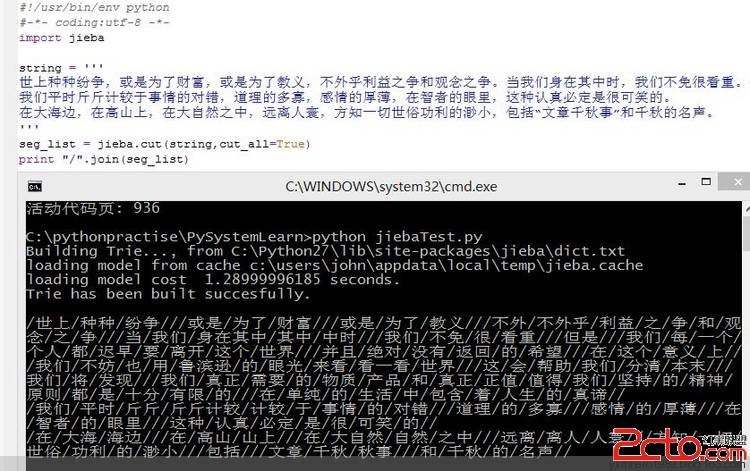
分享 python 中re模块的re.compile()方法
re模块中有re.match、re.serch、re.findall,也是最常用的,详细用法见链接re.compile()是用来优化正则的,它将正则表达式转化为对象,re.search(pattern, string)的调用方式就转换为 pattern.search(string)的调用方式,多次调用一个正则表达式就重复利用这个正则对象,可以实现更有效率的匹配
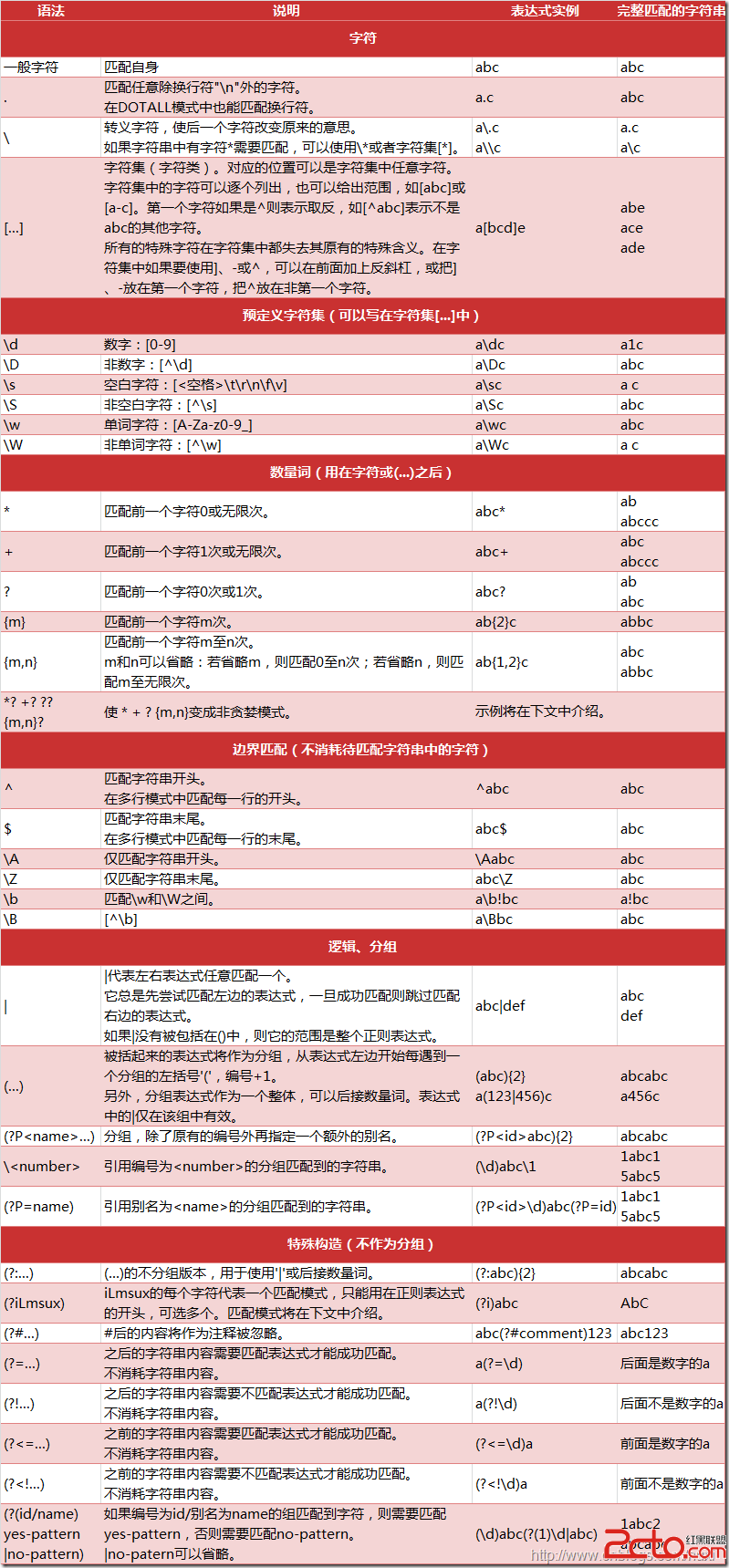
re.compile()语法格式如下:
compile(pattern[,flags] )
通过python的help函数查看compile含义:
compile(pattern, flags=0)
pattern : 一个字符串形式的正则表达式
flags : 可选,表示匹配模式,比如忽略大小写,多行模式等,具体参数为:
1).re.I(re.IGNORECASE): 忽略大小写
2).re.M(MULTILINE): 多行模式,改变'^'和'$'的行为
3).re.S(DOTALL): 点任意匹配模式,改变'.'的行为
4).re.L(LOCALE): 使预定字符类 \w \W \b \B \s \S 取决于当前区域设定
5).re.U(UNICODE): 使预定字符类 \w \W \b \B \s \S \d \D 取决于unicode定义的字符属性
6).re.X(VERBOSE): 详细模式。这个模式下正则表达式可以是多行,忽略空白字符,并可以加入注释
举例:正则表达式为三个”号引起来的多行字符串,则将匹配模式设置为re.X 可以多行匹配
pattern1 = re.compile(r”“”\d + #整数部分
. #小数点
\d * #小数部分”“”, re.X)
二、re.compile()简介
re.compile()生成的是正则对象,单独使用没有任何意义,需要和findall(), search(), match()搭配使用2.1 结合findall(),返回一个列表
import re
content = 'Hello, I am Jerry, from Chongqing, a montain city, nice to meet you……'
reg = re.compile('\w*o\w*')
x = reg.findall(content)
print(x) # ['Hello', 'from', 'Chongqing', 'montain', 'to', 'you']
2.1 结合match()
import re
reg = re.compile(r'^@.*? RPA\[([0-9a-f]+)\]')
msg = '@www.pu RPA[7886481]: 收到录单任务,手机:1580vvvv18950。任务处理中,请稍候。'
mtch = reg.match(msg)
print(mtch) # <re.Match object; span=(0, 20), match='@www.pu RPA[7886481]'>
print(mtch.group()) #@www.pu RPA[7886481]
print(mtch.group(1)) # 7886481 # 分组内内容
print(mtch.start(1)) # 12
print(mtch.end(1)) # 19
print(mtch.span(1)) #(12, 19) # 分组内的元素范围
print(mtch.span()) #(0, 20)
2.2 结合search()
import re
content = 'Hell, I am Jerry, from Chongqing, a montain city, nice to meet you……'
regex = re.compile('\w*o\w*')
z = regex.search(content)
print(z) # <re.Match object; span=(18, 22), match='from'>
print(z.group()) # from
print(z.span()) #(18, 22)