Oracle中不使用索引和使用索引的效果比较分析
Oracle中不使用索引和使用索引的效果比较分析
Oracle中测试不使用索引和使用索引的效果比较分析,啥也不用说了,有图有易做图。
1.创建测试数据库,再先批量插入数据:
SQL> create table StudentInformation(id number(20) not null primary key,
name varchar2(10) not null,
易做图 varchar2(2),address varchar2(20),hobby varchar(20));
declare
maxrecords constant int:=180000;
i int :=1009;
begin
for i in 120000..maxrecords loop
insert into STUDENTINFORMATION("ID","NAME",SEX,ADDRESS,HOBBY)
values(i,TO_CHAR('99'+i),'男','山东临沂','打篮球');
end loop;
dbms_output.put_line(' 成功录入数据! ');
commit;
end;
如此插入大量数据,修改address,和hobby得到所需数据,如下图,共95000条数据。

2.测试环节:
创建索引:SQL> CREATE INDEX index_address_hobby ON STUDENTINFOR
MATION(address,hobby);
分析表和索引:SQL>易做图yze table STUDENTINFORMATION compute statistics
for table for all indexes for all columns;
SQL> set autotrace traceonly;
SQL>set timing on;
SQL> select * from StudentInformation where hobby='打篮球';

Oracle选择了不使用索引而直接使用全表扫描,因为优化器认为全表扫描的成本
更低,我们通过增加提示(hint)来强制使用索引:
SQL> SELECT/**//*+ INDEX (StudentInformation index_address_hobby )*/ *
FROM StudentInformation WHERE hobby='打篮球';

statistics部分的逻辑读取数(consistent gets)显示,使用索引导致的逻辑读取
数是不使用索引导致的逻辑读的多近200个的逻辑读。
因此,Oracle选择了全表扫描而不是索引扫描。
测试二:再插入部分数据:

SQL> select * from StudentInformation where address='山东临沂';

测试三:再插入少量新数据:
declare
maxnumber constant int:=95020;
i int :=1;
begin
for i in 95001..maxnumber loop
insert into STUDENTINFORMATION("ID","NAME",SEX,ADDRESS,HOBBY)
values(i,TO_CHAR('99'+i),'男','山东临沂','踢足球');
end loop;
dbms_output.put_line(' 成功录入数据! ');
commit;
end;
SQL> select * from StudentInformation where hobby='踢足球';

