利用第三方工具进行数据库转移—导入导出、备份还原
利用第三方工具进行数据库转移—导入导出、备份还原
前文
所谓数据库的转移,说白了就是把开发使用的数据库服务器上做好的表、数据、存储过程等复制出来,再导入到另一个服务器中。
一般来说方法有三种:
一是利用数据库自己的带参命令exp和imp进行,这种方式古老又低效,但因为其传统又官方,是老DBA彰显水平的必备手段;
二是利用第三方工具借助于数据库本身提供的功能(如Oracle的exp.exe以及imp.exe;SQL Server的Integration Service和“备份/还原”功能)进行图形化界面操作,本质上与第一种方法是一样的,但因为其操作简单方便,莫名其妙的常常被老DBA鄙视;
三是利用第三方工具为用户独创的“脚本输出/脚本执行”功能,也就是将数据库对象的CREATE文输出成SQL文件,然后利用这个SQL文件就可以随时再次创建数据库。这在PL/SQL和Object Browser中都有提供。
本文将以Object Browser为图例对后两种方法进行讲解,因为其中文界面较为简单易懂。最后再简单的交流一下关于DataPump的问题。
那么首先,我们来介绍一下Oracle的导入导出功能。说白了就是数据库对象以二进制文件(.DMP)的形式输出,之后再解析并输入到另一个数据库环境中。
Oracle导出
1,从菜单进入导出界面

2,在[选择]页中,可以指定导出的对象范围。
全数据库:数据库上所有用户的所有对象全部导出
用户指定:指定用户下的所有对象
表指定:只导出指定的表,可指定多张表
表空间指定:指定表空间下的所有对象全部导出
在文件名那一栏里输入要保存的DMP文件的全路径。也可通过浏览选择。目标对象里显示要导出的对象,可选对象里是通过你指定的导出方法列出所有可选的对象。
3,在[选项]里可以设置更多高级选项,这与oracle自身的exp所需要的参数几乎是一样的。
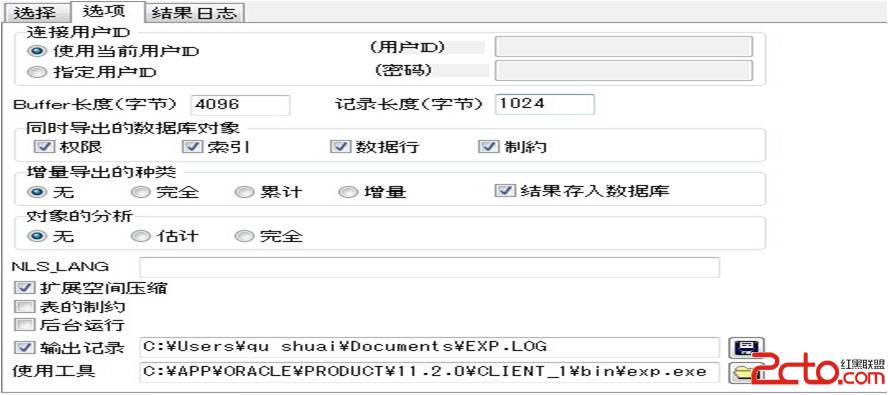
[连接用户ID]可以指定导出时使用的用户。可以指定为当前连接的用户,也可以指定其他用户。
指定其他用户的话需要输入那个用户的用户ID和密码。
[Buffer长度]和[记录长度]可设置buffer字节数和record的字节数。
一般可以使用默认的,但如果有些表里有非常多的字段,或者存储了非常大的数据(比如LOB型等),为了避免出错,需要把它调大一些。
[同时导出的数据库对象]可以指定是否同时导出权限,索引,数据,制约。数据库的转移如果只转移表结构而不包含其中数据的话,就将[数据]取消选中。
[增量导出的种类]如下:
无:导出所有对象
完全:导出所有对象
增量:只导出上一次执行导出以来发生变化的对象
累计:只导出上一次执行导出以来发生变化的对象,但是在DMP中包含了压缩过的上一次导出的DMP。
[对象的分析]可以设置在导入时生成的统计信息
无:不统计
估计:只统计一部分的样例。
完全:统计
[NLS_LANG]里可以设置导出DMP要使用的字符集编码,不添即为数据库默认。
[扩展空间压缩]选中时,在扩展空间里存储的数据被整合在导出的DMP中
[表的制约]选中时,将会在导出过程中检查数据的一致性
[后台运行]选中时,导出过程将不在界面中体现。
[输出记录]可以指定导出结果的日志保存路径
[使用工具]就是Oracle客户端自带的exp.exe
4,点击[执行]按钮。就执行导出,在[结果日志]里会显示执行的结果。
Oracle导入
导出成功之后,就会在指定目录下生成一个二进制的.DMP文件,数据库转移就是利用此文件导入到新的数据库中。首先,要连接到新的数据库中。
1, 从菜单进入导入界面

