oracle之内存—鞭辟近里(二)
oracle之内存—鞭辟近里(二)
pga是在操作系统的进程或是线程特定的一块内存区域,它不是共享的。因为pga是进程指定的,因此它不会在sga中分配。
pga是一个内存堆,其中包含了被专用服务器或是共享服务器金曾锁需要的一些会话变量信息。服务器进程需要在pga中分配一些所需的内存结构。
一个比喻为,pga是一个临时的文件管理员的工作区域,这个文件管理员就是服务进程,她是为客户服务工作的(client process),然后文件管理员把工作区域分为很多的区域,然后来处理或是保存客户的不同信息,当这个工作完成的时候,那么相关区域的空间就会被释放掉。
如下图,显示了在专用服务器模式下所有的进程分配的pga的信息(注意background 进程也是需要分配pga的),可以使用一个初始化参数设置一个大的instance pga 值,然后每个私有的pga分别占用instance pga的一部分size:

A)pga 组件内容
pga是被划分为很多不同的区域的,每个区域都有不同的目的功能。下面是一个专用服务器模式下pga的内存分配情况,并不是所有的组件都是必须存在的。
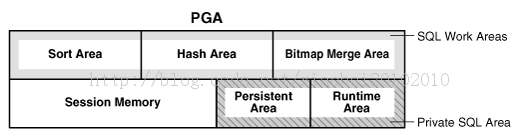
看到很多易做图把pga分成两部分,一部分为fixed area(固定区域)和variable area(可变区域),
可变区域又分为会话内存(session memory)和私有sql区(private sql area),私有sql区又分为永久区域(persistent area)和运行区域(runtime area 和sql work areas)。
我想这样分也是有意义的,先按照官网文档分发的就如上图所示了。
private sql area:
私有sql区包含一些关于sql语句解析的信息以及其他进程相关的会话信息。当一个服务进程处理sql或是pl/sql代码的时候,进程就会使用私有sql去来存储变量信息和语句查询执行状态信息以及语句执行区域信息。
private sql area 在uga中,通过使用共享sql区域来存储语句执行计划,这些在sga中分配。
1)shared sql area:
当一个sql语句第一次被执行的时候,那么数据库就会使用shared sql area 去处理折条语句,这个区域是共享的,可以被其他用户所访问,其中包含了语句的执行分析树以及执行计划。在这个区域中每个shared sql area为一个唯一的语句存在。(详细内容将在sga和shared pool中进行说明)
2)private sql area
当一个会话执行一个sql语句的时候,这个私有sql area 就会在pga中进行分配了。每个session都会有一个private sql area,如果执行同一个sql那么会指向同一个shared sql area。
eg:我执行了select * from t在一个session中执行20此和在10个不同的session执行同样这条语句,那么会共享同样的sql语句执行计划。但是private area 可能是不能够被共享的,因为其中可能存储的不同的变量值和数据。
其实我们在进行dml以及ddl操作的时候隐含的都是打开cursor,每个游标都作为客户端一边指向服务端的一条指针,每个游标打开都会分配相应的private sql area。因此在应用开发的过程中应该及时释放关闭游标,释放内存占用,以提高内存使用率。
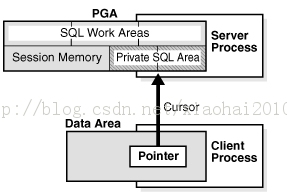
客户端进程负载管理私有sql 区域,释放和分配private sql area依据应用,但是我们可以使用open_cursor这个参数来进行控制client process 能够打开的游标数量。
这个private sql area 被分为两个区域:runtime area 和persistent area
1)runtime area
当执行一个请求的时候第一步就分配了runtime area,它包含查询执行状态信息,如我在一个全表扫描的时候,这个运行区就跟踪在检索的数目进度。当这个执行的dml sql语句结束的时候,该区域就会被释放了。
2)persistent area:
该区域包含了变量值(bind variable),这个永久区域当游标被关闭的时候内存得以释放:
eg:select * from t where name=:value;
那么value就是这个bind variable
sql work area:
该工作区在pga中被私有分配,使用与密集型操作,如我进行sort operator的时候,那么就会使用sort area 来存储sort 的行,当我进行hash join的时候,那么我就会使用hash area来存储相应的检索内容,当使用bitmap merge的时候,那么就会使用bitmap merge area 来从位图索引进行scan来合并数据。
eg:
SQL> select * from student s join class c on s.id=c.id(+) order by s.id desc;
ID NAME AGE CALSSID ID CLASSNAME
---------- -------------------- ---------- ---------- ---------- --------------------
8 h 20 2
7 g 26 3
6 f 25 1
5 e 23 3
4 d 23 1
3 c 22 1 3 3
2 b 21 2 2 2
1 a 20 1 1 1
8 rows selected.
SQL> set autotrace trace explain;
SQL> r
1* select * from student s join class c on s.id=c.id(+) order by s.id desc
Execution Plan
----------------------------------------------------------
Plan hash value: 537866712
---------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 8 | 608 | 5 (40)| 00:00:01 |
| 1 | SORT ORDER BY | | 8 | 608 | 5 (40)| 00:00:01 |
| 2 | MERGE JOIN OUTER | | 8 | 608 | 4 (25)| 00:00:01 |
| 3 | TABLE ACCESS BY INDEX ROWID| STUDENT | 8 | 408 | 1 (0)| 00:00:01 |
| 4 | INDEX FULL SCAN | PRIMARY_KEY | 8 | | 1 (0)| 00:00:01 |
|* 5 | SORT JOIN | | 3 | 75 | 3 (34)| 00:00:01 |
| 6 | TABLE ACCESS FULL | CLASS | 3 | 75 | 2 (0)| 00:00:01 |
---------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
5 - access("S"."ID"="C"."ID"(+))
filter("S"."ID"="C"."ID"(+))
Note
-----
- dynamic sampling used for this statement (level=2)
SQL>
在这个执行计划中可以看出sort order by是在sort area 中的,private sql 中的运行区域在calss表汇总执行了一个全表扫描的进度,这个会话执行了一个left join 在两个表中获取了相应数据。
当work area 工作区域很小的时候,不能够容纳锁执行语句的数据信息,那么就会把执行的数据信息划分为很多的数据piece,然后oracle缓慢的进行处理piece,其他的piece 会被暂时缓存到disk中,因此我们应该保证有足够的内存给予work area一边减小disk 的i/o,以便提高系统系能。
B)pga在共享服务器和专用服务器模式下组件的不同分配情况。
Memory Area Dedicated Server Shared Server Nature of session memory Private Shared Location of the persistent area PGA SGA Location of the run-time area for DML/DDL statements PGA PGA ++++++++++++++++++++++++++++++++++++++++++++++++↖(^ω^)↗+++++++++++++