SQL> SELECT/**//*+ INDEX (StudentInformation index_address_
hobby )*/ * FROM StudentInformation WHERE hobby='踢足球';
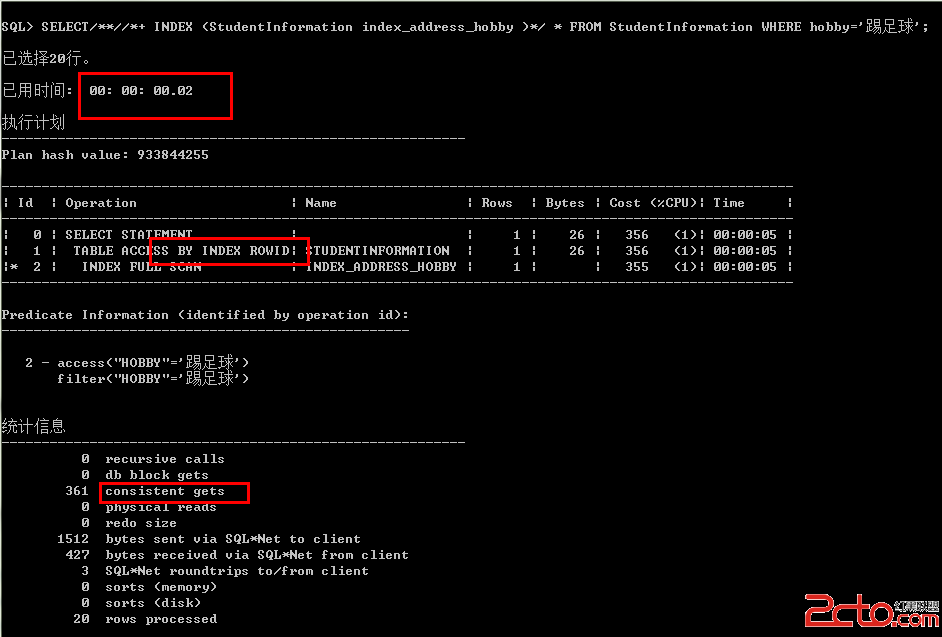
综合比较:Oracle默认为全局扫描,用时为00.23,consistent gets 502;
当强制使用索引时,用时为00.02,consistent gets 361;
说明:Oracle使用是否使用索引,有时会判断失误。
3.Oracle中影响数据存取效率的因素分析与体会。
在本次试验中,体现的Oracle中影响数据存取效率的因素为,1.数据库中
数据量的多少2.查询语句是否为最佳3.是否建立合适的索引。同时,若对Oracle
建立索引,当对Oracle数据进行查询时,Oracle本身会选择是否使用索引,
但这种选择,有时是不准确的。
此外,如果数据表第一列不能单独提供较高的选择性,复合索引将会非常有用。
Oracle中测试不使用索引和使用索引的效果比较分析,啥也不用说了,有图有易做图。
1.创建测试数据库,再先批量插入数据:
SQL> create table StudentInformation(id number(20) not null primary key,
name varchar2(10) not null,
易做图 varchar2(2),address varchar2(20),hobby varchar(20));
declare
maxrecords constant int:=180000;
i int :=1009;
begin
for i in 120000..maxrecords loop
insert into STUDENTINFORMATION("ID","NAME",SEX,ADDRESS,HOBBY)
values(i,TO_CHAR('99'+i),'男','山东临沂','打篮球');
end loop;
dbms_output.put_line(' 成功录入数据! ');
commit;
end;
如此插入大量数据,修改address,和hobby得到所需数据,如下图,共95000条数据。
2.测试环节:
创建索引:SQL> CREATE INDEX index_address_hobby ON STUDENTINFOR
MATION(address,hobby);
分析表和索引:SQL>易做图yze table STUDENTINFORMATION compute statistics
for table for all indexes for all columns;
SQL> set autotrace traceonly;
SQL>set timing on;
SQL> select * from StudentInformation where hobby='打篮球';
Oracle选择了不使用索引而直接使用全表扫描,因为优化器认为全表扫描的成本
更低,我们通过增加提示(hint)来强制使用索引:
SQL> SELECT/**//*+ INDEX (StudentInformation index_address_hobby )*/ *
FROM StudentInformation WHERE hobby='打篮球';
statistics部分的逻辑读取数(consistent gets)显示,使用索引导致的逻辑读取
数是不使用索引导致的逻辑读的多近200个的逻辑读。
因此,Oracle选择了全表扫描而不是索引扫描。
测试二:再插入部分数据:
SQL> select * from StudentInformation where address='山东临沂';
测试三:再插入少量新数据:
declare
maxnumber constant int:=95020;
i int :=1;
begin
for i in 95001..maxnumber loop
insert into STUDENTINFORMATION("ID","NAME",SEX,ADDRESS,HOBBY)
values(i,TO_CHAR('99'+i),'男','山东临沂','踢足球');
end loop;
dbms_output.put_line(' 成功录入数据! ');
commit;
end;
SQL> select * from StudentInformation where hobby='踢足球';
SQL> SELECT/**//*+ INDEX (StudentInformation index_address_
hobby )*/ * FROM StudentInformation WHERE hobby='踢足球';
综合比较:Oracle默认为全局扫描,用时为00.23,consistent gets 502;
当强制使用索引时,用时为00.02,consistent gets 361;
说明:Oracle使用是否使用索引,有时会判断失误。
3.Oracle中影响数据存取效率的因素分析与体会。
在本次试验中,体现的Oracle中影响数据存取效率的因素为,1.数据库中
数据量的多少2.查询语句是否为最佳3.是否建立合适的索引。同时,若对Oracle
建立索引,当对Oracle数据进行查询时,Oracle本身会选择是否使用索引,
但这种选择,有时是不准确的。
此外,如果数据表第一列不能单独提供较高的选择性,复合索引将会非常有用。