2, 在[选择]页中设置[导入方法]
全数据库:将DMP以整个数据库的形式导入
用户指定:将DMP文件中指定用户导入到当前连接数据库的指定用户中(此时点击右侧的[一览]按钮,将列出DMP中所有的用户)
表指定:只导入DMP文件中的指定的表(此时点击右侧的[一览]按钮,将列出DMP中所有的表)
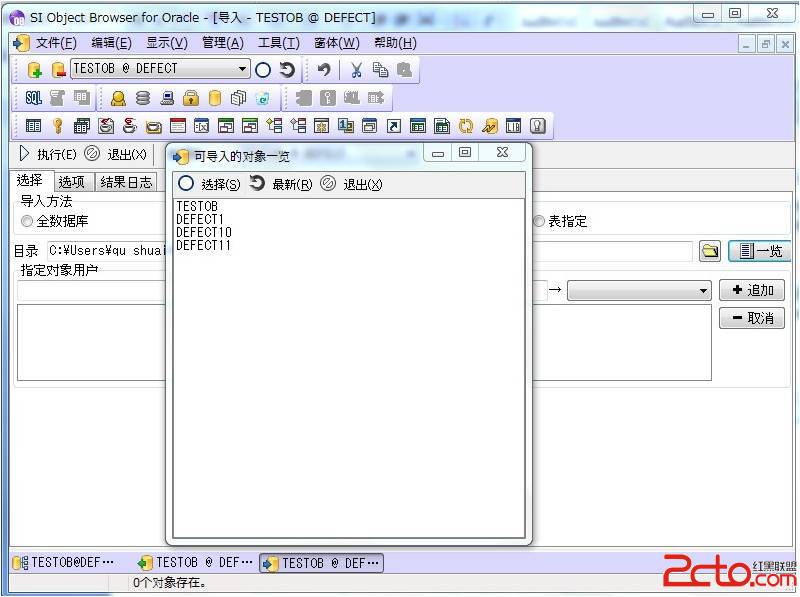
在目录中可以输入DMP文件的绝对路径,也可以通过文件浏览方式找到DMP文件。
在[选项]页中的设置项与导出时的基本一致,就不多介绍了。
3,点击[执行]按钮,开始导入。显示正常结束后就完成了数据库的导入。
脚本输出
脚本输出也是数据库备份,数据库转移的一种方法。
这里说的脚本,就是创建表,存储过程等各种数据库对象的SQL语句的.SQL(DDL)文件,当然也包括向表中插入数据的INSERT文。
任何第三方工具都可以直接查看,修改,执行这些.SQL文件,从而方便的建立起数据库。
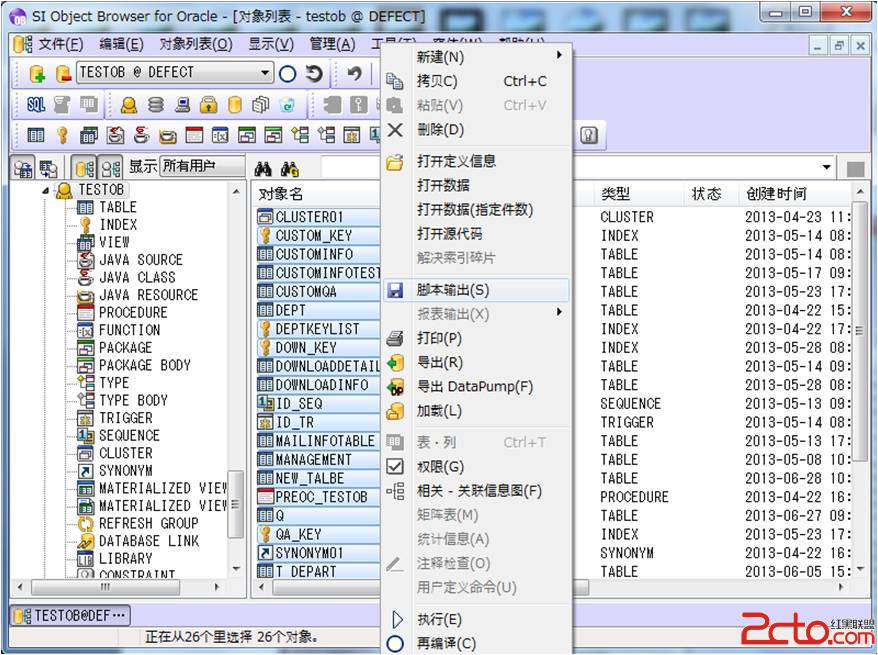
1, 在[对象列表]页面里列出了当前连接用户下所有的数据库对象,包括表、视图、存储过程、索引等等。
选中要导出的对象,右键选择[脚本输出],调出输出界面

