Python抓取百度音乐

Title:Python抓取百度音乐
Author:Insun
Content:
可以根据歌手名称来搜他的音乐
譬如搜陈奕迅 有1161首歌曲
http://music.baidu.com/search?key=%E9%99%88%E5%A5%95%E8%BF%85key后面的query需要quote一下 urlencode。
正则匹配一个页面上所有的歌名,一个分页20个。(这里就没去抓其他分页了)
然后根据一个百度音乐老接口API ,现在的音乐盒域名是play.baidu.com
http://box.zhangmen.baidu.com/x?op=12&count=1&title=爱情转移$$陈奕迅$$
<count>5</count>
<url>
<encode>
http://zhangmen易做图ing.baidu.com/data2/music/33936634
/ZGVsZ2tsamxfn6NndK6ap5WXcGeba5lsZ2qXmGlunZ1ilmqVmGuammFjlWxsamtrYmeWWqKfm3VhYGhqamxsaWFlZ2RtanBuMQ$$
</encode>
<decode>33936634.mp3?xcode=3f5b468dd48fe1d7ac5cb01b8744315c&mid=0.56565103408496
</decode>
<type>8</type>
<lrcid>2399</lrcid>
<flag>1</flag>
</url>
XML文件 count是说有5个可以下载的资源
我们直接取第一个
encode加密的链接是
http://zhangmen易做图ing.baidu.com/data2/music/33936634
/ZGVsZ2tsamxfn6NndK6ap5WXcGeba5lsZ2qXmGlunZ1ilmqVmGuammFjlWxsamtrYmeWWqKfm3VhYGhqamxsaWFlZ2RtanBuMQ$$
红色部分就是下面decode的内容
<decode>33936634.mp3?xcode=3f5b468dd48fe1d7ac5cb01b8744315c&mid=0.56565103408496
</decode>
我们python字符串处理一下 根据最后一个“/"来截取 最后拼凑成
http://zhangmen易做图ing.baidu.com/data2/music/33936634/
33936634.mp3?xcode=3f5b468dd48fe1d7ac5cb01b8744315c&mid=0.56565103408496
<?xml version="1.0" encoding="gb2312" ?>
<result><count>5</count><url>
<encode>
<![CDATA[http://zhangmen易做图ing.baidu.com/data2/music/33936634/
ZGVsZ2tsamxfn6NndK6ap5WXcGeba5lsZ2qXmGlunZ1ilmqVmGuammFjlWxsamtrYmeWWqKfm3VhYGhqamxsaWFlZ2RtanBuMQ$$]]>
</encode>
<decode>
<![CDATA[33936634.mp3?xcode=3f5b468dd48fe1d7ac5cb01b8744315c&mid=0.56565103408496]]>
</decode><type>8</type><lrcid>2399</lrcid><flag>1</flag></url>
<durl>
<encode>
<![CDATA[http://zhangmen易做图ing2.baidu.com/data2/music/1802507/
YmpjZmpmbmaeomZzrZmmnJZvZppqmGtuaZaXaG2cnGmVaZSXapmZaGKUa2tpamppZpVZoZ6adGhfZ2lpa2toaGRmY2xpb204]]>
</encode><decode><![CDATA[1802507.mp3?xcode=3f5b468dd48fe1d7ac5cb01b8744315c&mid=0.56565103408496]]>
</decode><type>8</type><lrcid>2399</lrcid><flag>1</flag></durl>
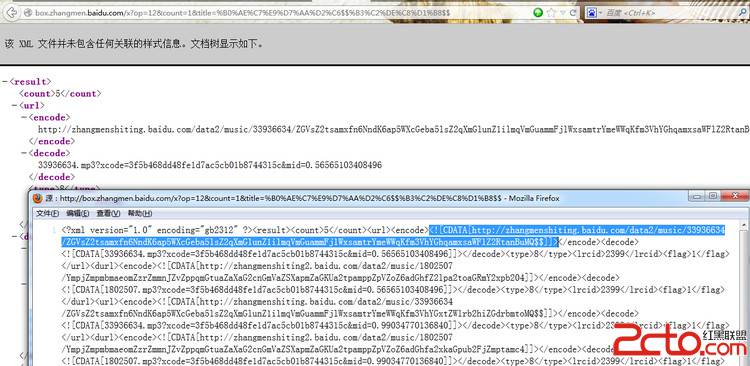
源代码里是有CDATA的 所有正则时候要处理一下
type是类型 是mp3呢还是wma呢还是rm呢。。等等。。
lrcid 是个取整的算法 除以一百,然后取小于等于其结果的最大整数 2399/100 = 23
即 http://box.zhangmen.baidu.com/bdlrc/23/2399.lrc
然后分songs和lrcs目录下载下来
