当前位置:编程学习 > php >>
答案:看代码:复制代码 代码如下:
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<title> New Document </title>
<meta name="author" content=""/>
<meta name="keywords" content=""/>
<meta name="description" content=""/>
<link rel="stylesheet" type="text/css" href=></head>
<body>
<?php
$string1 = "i am a phper";
$string2 = "这网站是脚本之家";
print_r(str_split($string1));
echo "<br />";
print_r(str_split($string2,4));
?>
</body>
</html>
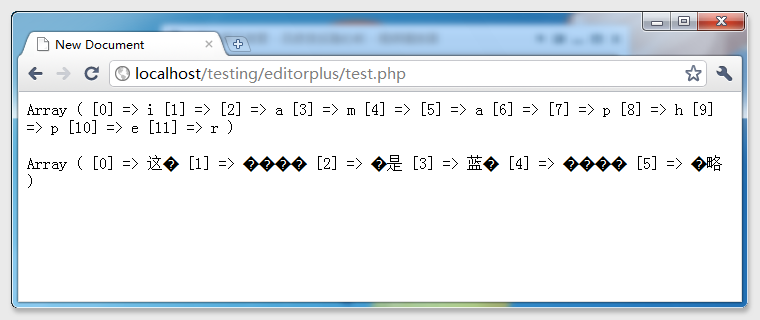
测试结果打出我所料——中文乱码
Why?Why?Why?Why?乱码是什么?什么事乱码?给我解释解释,什么,是%&的乱码!
因为英文无乱码,只有中文乱码,首先想到了编码的问题,于是突然想起来UTF-8的编码是UTF-8需要3个字节,死马当活马医吧!
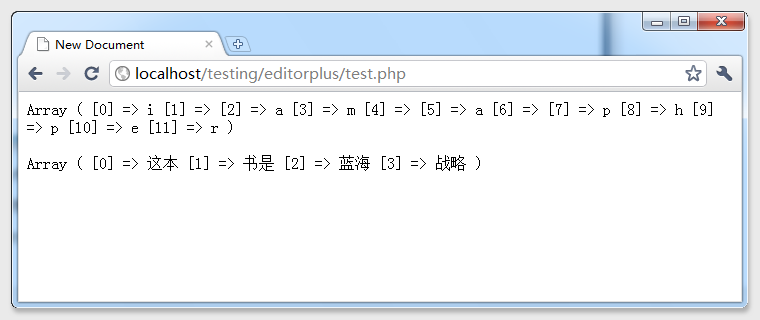
于是 print_r(str_split($string2,4));这句中的4 ,就被换成了6,于是乎——看结果
同样,你也可以试试将编码的charset的UTF-8改成GB2312,因为Unicode的编码是需要2字节的,所以说Gb2312的编码比UTF-8能够节约1/3的空间,但是如果你要兼容繁体中文、韩文、日文的其他的语言就需要使用UTF-8了。
上一个:php中转义mysql语句的实现代码
下一个:php中session_unset与session_destroy的区别分析


- 更多php疑问解答:
- php使用imagick将image图片转化为字符串模式
- php通过gd实现图片图片转换为字符图代码
- PHP把图片转base64代码,php把base64代码转换为图片并保存
- PHP把图片base64转换成图片并保存成文件
- wordpress问题<?php if(have_posts()) : ?>
- 建设一个搜索类网站php还是jsp,数据库那个好
- 没理由啊 php代码无法执行,貌似有语法错误。。。
- 关于PHP 和API 的一段代码不懂啊不懂,请高手指点! 这是淘宝API的
- php语言中,序列化到底在那里使用?它的优势是什么?劣势是什么?
- PHP函数等于或等于应该怎么表达
- 请教php高手,解决basename函数和mb_substr函数处理中文文件名称的解决方法,在上传文件时,总是出现乱码
- .NET,PHP,JAVA,JS优秀点分别是?
- 织梦cms 在环境监测的时候 wamp5 gd不支持 是为什么。;extension=php_gd2.dll这一句我删除了还是不显示?
- 我想学PHP。1.应安装什么编程工具? 2. 装LIUNX系统是装简易的还是?什么版本的?3.还应安装什么?
- <?php 和 <? 有什么区别