Replicated Join
Pattern Description
复制join是一种特殊的join,用于一个大数据和许多小数据集map端执行的情况。
Intent
这种模式能够消除reduce阶段的shuffle。
Motivation
复制join非常有用,除了一个大数据集外,对其它要join的数据集有严格的大小限制。除了这个大数据集外,其它数据在map任务的setup阶段都要进内存,会受到jvm 堆大小的限制。如果能适应这种限制,就能得到大大的好处,因为不存在reduce阶段,因此没有混洗和排序。在map阶段就能完成整个join,这是一个非常大的数据作为输入的job。
当然对复制join来说,也有额外的限制:只对内连接或左外连接当左边的数据很大时有用。其它模式都需要reduce阶段用左边整个数据集分组右边的数据集。虽然一个map任务可能不会匹配内存里的数据,但另一个map可能会匹配。因为这个原因,我们限制这种模式用于内连接和左外连接。
Applicability
在以下情况可使用:
·内连接或作为连接,左边的数据非常大。
·除了一个大数据集,其它数据都能放进物理内存。
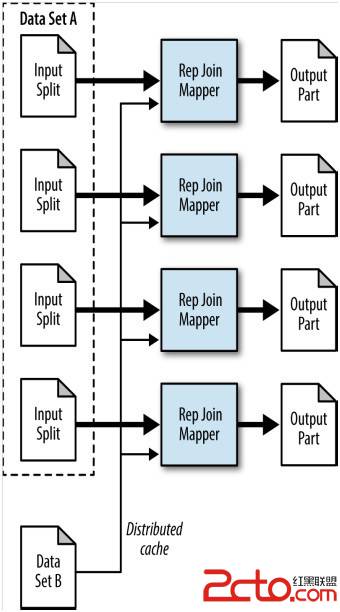
Structure
·mapper负责在setup阶段从分布式缓存读所有的文件并排序成内存查询表。Setup阶段完成后,mapper执行join操作。如果外键没找到,这条记录或者忽略或者输出,分别对应两种join类型。
·只有map。
Consequences
输出的各个部分文件的数量等于map 任务个数。如果是左外连接,可能存在null值。
Resemblances
Pig
Pig对这种模式有原生支持,通过对标准join做一些简单的修改。基于相同的原因,也只支持内连接和左外连接。注意代码的先后顺序:
huge = LOAD 'huge_data' AS (h1,h2);
smallest = LOAD 'smallest_data' AS (ss1,ss2);
small = LOAD 'small_data' AS (s1,s2);
A = JOIN huge BY h1, small BY s1, smallest BY ss1 USING 'replicated';
Figure 5-2. The structure of the replicated join pattern
Performance analysis
复制join是最快的join类型,因为没有reducer,但也会有一些代价。有能安全的存储在jvm里的数据量的限制,取决于能给map分配多少内存。用这种模式之前应该检测下你的环境能放多少数据到内存。注意这里的内存指的是物理内存。使用了java对象,数据会变大。幸运的是,你可以忽略你不需要的数据。
Replicated Join Examples
Replicated user comment example
这个例子跟前面用bloom filter做join的例子有紧密的关系。分布式缓存用来把文件推送到所有的map 任务端。不像bloom filter那样,这里把数据本身读入内存,并只有map阶段的join。
问题:给出少量的用户信息数据和一个大的评论数据,用用户数据丰富评论数据。
Mapper code。Setup阶段,从分布式缓存读用户数据并存进内存。解析记录,userid 和记录放入HashMap。这里可能出现OOM错误,因为存储了数据及结构。如果错误发生了,就增大jvm 大小或使用reduce 端join。
Setup之后,执行map方法。从评论数据获取user id,用它从setup阶段构建的hashmap中获取值。找到就输出,找不到,视join类型而做相应的处理。这就是全部了。
publicstaticclass ReplicatedJoinMapper extends
Mapper<Object, Text, Text, Text> {
privatestaticfinal Text EMPTY_TEXT = new Text("");
private HashMap<String, String> userIdToInfo = new HashMap<String, String>();
private Text outvalue = new Text();
private String joinType = null;
publicvoid setup(Context context) throws IOException,
InterruptedException {
Path[] files = DistributedCache.getLocalCacheFiles(context
.getConfiguration());
// Read all files in the DistributedCache
for (Path p : files) {
BufferedReader rdr = new BufferedReader(new InputStreamReader(
new GZIPInputStream(new FileInputStream(new File(
p.toString())))));
String line = null;
// For each record in the user file
while ((line = rdr.readLine()) != null) {
// Get the user ID for this record
Map<String, String> parsed = transformXmlToMap(line);
String userId = parsed.get("Id");
// Map the user ID to the record
userIdToInfo.put(userId, line);
}
}
// Get the join type from the configuration
joinType = context.getConfiguration().get("join.type");
}
publicvoid map(Object key, Text value, Context context)
throws IOException, InterruptedException {
Map<String, String> parsed = transformXmlToMap(value.toString());
String userId = parsed.get("UserId");
String userInformation = userIdToInfo.get(userId);
// If the user information is not null, then output
if (userInformation != null) {
outvalue.set(userInformation);
context.write(value, outvalue);
} elseif (joinType.equalsIgnoreCase("leftouter")) {
// If we are doing a left outer join,
// output the record with an empty value
context.write(value, EMPTY_TEXT);
}
}
}
Composite Join
Pattern Description
复合join是一种特殊的join操作用来执行map端的很多大数据集的join。
Intent
这种模式能消除reduce阶段的混洗和排序。然而,需要输入数据已被组织好,或准备成一种指定的格式。
Motivation
复合join在做多个很大数据的join时特别有用。要求数据满足条件:按外键排序,分区,用特殊的方式读数据。就是说,你的数据能用这种方式读,或你能准备成这种方式,复合join能起到很大的作用,跟其他类型相比。
Hadoop本身有CompositeInputFormat 类支持复合join。这种模式的限制类型为:内连接和全外连接。Mapper的输入必须用指定的方式分区和排序,并且每个输入数据集必须分成相同数量的分区。另外,相同的外键必须在两个数据集相同的分区。这通常发生在几个job有相同的reducer个数并输出键也相同,并且输出文件时不能分割的。例如,比hdfs的block小或是一种不支持split的压缩格式。也许本章中其它模式可能更适用。如果你发现用复合join之前必须格式化数据。你最好使用reduce端join除非这个输出用于很多分析。
Applicability
使用条件:
·内连接或全外连接。
·所有数据集都非常大。
·所有数据集都能把外键作为mapper的输入key。
·所有数据集有相同数量的分区。
·每个分区都根据外键排序,所有的外键都位于每个数据集响应的分区。就是说,数据集a和b的分区x包含相同的
补充:综合编程 , 其他综合 ,