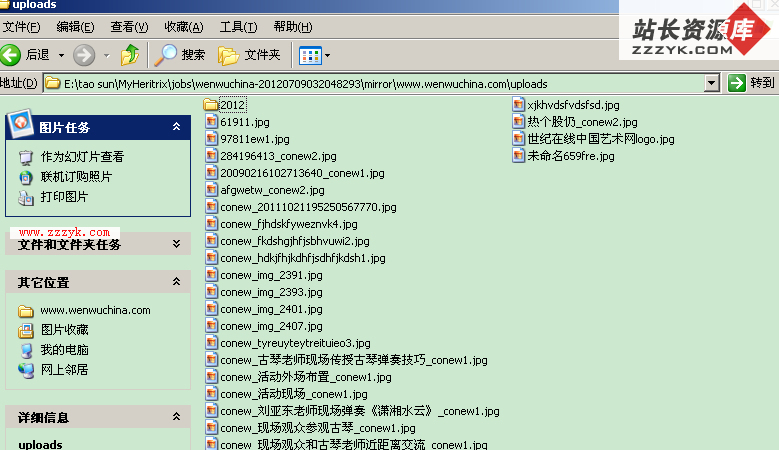
Processor.options里加入org.archive.crawler.writer. MirrorWriterForWenwuchinaProcessor选项,在Job里添加该处理器,进行抓取后,乱码消失。(如下图)
PS:对中文资源什么的出现乱码,网络上有很多解决方案了,大家可以自己查一下,也很简单,只需改动一行代码即可。
补充:Jsp教程,Java技巧及代码