RabbitMQ集群方案
RabbitMQ虽然是天生的分布式消息队列,但其本身并不支持负载均衡。
Connecting to Clusters from Clients
A client can connect as normal to any node within a cluster. If that node should fail, and the rest of the cluster survives, then the client should notice the closed connection, and should be able to reconnect to some surviving member of the cluster. Generally, it's not advisable to bake in node hostnames or IP addresses into client applications: this introduces inflexibility and will require client applications to be edited, recompiled and redeployed should the configuration of the cluster change or the number of nodes in the cluster change. Instead, we recommend a more abstracted approach: this could be a dynamic DNS service which has a very short TTL configuration, or a plain TCP load balancer, or some sort of mobile IP achieved with pacemaker or similar technologies. In general, this aspect of managing the connection to nodes within a cluster is beyond the scope of RabbitMQ itself, and we recommend the use of other technologies designed specifically to solve these problems.
正如官方所说,该问题超出了RabbitMQ本身的范畴,建议采用专门技术去解决。
不像传统的Web应用前面挂上反向代理那样简单,由于它属于中间件,后端还要从中取数据,所以场景会复杂些。
其实我觉得单就publisher这一层面来说,其实是可以采用直接挂反向代理的解决方案,尤其是对于短连接的Web应用端。对于consumer层面来说,一般情况下就不适合采用同样的方式(除非采用了镜像队列)。
这些都和RabbitMQ的队列模式有关:
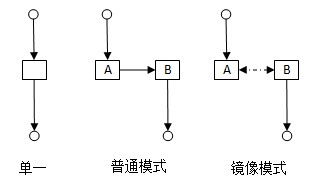
为直观起见,流程简化为单链接,中间为RabbitMQ节点,上方为publisher,下方为consumer。
单一模式:最简单的情况,非集群模式。
没什么好说的。
普通模式:默认的集群模式。
对于Queue来说,消息实体只存在于其中一个节点,A、B两个节点仅有相同的元数据,即队列结构。
当消息进入A节点的Queue中后,consumer从B节点拉取时,RabbitMQ会临时在A、B间进行消息传输,把A中的消息实体取出并经过B发送给consumer。
所以consumer应尽量连接每一个节点,从中取消息。即对于同一个逻辑队列,要在多个节点建立物理Queue。否则无论consumer连A或B,出口总在A,会产生瓶颈。
该模式存在一个问题就是当A节点故障后,B节点无法取到A节点中还未消费的消息实体。
如果做了消息持久化,那么得等A节点恢复,然后才可被消费;如果没有持久化的话,然后就没有然后了……
镜像模式:把需要的队列做成镜像队列,存在于多个节点,属于RabbitMQ的HA方案。
该模式解决了上述问题,其实质和普通模式不同之处在于,消息实体会主动在镜像节点间同步,而不是在consumer取数据时临时拉取。
该模式带来的副作用也很明显,除了降低系统性能外,如果镜像队列数量过多,加之大量的消息进入,集群内部的网络带宽将会被这种同步通讯大大消耗掉。
所以在对可靠性要求较高的场合中适用。
淘宝DBA们给出的方案略显复杂,根据我们目前的场景(两个节点)和针对Web形式publisher的实际情况,我设想的集群方案如下:
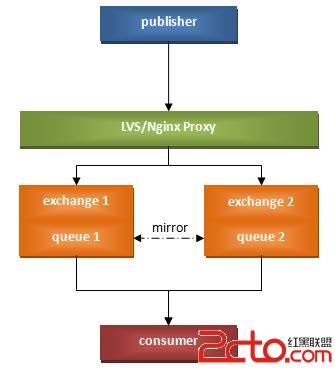
consumer基于Python实现,守护方式运行,通过异步非阻塞方式同时链接并监听两个节点中的两个物理Queue(同一逻辑队列),消费消息;
Web业务层的publisher直接通过反向代理链接任意一台可用的节点,写入消息;
具体队列根据需要选择是否建立成镜像模式。
不过该模式有一个不足之处就是反向代理层的单点问题。
如果能把节点选择逻辑转移到publisher所在的应用层,那么就能完全消除单点了。
经测试,对于节点IP通,但端口不通的情况,client是能做到迅速反馈,从而可以主动选择另一个节点进行重连;
但对于IP不通的情况,则会3秒的链接时间,超时后才会反馈,由于web应用的及时性,so。。。此方案不可行。
还有一山寨方法:第一次链接超时时,程序动态修改配置文件,使此后的应用均访问另一有效节点。此法过于山寨,不建议大范围应用。。。
作者:linvo
补充:综合编程 , 其他综合 ,