#!/usr/bin/env python
#! -*- encoding:utf-8 -*-
'''
根据歌手去找歌曲 一页20首歌
然后根据歌名和歌手来下载歌曲和歌词
20首歌和歌词 接近1M/s的网速 花了33.9479383463s
author:insun
'''
import urllib,re,sys,os,time
reload(sys)
sys.setdefaultencoding('utf-8')
def musicScapy(singername):
query = urllib.quote(singername)
url = 'http://music.baidu.com/search?key='+query
response = urllib.urlopen(url)
text = response.read()
#<span class="song-title" style="width: 170px;" ><a href="/song/7316463" class="" data-songdata='{ "id": "" }' title="爱情转移">爱情转移</a>
reg = re.compile(r'<span class="song-title".+?>.+?<a.+?>(.*?)</a>',re.S)
groups = re.findall(reg,text)
'''判断目录songs和lrcs是否存在,不存在创建。否则报错'''
if (os.path.exists('songs')== False):
os.mkdir('songs')
if(os.path.exists('lrcs') == False):
os.mkdir('lrcs')
for musicname in groups:
try:
xml = urllib.urlopen('http://box.zhangmen.baidu.com/x?op=12&count=1&title='
+ musicname+'$$'+singername +'$$').read()
encode = re.compile('<encode>.*?CDATA\[(.*?)\]].*?</encode>',re.S).findall(xml)[0]
decode = re.compile('<decode>.*?CDATA\[(.*?)\]].*?</decode>',re.S).findall(xml)[0]
lrcid = re.compile('<lrcid>(.*?)</lrcid>',re.S).findall(xml)[0]
#encode.rindex('/') 最后出现'/'的位置
musicname = musicname.decode('utf-8')
musiclink = encode[:encode.rindex('/')+1] + decode
lrclink = 'http://box.zhangmen.baidu.com/bdlrc/'+str(int(lrcid)/100)+'/'+lrcid+'.lrc'
#song download
urllib.urlretrieve(musiclink,'songs/'+ musicname+'.mp3')
#lrc download
urllib.urlretrieve(lrclink,'lrcs/'+ musicname+'.lrc')
except BaseException:
print 'download failed'
&
补充:Web开发 , Python ,上一个:python操作MySQL数据库源码实例
下一个:python查看可用模块




- 更多python疑问解答:
- python 把图片转换成base64代码 python 把base64代码转换成图片
- 利用python进行网络图片下载 python批量下载远程图片
- 记录Python读写文件的代码和方法
- Python如何把图片转为Base64字符串
- python用requests.get批量下载网络远程图片的代码
- 疑难杂症,关于python与C#输出重定向
- 最近写的一个软件,对照下c#,c++,DELPHI,VB,易语言,PYTHON,PHP等执行效率
- 利用C#4.0调用IronPython脚本
- bat 执行定时python 打开url 谁搞过,帮忙看一下语句有什么问题
- 求助!在线等!python调用C#的.dll库
- Python 快速界面开发?求IDE和资料..中文的最好
- python如何读取XML文件中的
- .NET运行IronPython脚本错误
- 新手之前对编程无概念现在想转这行,想尽快入门,java ,python,.net、php、C之间如
- 新手之前对编程无概念现在想转这行,想尽快入门,java ,python,.net、php、C之间如