[将同时输出的脚本汇总在一起]选中时,所有的SQL输出到一个文件中。不选中时,每个对象生成单独的SQL文件。
[创建与类型相应的子文件夹]选中时,所有Table的SQL文件将生成到Table文件夹中。所有View的SQL文件将生成到View文件夹中。
各种不同的对象类型将被归类在不同的文件夹中。
不选中时,统一生成在一个文件夹内。
[名称表]是一个很人性化的设置。它让你在数据库中建立一张表,用来表示表明与SQL脚本文件的文件名之间的匹配关系。
也就是说,生成的SQL脚本文件名可以由你按照你自己的意愿和规则自定义。
[输出SCHEMA名]可以设置是否在SQL中带上SHEMA信息。
[在输出TABLE脚本时,包含从属于该表的索引脚本]
[输出TABLE脚本时,同时输出数据(INSERT)语句]这里可以设置insert语句是附加在表的脚本文件中,还是保存在新建的“DATA”目录下,
或者另存为“表名_DATA.SQL”文件中。
[输出EXTANT信息]里可以设置脚本文件中需要包含哪些EXTENT信息。
[输出View脚本时包含项目名]设置是否在“CREATE VIEW 视图名 AS ”之后加上字段名
[输出View脚本时使用FORCE选项]设置是否在VIEW的脚本中附加FORCE设置(只限Oracle)
[输出对象权限]各脚本文件末尾,是否输出赋予对象权限的GRANT语句。
[不导出空白行]可以在导出时自动将脚本中的空行删除。
因为很多人在使用SQL*Plus执行脚本时,经常因为脚本中的空行而错误无法执行的情况。
2, 点击[开始]按钮开始导出脚本文件。

脚本已输出,看看我们的文件夹下,多么的整齐!
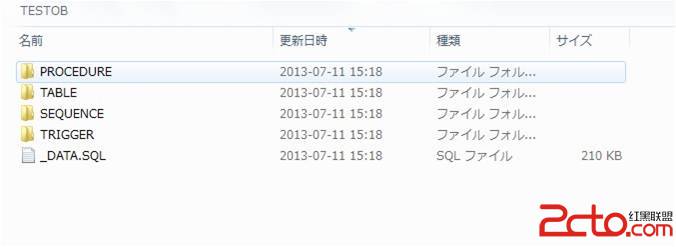
各种对象分门别类的各就各位,数据也以_DATA.SQL另存了出来。
拥有了这些脚本,就相当于拥有了整个数据库!
这些脚本可以理解为数据库的备份,而且还不是不可修改的硬备份,而是随时可以查看修改任你处置的软备份。
脚本执行
接下来,就可以通过执行这些脚本来创建新的数据库。
1, 从菜单进入[脚本执行]界面

从右侧目录中选择脚本所在文件夹或脚本文件,需要执行的脚本文件或文件夹可以整体移动到左侧,作为脚本执行对象。
2, 点击[执行]按钮,在确认对话框中可以设置是否在执行后删除该脚本文件,是否在发生错误时中断处理。

这里特殊说一下,
在执行就很多脚本文件的时候经常因为错误而中断,绝大多数都是因为执行顺序的原因。
比如在创建VIEW的时候,他参照的TABLE还没有被创建,就会出错误。
这种情况下,我们选中[将正确完成的SCRIPT从列表中删除]的话,就可以反复执行,直到列表被清空时就说明所有脚本都被正确执行了。



CopyRight © 2022 站长资源库 编程知识问答 zzzyk.com All Rights Reserved
部分文章来自网络,
部分文章来自网络,