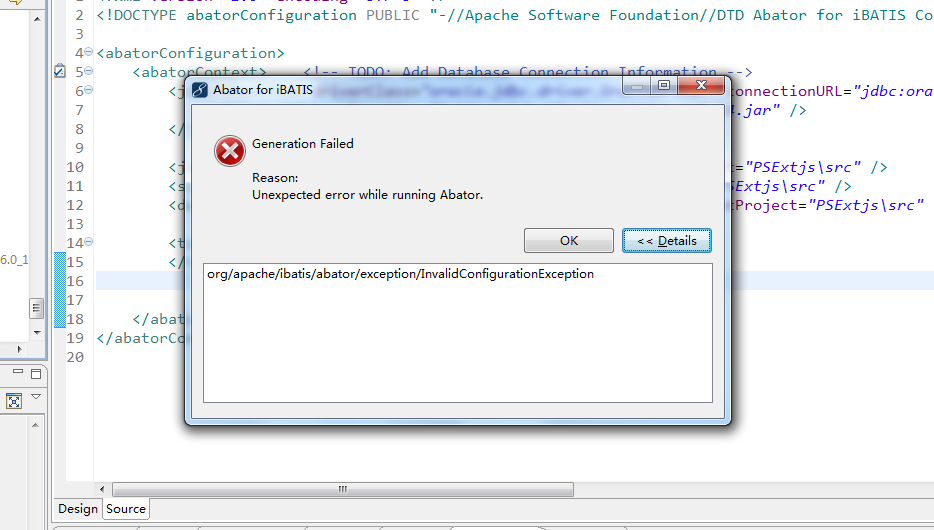
关于使用pdfbox获取pdf内容
我需要用pdfbox获取pdf中的内容--我的需求是文字部分当然页面还包含了图片,线条(把文字框起来看表格)等是一个稍微复杂的页面格式
按照
PDFTextStripper pts = new PDFTextStripper();
pts.setStartPage(1);
pts.setEndPage(1);
String result = pts.getText(document);
System.out.println("文字部分:"+result );
关键就在result那里,
如果我用简单格式的pdf获取正常,
但一用需求的那个稍微复杂的页面格式的pdf
就会报大段的java.lang.NullPointerException
然后接着
*1234567892*
u
u
u
u
u
u
这段u是什么意思?实在不懂
*1234567892*这段是条形码获取出来了
希望用过的朋友能告知 --------------------编程问答-------------------- --------------------编程问答-------------------- 没人用过吗??
补充:Java , Java EE